マルチヘッドアテンションを使用した注意機構の理解
Understanding attention mechanism using multi-head attention.
はじめに
Transformerモデルについて詳しく学ぶ良い方法は、アテンションメカニズムについて学ぶことです。特に他のタイプのアテンションメカニズムを学ぶ前に、マルチヘッドアテンションについて学ぶことは良い選択です。なぜなら、この概念は少し理解しやすい傾向があるためです。
アテンションメカニズムは、通常の深層学習モデルに追加できるニューラルネットワークレイヤーと見なすことができます。これにより、重要な部分に割り当てられた重みを使用して、入力の特定の部分に焦点を当てるモデルを作成することができます。ここでは、マルチヘッドアテンションメカニズムを使用して、アテンションメカニズムについて詳しく見ていきます。

学習目標
- アテンションメカニズムの概念
- マルチヘッドアテンションについて
- Transformerのマルチヘッドアテンションのアーキテクチャ
- 他のタイプのアテンションメカニズムの概要
この記事は、データサイエンスブログマラソンの一環として公開されました。
アテンションメカニズムの理解
まず、この概念を人間の心理学から見てみましょう。心理学では、注意は他の刺激の影響を除外して、イベントに意識を集中することです。つまり、他の注意を引くものがある場合でも、私たちは選択したものに焦点を合わせます。注意は全体の一部に集中します。
これがTransformerで使用される概念です。彼らは入力のターゲット部分に焦点を当て、残りの部分を無視することができます。これにより、非常に効果的な方法で動作することができます。
マルチヘッドアテンションとは?
マルチヘッドアテンションは、Transformerにおいて中心的なメカニズムであり、ResNet50アーキテクチャにおけるskip-joiningに相当します。場合によっては、アテンドするべきシーケンスの複数の他の点があります。全体の平均を見つける方法では、重みを分散させて多様な値を重みとして与えることができません。これにより、複数のアテンションメカニズムを個別に作成するアイデアが生まれ、複数のアテンションメカニズムが生じます。実装では、1つの機能に複数の異なるクエリキー値トリプレットが表示されます。

計算は、アテンションモジュールが何度も反復し、アテンションヘッドとして知られる並列レイヤーに組織化される方法で実行されます。各別のヘッドは、入力シーケンスと関連する出力シーケンスの要素を独立して処理します。各ヘッドからの累積スコアは、すべての入力シーケンスの詳細を組み合わせた最終的なアテンションスコアを得るために組み合わされます。
数式表現
具体的には、キーマトリックスとバリューマトリックスがある場合、値をℎサブクエリ、サブキー、サブバリューに変換し、アテンションを独立して通過させることができます。連結すると、ヘッドが得られ、最終的な重み行列でそれらを組み合わせます。

学習可能なパラメータは、アテンションに割り当てられた値であり、各パラメータはマルチヘッドアテンションレイヤーと呼ばれます。以下の図はこのプロセスを示しています。
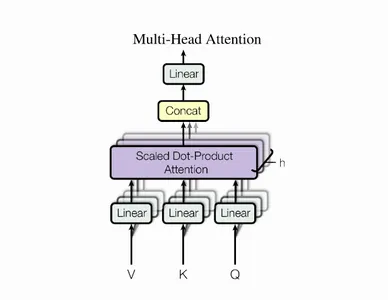
これらの変数を簡単に見てみましょう。Xの値は、単語埋め込みの行列の連結です。
行列の説明
クエリ:シーケンスのターゲットについての洞察を提供する特徴ベクトルです。クエリは、何がアテンションを必要としているかをシーケンスに要求します。
キー:要素に含まれるものを説明する特徴ベクトルです。クエリによってアテンションが与えられ、要素のアイデンティティを提供します。
値: 入力シーケンスを処理し、各入力要素が提供する平均値を知るために値を使用します。
スコア関数: スコア関数を作成するために、クエリとキーを割り当て、クエリキーのペアとして知られる重みを出力します。
以下の図を使用して、Q:これはクエリを表し、K:これはキーを表し、V:これは値を表します。

