「Flash-AttentionとFlash-Attention-2の理解:言語モデルの文脈長を拡大するための道」
Understanding Flash-Attention and Flash-Attention-2 A path to expanding the context length of language models.
これらの2つの手法は、LLM(Language Model)でより長いテキストシーケンスを処理するための大幅な改善を提供します。

私は最近、既に16万人以上の購読者を持つAIに特化した教育ニュースレターを始めました。TheSequenceは、5分で読めるノン・ビーエス(ハイプやニュースなどを含まない)の機械学習指向のニュースレターです。このニュースレターでは、機械学習のプロジェクト、研究論文、概念に関して最新の情報を提供します。ぜひ以下の購読ボタンから試してみてください。
TheSequence | Jesus Rodriguez | Substack
機械学習、人工知能、データの最新情報について最適なソースです。
thesequence.substack.com
大規模言語モデル(LLM)の文脈のスケーリングは、利用ケースの範囲を拡大する上で最大の課題の一つです。最近、AnthropicやOpenAIなどのベンダーが、モデルの文脈の長さを新たな高みに押し上げることを目撃してきました。この傾向は続く可能性がありますが、いくつかの研究の突破口が必要とされるでしょう。この領域で最も興味深い研究の1つは、最近スタンフォード大学によって発表されたものです。FlashAttentionと名付けられたこの新しい技術は、LLMの文脈を拡大する主要なメカニズムの1つとして急速に採用されています。FlashAttentionの2番目のイテレーションであるFlashAttention-2が最近発表されました。この記事では、両バージョンの基本を見ていきたいと思います。
FashAttention v1
最先端のアルゴリズムの領域で、FlashAttentionは画期的な変化をもたらします。このアルゴリズムは、注意の計算を再構成するだけでなく、タイリングや再計算などの古典的な技術を活用して、速度の驚異的な向上とメモリ使用量の大幅な削減を実現します。この変化により、シーケンスの長さに対して二次のメモリフットプリントから一次のメモリフットプリントに移行します。ほとんどの場合、FlashAttentionは非常にうまく機能しますが、並列処理が不足する非常に長いシーケンスには適していません。
拡張されたシーケンスに対して大規模なトランスフォーマを訓練する課題に取り組む際には、データ並列処理、パイプライン並列処理、およびテンソル並列処理などの最新の並列処理技術を活用することが重要です。これらの手法は、データとモデルを複数のGPUに分割するため、非常に小さなバッチサイズ(パイプライン並列処理ではバッチサイズ1で考えてください)と、通常8から12のヘッドの数を持つことがよくあります。FlashAttentionは、このようなシナリオを最適化することを目指しています。
FlashAttentionでは、各注意ヘッドに対して古典的なタイリング技術を採用し、メモリの読み書きを最小限に抑えます。GPUのHBM(メインメモリ)から高速なSRAM(高速キャッシュ)へのクエリ、キー、値のブロックをシャトルします。このブロック上で注意計算を実行した後、出力をHBMに書き戻します。このメモリの読み書き削減により、多くの利用ケースでは元の速度の2倍から4倍の大幅なスピードアップが得られます。
