「クラスタリング解放:K-Meansクラスタリングの理解」
Understanding K-Means Clustering A Release from Clustering

データを分析する際、私たちの心にあるのは、隠れたパターンを見つけ出し、意味のある洞察を抽出することです。さあ、新しいカテゴリの機械学習ベースの学習、つまり教師なし学習に入りましょう。クラスタリングの課題を解決するための強力なアルゴリズムの1つであるK-Meansクラスタリングアルゴリズムを紹介します。これはデータ理解を革新します。
K-Meansは、機械学習やデータマイニングの応用で有用なアルゴリズムとなっています。この記事では、K-Meansの仕組み、Pythonを使った実装、原則、応用などについて詳しく説明します。さあ、秘密のパターンを解き明かし、K-Meansクラスタリングアルゴリズムの潜在能力を活用する旅を始めましょう。
- 「夢を先に見て、後で学ぶ:DECKARDは強化学習(RL)エージェントのトレーニングにLLMsを使用するAIアプローチです」
- 「トランスフォーマベースのLLMがパラメータから知識を抽出する方法」
- 「TR0Nに会ってください:事前学習済み生成モデルに任意のコンディショニングを追加するためのシンプルで効率的な方法」
K-Meansアルゴリズムとは何ですか?
K-Meansアルゴリズムは、教師なし学習クラスに属するクラスタリング問題を解決するために使用されます。このアルゴリズムを使用することで、観測値をK個のクラスタにグループ化することができます。
このアルゴリズムは、内部的にベクトル量子化を使用しています。これにより、データセット内の各観測値を最小距離を持つクラスタに割り当てることができます。これはクラスタリングアルゴリズムのプロトタイプです。このクラスタリングアルゴリズムは、データマイニングや機械学習でよく使用され、類似性のメトリックに基づいてデータをK個のクラスタに分割します。したがって、このアルゴリズムでは、観測値とそれに対応する重心間の二乗距離の合計を最小化する必要があります。これにより、明確で均一なクラスタが得られます。
K-meansクラスタリングの応用
次に、このアルゴリズムのいくつかの一般的な応用例を紹介します。K-meansクラスタリングアルゴリズムは、クラスタリングに関連する問題を解決するための産業用途でよく使用される技術です。
- 顧客セグメンテーション: K-meansクラスタリングは、顧客の興味に基づいて異なる顧客をセグメント化することができます。銀行、通信、電子商取引、スポーツ、広告、販売などに適用できます。
- ドキュメントクラスタリング: この技術では、一連のドキュメントから類似したドキュメントをグループ化し、同じクラスタに属するようにします。
- レコメンデーションエンジン: 時には、K-meansクラスタリングを使用してレコメンデーションシステムを作成することがあります。たとえば、友達に曲をおすすめする場合、その人が好きな曲を見て、クラスタリングを使用して類似した曲を見つけ、最も類似したものをおすすめすることができます。
他にも、おそらくこの記事のコメントセクションで共有していただいている応用例がたくさんあると思います。
Pythonを使ったK-Meansクラスタリングの実装
このセクションでは、Pythonを使用して、データサイエンスプロジェクトで主に使用されるデータセットの1つにK-Meansアルゴリズムを実装していきます。
