「ランバード効果と聴覚障害への役立ち方」
Understanding the Lombard Effect and its relevance to hearing impairment
要約: ロンバード効果は、音声変換およびテキスト読み上げに応用することで、ノイズ環境下で合成音声をより理解しやすくすることができます。
騒々しい部屋ではなぜ大きな声で話す傾向にあるのか、気になったことはありますか?実は、音声と言語の研究者も同様に興味を持ち、Étienne Lombardによって発見された「ロンバード効果」という概念を探求してきました。
💬 ロンバード効果の要点
音楽が流れ、みんなが話して笑っているパーティーにいる自分を思い描いてみてください。楽しい時間です!友人に自分の声を届けるため、脳は自動的に声の音量を上げ、ピッチを調整し、さらに話す速さを変えるでしょう。面白いことに、私たちは相手や周囲のノイズからのフィードバックに応じて自分の声を適応させ、メッセージが伝わるようにします。
さて、この効果をテキスト読み上げ(TTS)システムのような技術に適用した場合はどうでしょうか?AlexaやGoogle Homeがロンバード効果で話すことができるとしたらどうでしょうか?(SNLで既に想像されたシナリオです)。
🔊 ロンバード効果とテキスト読み上げ
いくつかの研究([1]、[2]を参照)では、ロンバードスタイルをテキスト読み上げに適用して、理解しやすさを向上させる方法を探求しました。彼らの目標は、ロンバードスタイルの録音でトレーニングし、理解しやすさと自然さを改善できるかどうかを確認することでした。その結果、信号処理よりも理解しやすさを向上させるより自然な方法であることがわかりました!
▴ なぜこれが重要か
単に音量を増やしたり、受信側で信号処理を行うだけではなく、音声を明瞭にすることができるのです!
補聴器は素晴らしいエンジニアリングの成果ですが、課題もあります。常に快適ではなく、費用がかかり、一部の人々は定期的に使用しないことさえあります。しかし、ロンバードスタイルのTTSを使用すると、音声は自動的に調整され、より明瞭で理解しやすくなります。これは、補聴器を使用している人だけでなく、非母国語話者([3]を参照)や騒々しい環境下の全員にとって、ゲームチェンジャーとなる可能性があります!
🚩 現在の問題
先述の研究では、特定の声に対して多くのオーディオサンプルが含まれるデータセットを使用しました。それがない場合はどうなるのでしょうか?ボイスタレントのための録音を行わずに、ロンバードスタイルで音声を合成する方法はありますか(疲れや時間がかかり、コストがかかる)?
🔍 解決策はあるのか?
声の変換、つまり他の人の話し方の録音に誰かの声を移すプロセスは、データ拡張の手法として適用できます。アイデアは、ロンバードスピーチ録音の中に話者のアイデンティティを移し、その人の声でロンバードスタイルの録音を作成することです。
📚 当研究
私たちは最近、Interspeech 23’のClarity Workshopで発表した論文で、声の変換を行う際にロンバード効果をどのように保存できるかを調査することにしました。実際、ターゲットスピーカーの情報がロンバード効果の特性を上回り、期待した結果を得られない可能性があります。以下のグラフィックスでは、実験で試した3つのシステムを見つけることができます。
