「機械学習アルゴリズムの理解:詳細な概要」
Understanding Machine Learning Algorithms Detailed Overview

機械学習。かなり印象的な言葉の塊ですね。AIやそのツール(ChatGPTやBardなど)が今大いに盛り上がっているため、より深く学び、基礎を身につける時が来ました。
これらの基本的な概念は一度に理解されるわけではありませんが、もしあなたがこれらの概念に興味があるなら、さらに深く学ぶためのリンクがあります。
機械学習の強みは、その複雑なアルゴリズムにあります。これらのアルゴリズムは、機械学習プロジェクトの核となるものです。時には、これらのアルゴリズムは音声認識や顔認識など、人間の認知からインスピレーションを得ることさえあります。
- 「洞察を求める詩的な探求としてのインディゴスによる機械学習」
- 「ファイングレインド画像分類における背景誘発バイアスをどのように軽減できるか? マスキング戦略とモデルアーキテクチャの比較的研究」
- 「T2I-Adapter-SDXL:小型で効率的な制御モデルに出会ってください」
この記事では、まず教師付き学習、教師なし学習、強化学習など、機械学習のクラスについて説明します。
その後、分類、回帰、クラスタリングといった、機械学習が扱うタスクについて詳しく説明します。
その後、決定木、サポートベクターマシン、最近傍法、線形回帰などを視覚的に、定義付けながら詳しく探求します。
しかしもちろん、どのアルゴリズムがあなたのニーズに合った最良のものなのかを選ぶことができるでしょうか?もちろん、「データの理解」や「問題の定義」などの概念を理解することで、プロジェクトにおける潜在的な課題や障害に対処するためのガイドとなります。
さあ、機械学習の旅を始めましょう!
機械学習のカテゴリー
機械学習を探求すると、そのフレームワークを形作る3つの主要なカテゴリーがあることがわかります。
- 教師付き学習
- 教師なし学習
- 強化学習
教師付き学習では、予測したいラベルがデータセットに含まれています。
このシナリオでは、アルゴリズムは慎重な学習者のように振る舞い、特徴と対応する出力を関連付けます。学習フェーズが終了した後、新しいデータやテストデータに対して出力を予測することができます。スパムメールのタグ付けや家の価格の予測などのシナリオを考えてみてください。
次に、メンターなしで勉強することを想像してみてください。それは恐ろしいことでしょう。教師なし学習の方法は特にこれを行い、ラベルのない予測を行います。
彼らは無知に飛び込み、ラベルのないデータの中に隠れたパターンや構造を発見します。まるで失われた遺物を発見する探検家のようです。
生物学の遺伝的構造やマーケティングの顧客セグメンテーションなどは、教師なし学習の例です。
最後に、強化学習に到達します。ここでは、アルゴリズムが間違いを犯しながら学習する様子が、ちょうど子犬のようです。ペットを教えることを想像してみてください。行儀の悪さは非推奨ですが、良い行動は報われます。
これに似たような形で、アルゴリズムは行動をとり、報酬や罰を経験し、最適化方法を最終的に見つけ出します。この戦略はロボットやビデオゲームなどの産業で頻繁に使用されています。
機械学習の種類
ここでは、機械学習アルゴリズムを3つのサブセクションに分けます。これらのサブセクションは分類、回帰、クラスタリングです。
分類
名前の通り、分類はアイテムをグループ分けまたはカテゴリ分けするプロセスに焦点を当てています。様々な特徴に基づいて、植物を良性または危険なカテゴリに分類するような植物学者のような存在を想像してみてください。色に基づいてお菓子を異なる瓶に分けるのと同じです。
回帰
次に回帰です。これは数値変数を予測しようとする試みと考えてください。
この状況では、特徴(部屋の数、場所など)を考慮して、不動産のコストなどの特定の変数を予測することが目標です。
これは、明確に定義されたカテゴリではなく、連続的な範囲があるため、果物の大量を寸法から推測するのと似ています。
クラスタリング
ここでクラスタリングに到達します。これは整理されていない衣類を整理するのに似ています。事前に定義されたカテゴリ(またはラベル)がなくても、関連するオブジェクトを一緒に置きます。
あるアルゴリズムが、関係者の事前知識がないまま、ニュースストーリーをそのテーマに基づいて分類すると想像してみてください。それがクラスタリングです!
これらの仕事を行ういくつかの人気のあるアルゴリズムを分析してみましょう。まだまだ探求することがたくさんあります!