FlashAttentionの初期バージョンでは、バッチサイズとヘッドの数にわたる並列化が行われました。CUDAプログラミングに精通している方々は、各注意ヘッドを処理するために1つのスレッドブロックを展開することに感謝するでしょう。これにより、バッチサイズ * ヘッド数の総数が得られます。各スレッドブロックは、多数のGPUコンピューティングリソースを効率的に利用するために、ストリーミングマルチプロセッサ(SM)上で実行されるように細心の注意を払ってスケジュールされます。バッチサイズ * ヘッド数が80以上になるような場合、ほとんどのGPUの計算リソースをほぼ完全に効率的に利用することができます。
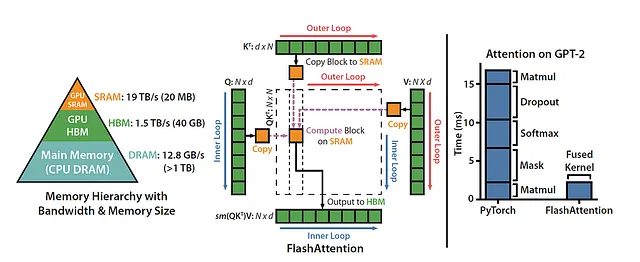
ただし、長いシーケンスを扱う場合には、通常は小さなバッチサイズや限られたヘッド数が関連していますので、FlashAttentionは異なるアプローチを取ります。具体的なドメインに合わせた著しい速度向上をもたらすために、シーケンス長次元に対する並列化を導入します。
バックワードパスに関しては、FlashAttentionはわずかに変更された並列化戦略を採用しています。各ワーカーはアテンション行列内の一連の列を担当します。これらのワーカーは協力し、通信を行い、クエリに関する勾配を集約するために原子操作を使用します。興味深いことに、FlashAttentionはこの文脈では列ごとの並列化が行を並列化するよりも優れたパフォーマンスを発揮することを発見しました。ワーカー間の通信の削減が重要なキーとなります。列ごとの並列化ではクエリの勾配を集約する必要がありますが、行ごとの並列化ではキーと値の勾配を集約する必要があります。

FlashAttention-2
FlashAttention-2では、スタンフォードチームは初期バージョンに対して緻密な改良を実施し、アルゴリズム内の非matmul FLOPを最小限に抑えることに焦点を当てています。この調整は、NvidiaのTensor Coresなどの専用の計算ユニットを備えた現代のGPUの時代において、行列の乗算(matmul)を大幅に高速化する役割を果たします。
FlashAttention-2はまた、依存しているオンラインsoftmax技術を再検討しています。その目標は、リスケーリング操作、バウンドチェック、および因果マスキングを効率化することであり、出力の完全性を保ちながらこれらの操作を行います。
初期バージョンでは、FlashAttentionはバッチサイズとヘッド数の両方にわたって並列化を実施しました。ここでは、各アテンションヘッドは専用のスレッドブロックによって処理され、合計で(バッチサイズ * ヘッド数)のスレッドブロックが生成されました。これらのスレッドブロックはスムーズにストリーミングマルチプロセッサ(SM)上にスケジュールされ、A100 GPUのような108のSMを搭載した優れた性能を発揮しました。このスケジューリング戦略は、スレッドブロックの総数が多い場合に最も効果的であり、通常80以上になることが求められました。これにより、GPUの計算リソースを最適に利用することができました。
長いシーケンスを伴うシナリオでの改善を図るために、FlashAttention-2ではシーケンス長を並列化する追加の次元を導入しています。この戦略的な適応により、この特定の文脈で大幅な速度向上が実現されます。
さらに、各スレッドブロック内でも、FlashAttention-2は異なるワープ(32個のスレッドが一斉に動作するグループ)間で効果的にワークロードを分割する必要があります。通常、スレッドブロックごとに4または8のワープが使用され、以下の分割スキームが明示されます。FlashAttention-2では、この分割方法が改良され、ワープ間の同期と通信を減らし、共有メモリの読み書きを最小限に抑えることを目指しています。