1. 必要なライブラリと依存関係のインポート
まず、NumPy、Pandas、Seaborn、Marplotlibなど、K-meansアルゴリズムの実装に使用するPythonライブラリをインポートしましょう。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
2. データセットの読み込みと分析
このステップでは、学生のデータセットをPandasのデータフレームに保存することで、データセットを読み込みます。データセットのダウンロードについては、こちらのリンクを参照してください。
問題の完全なパイプラインは以下のとおりです:

df = pd.read_csv('student_clustering.csv')
print("データの形状は",df.shape)
df.head()
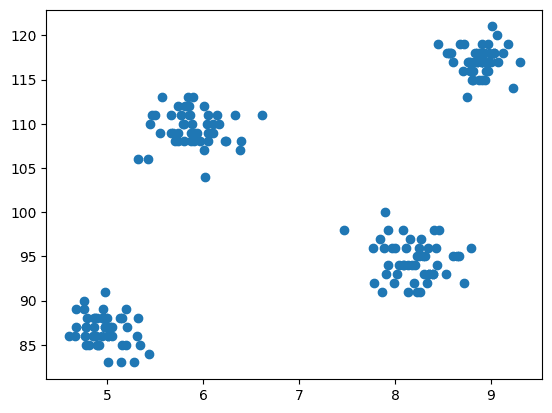
3. データセットの散布図
モデリングのステップでは、データを視覚化するために、クラスタリングアルゴリズムがどのように機能し、異なるクラスタを作成するかを確認するために、matplotlibを使用して散布図を描画します。
# データセットの散布図
import matplotlib.pyplot as plt
plt.scatter(df['cgpa'],df['iq'])
出力:
4. scikit-learnのClusterクラスからK-Meansをインポートする
K-Meansクラスタリングを実装するために、まずクラスタクラスをインポートし、そのクラスのモジュールとしてKMeansを使用します。
from sklearn.cluster import KMeans
5. エルボーメソッドを使用してKの最適な値を見つける
このステップでは、アルゴリズムを実装しながら、ハイパーパラメータの1つであるKの最適な値を見つけます。 Kの値は、データセットのために作成するクラスタの数を示します。この値を直感的に見つけることはできませんので、最適な値を見つけるために、WCSS(クラスタ内平方和)と異なるK値の間にプロットを作成し、WCSSの最小値を与えるKを選択する必要があります。
# レジデュアルを保存するための空のリストを作成
wcss = []
for i in range(1,11):
# KMeansクラスのオブジェクトを作成
km = KMeans(n_clusters=i)
# データフレームをアルゴリズムにフィットさせる
km.fit_predict(df)
# inertia値をwcssリストに追加
wcss.append(km.inertia_)
さて、エルボープロットを作成してKの最適な値を見つけましょう。
# WCSS vs. Kのプロットを作成して最適なKの値をチェック
plt.plot(range(1,11),wcss)
出力:
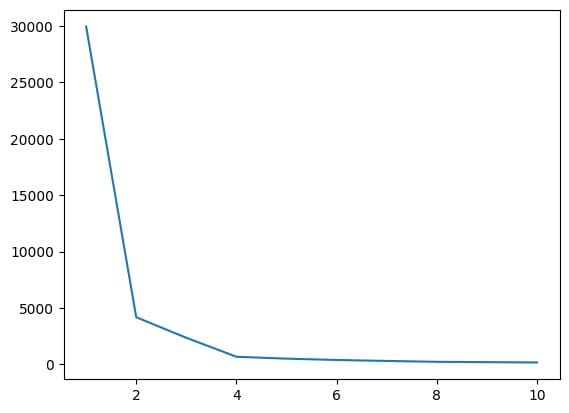
上記のエルボープロットから、K=4のときにWCSSの値が低下していることがわかります。これは、最適な値として4を使用する場合、クラスタリングは良いパフォーマンスを提供します。
6. K-Meansアルゴリズムを最適なKの値でフィットさせる