人気のある機械学習アルゴリズム
ここでは、決定木、サポートベクターマシン、K最近傍法、線形回帰などの人気のある機械学習アルゴリズムについて詳しく説明します。
A. 決定木
屋外イベントの計画を考えるとき、天候に依存して続行するか中止するかを決定する必要があります。この意思決定プロセスを表すために、決定木を使用することができます。
機械学習(ML)の分野での決定木の手法は、データについて一連のバイナリの質問(例:「降水していますか?」)を行い、収集を続けるか停止するかという決定に至るまで繰り返し行います。この手法は、予測の根拠を理解する必要がある場合に非常に役立ちます。
決定木について詳しく学びたい場合は、「決定木とランダムフォレストアルゴリズム(基本的にはステロイドを使用した決定木)」を読むことができます。
B. サポートベクターマシン(SVM)
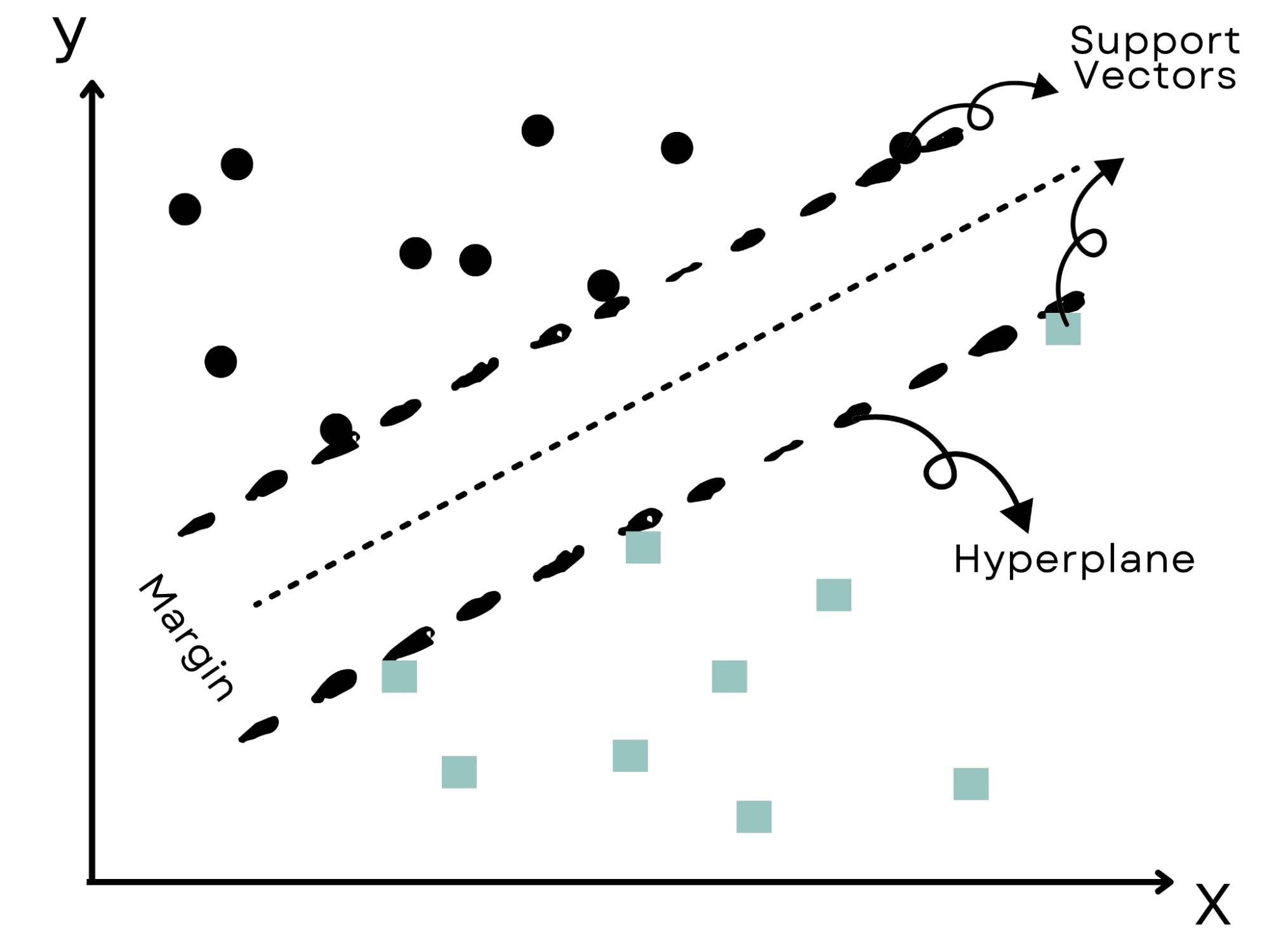
互いに敵対する2つのグループを分割することを目的とした、まるで西部劇のようなシナリオを想像してみてください。
衝突を避けるために、最も大きな実用的な境界を選ぶことになります。これがサポートベクターマシン(SVM)が行うことです。
SVMは、データをクラスタに分割する最も効果的な「ハイパープレーン」または境界を特定し、最も近いデータポイントからの最大距離を保ちます。
こちらでSVMについて詳細をご覧いただけます。
C. k最近傍法(KNN)
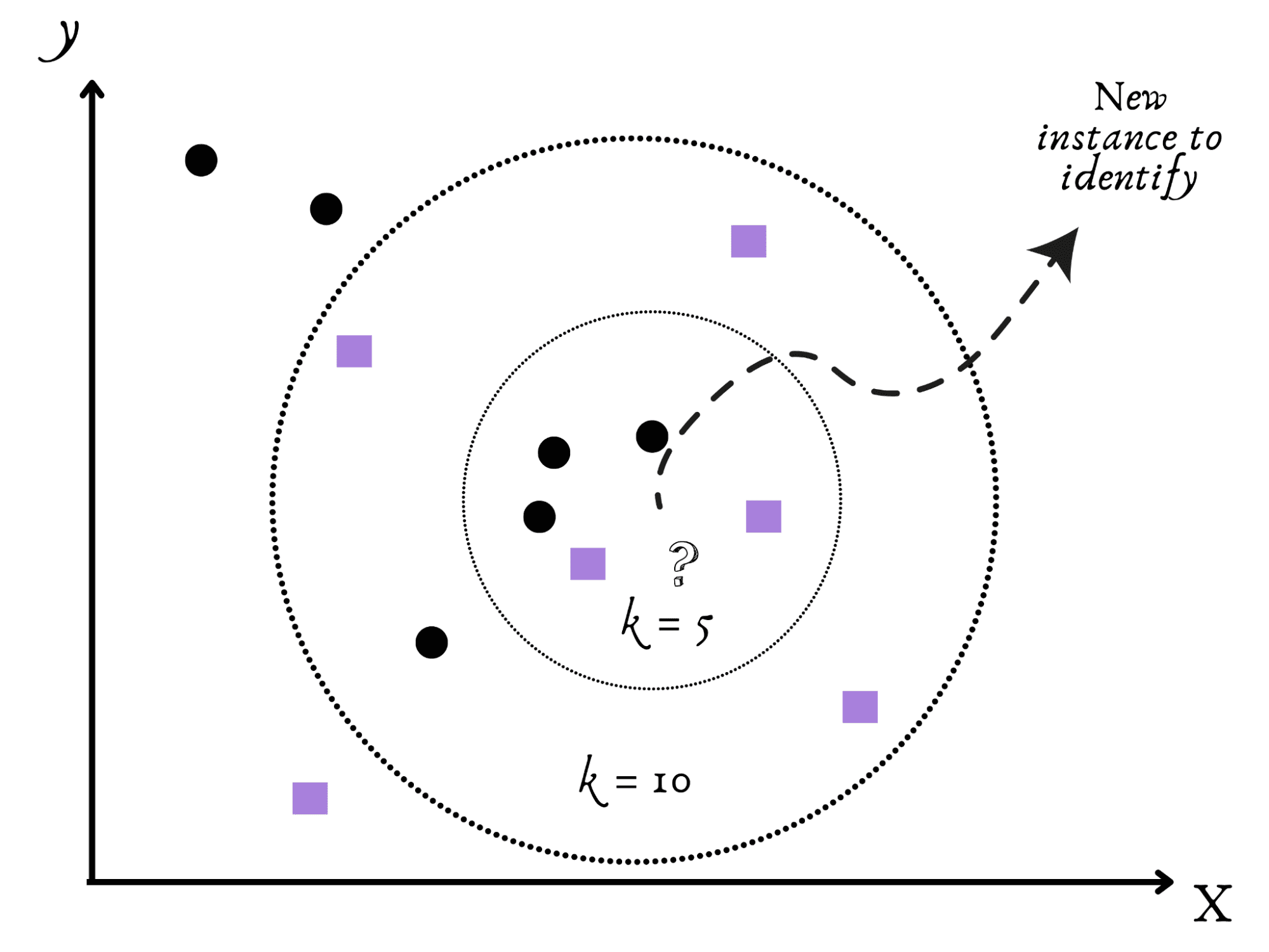