クエリトークンの注意重みは、マルチヘッドアテンションによって決定されます。各キートークンとそれに対応する値が乗算されます。クエリとキーの間の関係または注意の重みを決定した後、各キーに関連する値を乗算します。
最終的に、マルチヘッドアテンションにより、さまざまな入力シーケンスセグメントをさまざまな方法で処理できます。各ヘッドが個別に異なる入力要素に注意を払うため、モデルは位置情報の詳細をよりよく捕捉できます。その結果、私たちの表現はより強力になります。
マルチヘッドアテンションのPython実装
さて、Pythonを使用したマルチヘッドアテンションメカニズムの実践的な実装を見てみましょう。この1つを実装するためにPythonを使用します。私たちは、クエリ、キー、および値に関連する連続した重み行列を特徴量に変換します。
class MultiheadAttention(nn.Module):
def __init__(self, input_dim, embed_dim, num_heads):
super().__init__()
assert embed_dim % num_heads == 0, "埋め込み次元はヘッドの数で0である必要があります。"
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
# 効率化のためにすべての重み行列1...hをスタックします
# 多くの実装でオプションの "bias = False" が表示されることに注意してください。
self.qkv_proj = nn.Linear(input_dim, 3 * embed_dim)
self.o_proj = nn.Linear(embed_dim, embed_dim)
self._reset_parameters()
def _reset_parameters(self):
# オリジナルのTransformer初期化、PyTorchのドキュメントを参照してください
nn.init.xavier_uniform_(self.qkv_proj.weight)
self.qkv_proj.bias.data.fill_(0)
nn.init.xavier_uniform_(self.o_proj.weight)
self.o_proj.bias.data.fill_(0)
def forward(self, x, mask=None, return_attention=False):
batch_size, seq_length, _ = x.size()
if mask is not None:
mask = expand_mask(mask)
qkv = self.qkv_proj(x)
# 線形出力からQ、K、Vを分離する
qkv = qkv.reshape(batch_size, seq_length, self.num_heads, 3 * self.head_dim)
qkv = qkv.permute(0, 2, 1, 3) # [Batch, Head, SeqLen, Dims]
q, k, v = qkv.chunk(3, dim=-1)
# 値の出力を決定する
values, attention = scaled_dot_product(q, k, v, mask=mask)
values = values.permute(0, 2, 1, 3) # [Batch, SeqLen, Head, Dims]
values = values.reshape(batch_size, seq_length, self.embed_dim)
o = self.o_proj(values)
if return_attention:
return o, attention
else:
return o詳細はこちらを参照してください。
変圧器のマルチヘッドアテンションのアーキテクチャ
元々機械翻訳のために設計されたTransformerアーキテクチャは、エンコーダー-デコーダー構造を持っています。エンコーダーは、アテンションベースの表現を生成し、デコーダーはエンコードされた情報にアテンションを集め、自己回帰的に翻訳された文を生成します。この構造は、自己回帰的デコーディングを持つシーケンス・トゥ・シーケンス・タスクに有用です。このチュートリアルでは、実装するための小さなステップであるエンコーダー部分に焦点を当てます。
![]()
エンコーダーは、同一のブロックを順次適用し、入力をマルチヘッドアテンションブロック、残差接続、およびレイヤー正規化を介して渡します。アテンション層への入力と入力を計算し、Transformerアーキテクチャにおける重要な残差接続を確保します。
トランスフォーマーには、スムーズな勾配フローのために残差接続が必要な24以上のエンコーダーブロックがあります。残差接続がないと、元のシーケンスに関する情報が失われ、マルチヘッドアテンション層は基本的な入力特徴を学習します。残差接続を削除すると、初期化後に失われた情報があり、すべての出力ベクトルが類似した情報を表すことになります。
他にどのような種類のAttention Mechanismがありますか?
最後に、マルチヘッド以外にも、様々な調整を行ったAttention Mechanismが存在することに注意が必要です。以下にその種類を示します。
- Global Attention / Luong Mechanism:Luongモデルは、すべてのソース単語にアテンドするか、ターゲット文を予測することができ、より少ない単語の集合にアテンドすることもできます。グローバルとローカルのAttentionモデルは同じように効果的ですが、特定の実装に応じて、異なるコンテキストベクトルを使用します。
- 汎用Attention:汎用Attentionモデルは、入力シーケンスを検証し、出力シーケンスと比較して、それらをキャプチャして比較します。その後、メカニズムは、注目する単語や画像の一部を選択します。
- 加算Attention / Bahdanau:Bahdanau Attention Mechanismは、ニューラルネットワーク内のアラインメントスコアを使用して、異なるポイントで計算を行い、入力シーケンスの単語と出力シーケンスの単語の相関関係を考慮して、隠れ状態を考慮します。最終スコアはこれらのスコアの合計です。
- 自己Attention / Intra-attention:自己Attentionメカニズム、またはIntra-attentionとも呼ばれます。出力シーケンスを考慮せず、入力シーケンスの一部を拾い上げ、時間にわたって初期の出力構成を計算します。手動でのデータ入力手順がないため、出力シーケンスを考慮しません。
結論
Attention Mechanismは、自然言語処理タスクなどのアプリケーションにおいて、最先端の結果を生み出しています。GPT-2やBERTなどの画期的なアルゴリズムに貢献しています。Transformersは、Attentionから大きな恩恵を受けたネットワークです。ビジネス環境の変革やAIソリューションの進歩に向けた本物の自然言語理解に向けた取り組みの一つとなっています。
キーポイント
- Transformerモデルをより深く理解するには、特にマルチヘッドAttentionについて学ぶことが重要です。
- 使用された手法により、1つの入力特徴量に複数のアテンションメカニズムを適用することができます。
- Transformerは、スムーズな勾配フローを実現するために残差コネクションを必要とし、元のシーケンス情報の損失を防止し、入力特徴に基づく学習を行います。
よくある質問(FAQ)
参考リンク:
- Tutorial 6: Transformers and Multi-Head Attention – UvA DL Notebooks v1.2 documentationJAX+Flax version: In this tutorial, we will discuss one of the most impactful architectures of the last 2 years: the…uvadlc-notebooks.readthedocs.io
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention Is All You Need. ArXiv. /abs/1706.03762
- https://d2l.ai/chapter_attention-mechanisms-and-transformers/multihead-attention.html
- https://w7.pngwing.com/pngs/400/754/png-transparent-comic-book-comics-pop-art-attention-miscellaneous-text-photography-thumbnail.png
- https://w7.pngwing.com/pngs/682/32/png-transparent-attention-psychology-homo-sapiens-graphy-information-attention-hand-photography-words-phrases-thumbnail.png
- https://upload.wikimedia.org/wikipedia/commons/8/8f/The-Transformer-model-architecture.png
この記事で使用されているメディアはAnalytics Vidhyaの所有物ではなく、著者の裁量により使用されています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