Kの最適な値を見つける作業は完了しました。ここでは、すべての特徴を持つ完全なデータセットを格納するX配列を作成し、ここではターゲットと特徴ベクトルを分離する必要はありません。これは教師なしの問題です。その後、選択したKの値でKMeansクラスのオブジェクトを作成し、提供されたデータセットにフィットさせます。最後に、異なるクラスタの平均を示すy_meansを出力します。
X = df.iloc[:,:].values # モデル構築には完全なデータを使用
km = KMeans(n_clusters=4)
y_means = km.fit_predict(X)
y_means
7. 各カテゴリのクラスタ割り当てを確認する
データセットのどの点がどのクラスタに属しているかを確認しましょう。
X[y_means == 3,1]
これまで、セントロイドの初期化にはK-Means++戦略を使用していましたが、ランダムなセントロイドをK-Means++の代わりに初期化して、同じプロセスに従って結果を比較してみましょう。
km_new = KMeans(n_clusters=4, init='random')
y_means_new = km_new.fit_predict(X)
y_means_new
一致する値の数を確認してください。
sum(y_means == y_means_new)
8. クラスタの可視化
各クラスタを可視化するために、軸上にプロットし、異なる色を割り当てます。これにより、形成された4つのクラスタを簡単に見ることができます。
plt.scatter(X[y_means == 0,0],X[y_means == 0,1],color='blue')
plt.scatter(X[y_means == 1,0],X[y_means == 1,1],color='red')
plt.scatter(X[y_means == 2,0],X[y_means == 2,1],color='green')
plt.scatter(X[y_means == 3,0],X[y_means == 3,1],color='yellow')
出力:

9. 3Dデータ上のK-Means
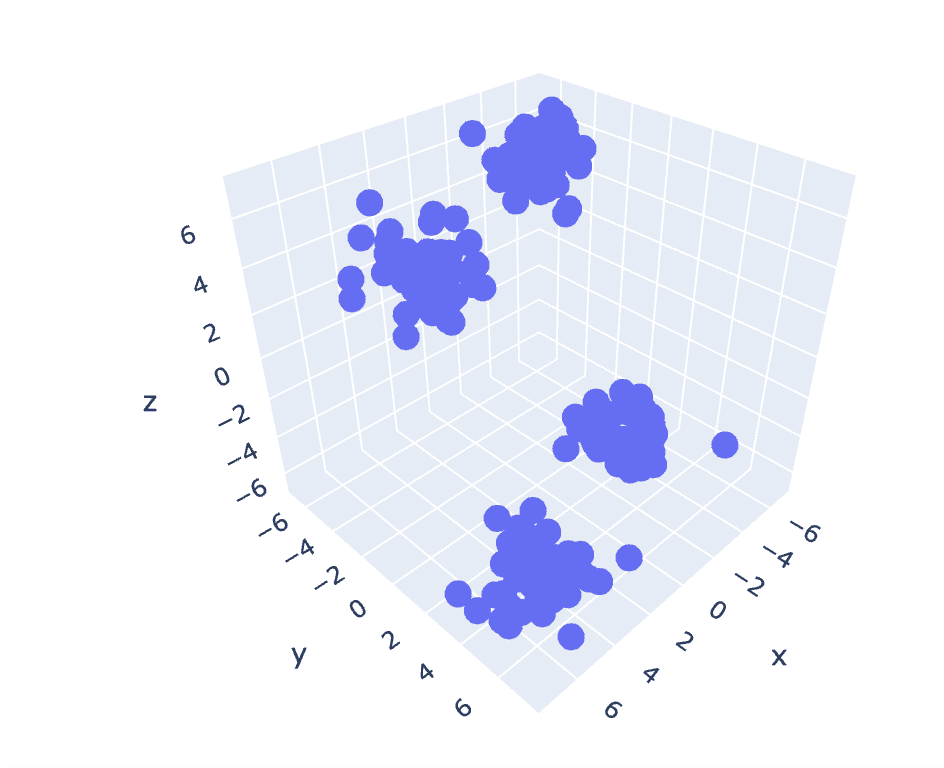
前のデータセットには2つの列があるため、2次元の問題があります。今度は、同じ手順を3次元の問題に対して利用し、n次元データのコード再現性を分析します。
# sklearnから合成データセットを作成します
from sklearn.datasets import make_blobs # 合成データセットを作成します
centroids = [(-5,-5,5),(5,5,-5),(3.5,-2.5,4),(-2.5,2.5,-4)]
cluster_std = [1,1,1,1]
X,y = make_blobs(n_samples=200,cluster_std=cluster_std,centers=centroids,n_features=3,random_state=1)
# データセットの散布図
import plotly.express as px
fig = px.scatter_3d(x=X[:,0], y=X[:,1], z=X[:,2])
fig.show()
出力:
wcss = []
for i in range(1,21):
km = KMeans(n_clusters=i)
km.fit_predict(X)
wcss.append(km.inertia_)
plt.plot(range(1,21),wcss)
出力:
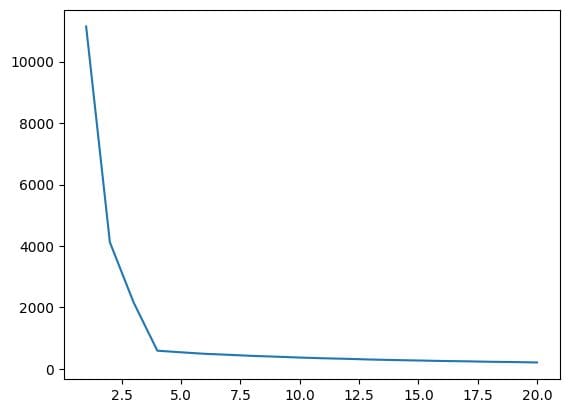 Fig.7 エルボープロット | 著者による画像
Fig.7 エルボープロット | 著者による画像
# 最適なKの値でK-Meansアルゴリズムをフィットさせる
km = KMeans(n_clusters=4)
y_pred = km.fit_predict(X)
# 異なるクラスタの分析
df = pd.DataFrame()
df['col1'] = X[:,0]
df['col2'] = X[:,1]
df['col3'] = X[:,2]
df['label'] = y_pred
fig = px.scatter_3d(df,x='col1', y='col2', z='col3',color='label')
fig.show()
出力:
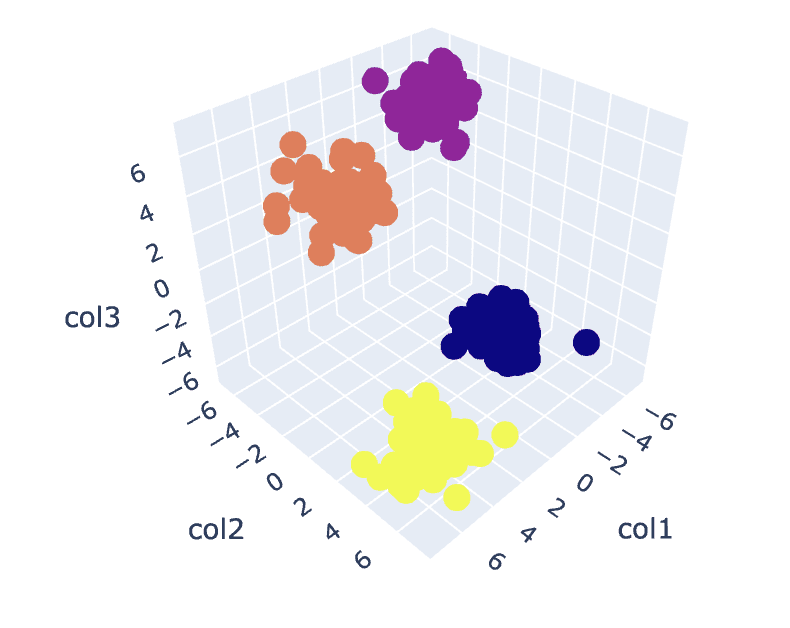 Fig.8. クラスタの可視化 | 著者による画像
Fig.8. クラスタの可視化 | 著者による画像
完全なコードはこちらで確認できます- Colab Notebook
まとめ
これで私たちの議論は終了です。K-Meansの動作、実装、およびアプリケーションについて議論しました。結論として、クラスタリングタスクを実装することは、データセットの観測値をグループ化するためのシンプルで直感的なアプローチを提供する教師なし学習のクラスから広く使用されるアルゴリズムです。このアルゴリズムの主な強みは、ユーザーがアルゴリズムを実装する際に選択された類似度メトリックに基づいて観測値を複数のセットに分割することです。
ただし、最初のステップでのセントロイドの選択に基づいて、私たちのアルゴリズムは異なる動作をし、ローカルまたはグローバルな最適解に収束します。したがって、アルゴリズムを実装するためのクラスタの数の選択、データの前処理、外れ値の処理などは、良い結果を得るために重要です。ただし、このアルゴリズムの制限の背後にあるもう一つの側面を観察すれば、K-Meansはさまざまな分野での探索的データ分析やパターン認識に役立つ技術です。Aryan Gargは、電気工学のB.Tech学生であり、現在は学部の最終年度です。彼の興味はWeb開発と機械学習の分野にあります。彼はこの興味を追求し、これらの方向でさらに活動することを熱望しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「合成キャプションはマルチモーダルトレーニングに役立つのか?このAI論文は、合成キャプションがマルチモーダルトレーニングにおけるキャプションの品質向上に効果的であることを示しています」
- 「もしも、視覚のみのモデルを、わずかな未ラベル化画像を使って線形層のみを訓練することで、ビジョン言語モデル(VLM)に変換できたらどうでしょうか? テキストから概念へ(そしてその逆)のクロスモデルアラインメントによる、Text-to-Conceptの紹介」
- 「LogAIとお会いしましょう:ログ分析と知能のために設計されたオープンソースライブラリ」
- 「最も適応能力の高い生存者 コンパクトな生成型AIモデルは、コスト効率の高い大規模AIの未来です」
- 「17/7から23/7までのトップコンピュータビジョン論文」
- 「大規模言語モデルのための任意のPDFおよび画像からテキストを抽出する方法」
- LangChain 101 パート1. シンプルなQ&Aアプリの構築