次に、友好的で社交的なアルゴリズムであるk最近傍法(KNN)です。
新しい町に引っ越してきて、静かな町なのか賑やかな町なのかを見極めようとすると想像してみてください。
近隣の住人を監視して理解を深めることが自然な行動のように思えます。
KNNは、データセット内の近隣データの引数(kなど)に基づいて新しいデータを分類します。
こちらでKNNについて詳しく知ることができます。
D. 線形回帰
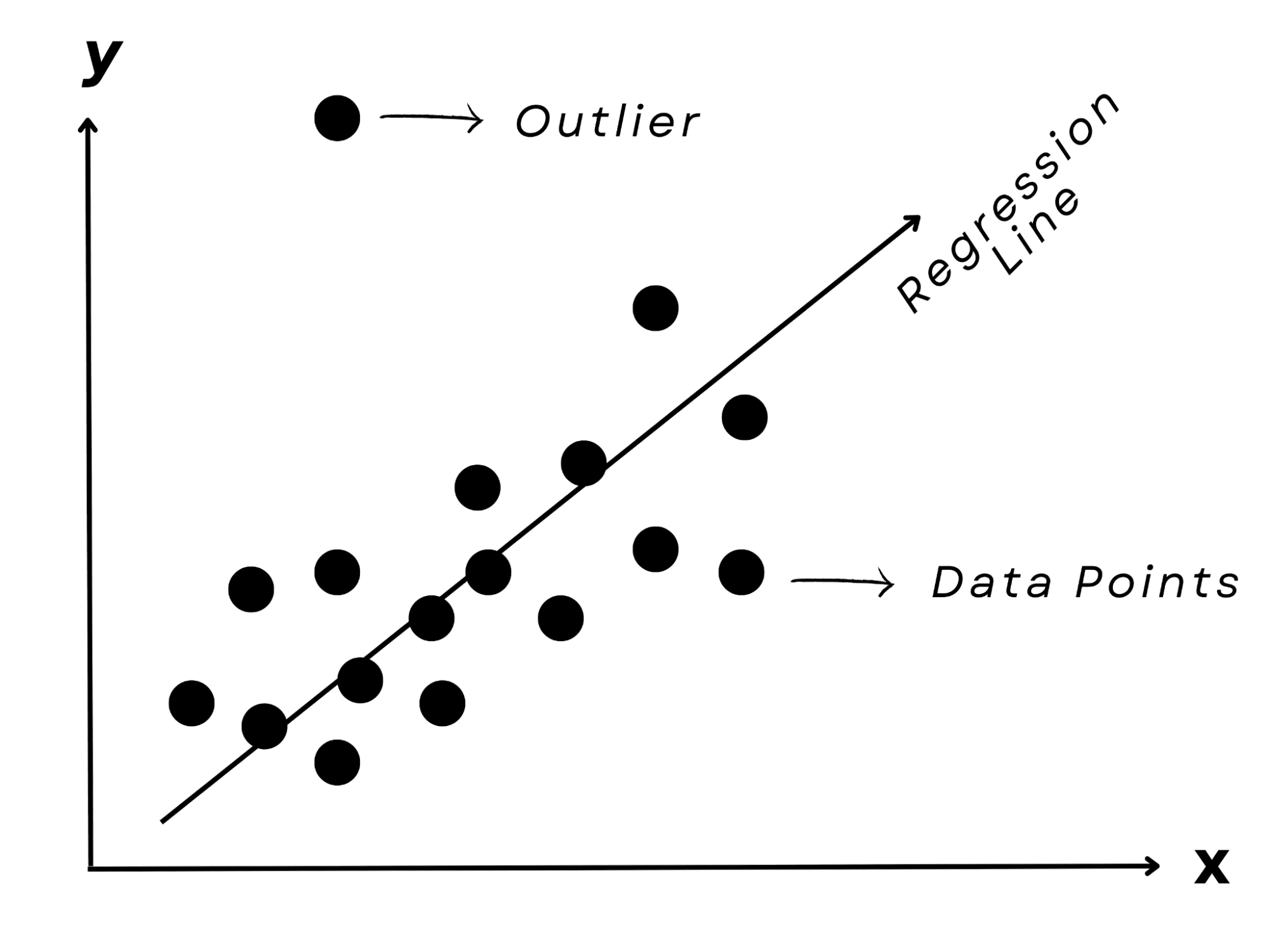
最後に、友人の試験結果を勉強時間に基づいて予測しようとする場合を想像してみてください。おそらくパターンを見つけるでしょう。勉強時間が長いほど、通常は良い結果につながるというパターンです。
線形回帰モデルは、その名前が示すように、入力(勉強時間)と出力(テストの点数)の間の直線的な関係を表すことができます。
これは、不動産の価格や株式市場の値など、数値の予測において好まれる手法です。
線形回帰について詳しくは、この記事を読んでください。
適切な機械学習モデルの選択
利用可能なオプションから適切なアルゴリズムを選ぶことは、非常に大きなハヤスタックの中から針を見つけるようなものかもしれません。しかし心配しないでください!重要な考慮事項をいくつか明確にして、このプロセスを明確にしましょう。
A. データの理解
データを最適なアルゴリズムへの手がかりを含む宝の地図と考えてみてください。
- データにラベルがありますか?(教師あり vs 教師なし学習)
- 特徴量はいくつありますか?(次元削減が必要ですか?)
- カテゴリカルなデータですか、数値データですか?(分類または回帰ですか?)