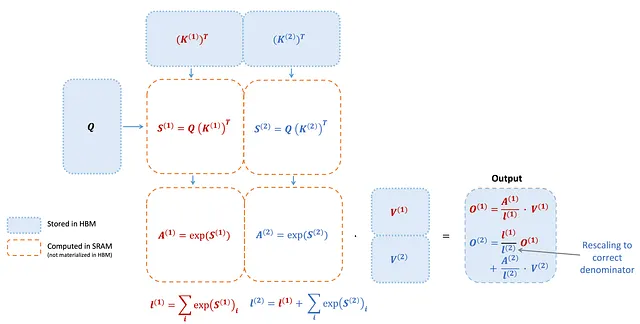
以前の構成では、FlashAttentionはKとVを4つのワープに分割し、Qはすべてのワープでアクセス可能な状態にしていました。これは「sliced-K」と呼ばれるスキームです。しかし、このアプローチでは、すべてのワープが中間結果を共有メモリに書き込み、同期を行い、それらの結果を集約する必要がありました。これらの共有メモリ操作は、FlashAttentionのフォワードパスにパフォーマンスのボトルネックを引き起こしました。
FlashAttention-2では、戦略が異なります。Qは4つのワープに割り当てられ、KとVはすべてのワープでアクセス可能な状態になっています。各ワープは行列の乗算を実行してQ K^Tのスライスを取得し、それを共有されたVのスライスと単純に乗算して各自の出力スライスを得ます。この配置により、ワープ間の通信が不要となります。共有メモリの読み書きの削減は、大幅な高速化につながります。
FlashAttentionの以前のバージョンでは、ヘッドの次元を最大128までサポートしており、ほとんどのモデルには十分であるが、いくつかのモデルは対象外となっていました。FlashAttention-2では、ヘッドの次元を256までサポートするように拡張され、GPT-J、CodeGen、CodeGen2、およびStableDiffusion 1.xなどのモデルがFlashAttention-2を利用して高速化とメモリ効率の向上を図ることができます。
さらに、FlashAttention-2では、マルチクエリアテンション(MQA)およびグループ化クエリアテンション(GQA)に対応しています。これらは、クエリの複数のヘッドが同時にキーと値の同じヘッドに参照する特殊な注意のバリアントです。この戦略的な操作は、推論時のKVキャッシュサイズを削減し、推論スループットを大幅に向上させることを目指しています。
改善点
スタンフォードチームは、FlashAttention-2を元のバージョンおよび他の代替手法と比較してさまざまなベンチマークで評価しました。テストにはアテンションアーキテクチャのさまざまなバリエーションが含まれ、その結果は非常に注目に値します。
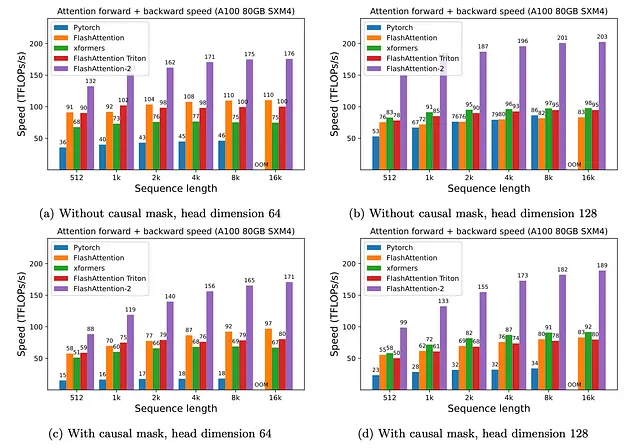
FlashAttentionとFlashAttention-2は、LLMの文脈を拡張するために使用される基本的な技術の2つです。この研究は、この領域で最も大きな研究の突破口の一つを表しており、LLMの容量を増やすのに役立つ新しい手法に影響を与えています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「Verbaに会ってください:自分自身のRAG検索増強生成パイプラインを構築し、LLMを内部ベースの出力に活用するためのオープンソースツール」
- 高性能意思決定のためのRLHF:戦略と最適化
- 「ResFieldsをご紹介します:長くて複雑な時間信号を効果的にモデリングするために、時空間ニューラルフィールドの制約を克服する革新的なAIアプローチ」
- ディープラーニングによる触媒性能の秘密の解明:異種触媒の高精度スクリーニングのための「グローバル+ローカル」畳み込みニューラルネットワークのディープダイブ
- 「時を歩く:SceNeRFlowは時間的一貫性を持つNeRFを生成するAIメソッドです」
- 強化学習 価値反復の簡単な入門
- Fast.AIディープラーニングコースからの7つの教訓