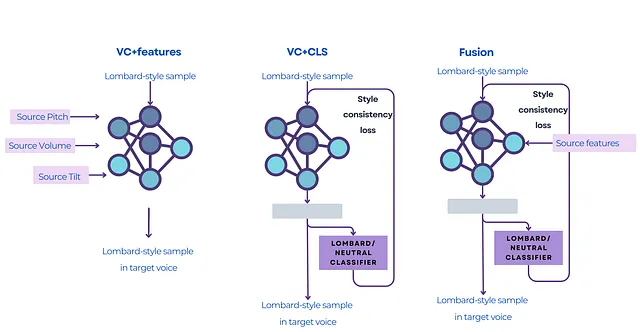
- VC+特徴(明示的な条件付け):まず、声の3つの要素であるピッチ、音量、チルトを分離しました。それらの抽出された特徴をモデルのエンコーダに直接与えます。そして、ロンバード録音でそれらを抽出し、ボイスコンバージョンモデルに与えることで、最終的な録音にそれらを保持するように強制します。同時に、移したい声も転送します。
- VC+CLS(暗黙の条件付け):モデル自体が特徴を学ぶことを望む場合はどうでしょうか?これをテストするために、モデルにソースのスタイルをボイスコンバージョン後も保持させるスタイル分類器を追加しました。この設定は、私たちが特徴を細かく指定することなくロンバードスタイルを保存するのに役立ちます。
- 融合:このシステムは、慎重に選択された特徴と分類器によって、元の話し方のスタイルを保持する両方の要素を組み合わせています。
私たちは何を見つけたのか? 下記のバープロットに示されるように、大きな雑音の中での理解可能性を示していますが、私たちは次のことを見つけました。
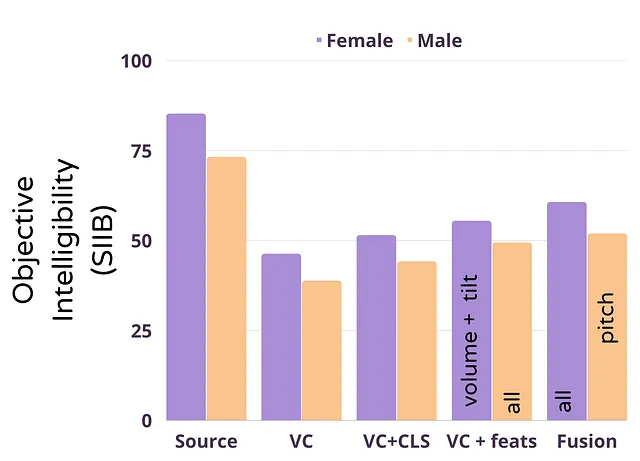
- 実際には、ランバード効果は変換中に失われます
- 明示的および暗黙の条件付けが最終的な理解可能性の向上に役立ちます
- 融合はさらに良い結果をもたらしますが、対象話者の情報が失われるため、それほど有用ではありません
- 異なる特徴が女性の声と男性の声に対してより良い結果をもたらしました
👉 結論は何ですか?
過去の研究と私たちの研究によれば、ランバードスタイルの音声合成は実際には騒々しい環境での音声の理解可能性を向上させます。自然さはやや損なわれるかもしれませんが、騒音の中ではそれほど目立たず、話者のアイデンティティにも影響を与えません。私たちの研究では、基本的な音声変換ではランバード効果が失われますが、暗黙的または明示的な条件付けを使用することで、より良い転送が可能となりました!
詳細はこちらの論文をご覧ください!
🚀 理解可能な音声の未来
音声合成が私たちの自然な調整を模倣し、騒々しい場所でコミュニケーションをスムーズにする世界を想像してみてください。さらなる研究とイノベーションにより、ランバードスタイルの音声合成は聴覚障害を持つ人々の日常活動(音楽の聴取、YouTubeビデオの視聴、映画の視聴など)に役立ち、スマートアシスタントや音声認識デバイスとの対話を改善することができるでしょう!
参考文献
– [1] Bollepalli, Bajibabu, et al. 「長短期記憶再帰ニューラルネットワークを使用した音声合成のノーマルからランバードへの適応」。Speech Communication 110 (2019)
– [2] Paul, Dipjyoti, et al. 「スピーキングスタイル変換を使用したテキストから音声への合成による音声の理解可能性の向上」。Proc. Interspeech (2020)
– [3] Marcoux, Katherine, et al. 「ネイティブおよび非ネイティブの話者に対するネイティブおよび非ネイティブの音声によるランバードの理解可能性の利益」。Speech Communication 136 (2022)
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