これらの質問の答えは、あなたを正しい方向に導くかもしれません。それに対して、ラベルのないデータはクラスタリングなどの教師なし学習アルゴリズムを促進するかもしれません。例えば、ラベル付きのデータは決定木などの教師あり学習アルゴリズムの使用を促します。
B. 問題を定義する
ねじ回しを使って釘を打つと効果的ではありませんよね。
問題を明確に定義することで、適切な「ツール」やアルゴリズムを選択することができます。隠れたパターンを特定することが目標ですか(クラスタリング)、カテゴリを予測することが目標ですか(分類)、またはメトリックを予測することが目標ですか(回帰)。
それぞれのタスクタイプには適したアルゴリズムがあります。
C. 実践的な側面を考慮する
理想的なアルゴリズムは、実際のアプリケーションでは理論よりも性能が低下することがあります。利用可能なデータ量、計算リソースの利用可能性、および結果の必要性はすべて重要な役割を果たします。
大規模なデータセットではKNNのような特定のアルゴリズムは性能が低下する可能性があり、一方でNaive Bayesのような他のアルゴリズムは複雑なデータでもうまく機能する可能性があります。
D. 評価を過小評価しない
最後に、モデルの性能を評価し検証することが重要です。購入前に洋服を試着するように、アルゴリズムがデータと効果的に機能することを確認したいのです。
この「フィット感」は、分類タスクの場合は正確さ、回帰タスクの場合は平均二乗誤差など、さまざまな指標で測定することができます。
結論
かなりの距離を移動しませんでしたか?
図書館を異なるジャンルに分類するように、機械学習の分野を教師あり、教師なし、および強化学習に分けました。そして、これらのジャンルに含まれる分類、回帰、およびクラスタリングなどのタスクの多様性を理解するために、さらに進んでいきました。
最初にいくつかのMLアルゴリズムを知りました。これには決定木、サポートベクターマシン、K最近傍法、ナイーブベイズ、および線形回帰が含まれます。それぞれのアルゴリズムには独自の特徴と強みがあります。
また、適切なアルゴリズムを選択することは、理論上の性能だけでなく、データ、問題の性質、実世界の応用、および性能評価を考慮することです。
すべての機械学習プロジェクトは独自の旅を提供し、すべての本は新たな物語を提供します。
最初の一歩をいつも正しく踏むことよりも、学び、実験し、改善することのほうが重要であることを忘れないでください。
さあ、データサイエンティストの帽子をかぶり、自分だけの機械学習の冒険に出かけましょう! Nate Rosidi はデータサイエンティストであり、製品戦略に携わっています。彼はまた、アナリティクスを教える非常勤講師であり、StrataScratchの創設者でもあります。StrataScratchは、トップ企業の実際の面接問題でデータサイエンティストが面接の準備をするのを支援するプラットフォームです。彼とのつながりはTwitter: StrataScratchまたはLinkedInで可能です。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





