「過小評価されている宝石Pt.1:あなたをプロにする8つのPandasメソッド」
Underrated Gem Pt.1 8 Pandas Methods to Make You a Pro
低評価され、過小評価され、未開拓の
「群衆の騒音の中で、隠れた知恵を持つ言葉が静かに語られる💎」
しばらくChatGPTを忘れましょう。私たちの中には、シンプルなPandasの操作を行いたいときに毎回解決策をググり続けることに疲れる人もいます。同じことをするための数多くの方法があるようですが、それはどれでしょう?選択肢がたくさんあることはもちろん素晴らしいことですが、それにはコードの行がどのようなことをするかを理解することに関しての一貫性や混乱も伴います。
ローマにたどり着くためには1000通りのルートがあります。もしかしたらそれ以上かもしれません。問題は、隠れたショートカットを通るのか、複雑なルートを辿るのか、どちらを選ぶかです。

この投稿のまとめです。UCI Machine Learning¹のバイクシェアリングデータセットを使用して、これらのメソッドを実践的に活用する方法を説明します。これらのメソッドを採用することで、データ操作のコードを効率化するだけでなく、書いたコードの深い理解も得ることができます。データセットのインポートとDataFrameのクイックビューを始めましょう!
- JuliaでのMS SQL Serverの操作
- GPBoostを使用した縦断およびパネルデータのための混合効果機械学習(パートIII)
- 「データクリーニングでPandasを使用する前にこれを読むべき理由」
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
bike = (pd
.read_csv("../../dataset/bike_sharing/day.csv")
)
bike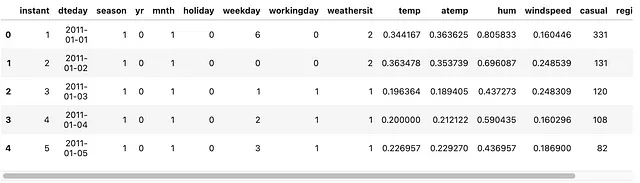
目次
- メソッド#1:
.assign() - メソッド#2:
.groupby() - メソッド#3:
.agg() - メソッド#4:
.transform() - メソッド#5:
.pivot_table() - メソッド#6:
.resample() - メソッド#7:
.unstack() - メソッド#8:
.pipe()
☕️ メソッド#1: .assign()
df["new_col"] =やdf.new_col =などの操作を使って新しい列を作成することを忘れましょう。なぜなら、.assign()メソッドを使用する方が良い理由があるからです。このメソッドは、DataFrameオブジェクトを返すため、DataFrameをさらに操作するためのチェーン操作を続けることができます。一方、.assign()メソッドは、上記の2つの悪名高い操作はNoneを返すため、さらなる操作をチェーンすることはできません。
説得力がない場合は、古い敵であるSettingWithCopyWarningを取り戻しましょう。きっとそれぞれが一度はこれにぶつかったことがあるはずです。

警告にはうんざりです。ノートブックで醜い赤いボックスを見たくないです!
.assign()を使用して、ratio_casual_registered、avg_temp、およびratio_squaredなどの新しい列を追加しましょう
(bike .assign(ratio_casual_registered = bike.casual.div(bike.registered), avg_temp = bike.temp.add(bike.atemp).div(2), ratio_squared = lambda df_: df_.ratio_casual_registered.pow(2)))要するに、上記のメソッドは次のようなことをします:
.assign()メソッドを使用して、区切り文字のカンマで区切られた形式で必要なだけの新しい列を作成できます。- 列
ratio_squaredを作成する際のラムダ関数は、列ratio_casual_registeredを追加した後の最新のDataFrameにアクセスするために使用されます。つまり、最新のDataFramedf_にアクセスするためにラムダ関数を使用せずに、bike.ratio_casual_registered.pow(2)を使用し続けると、.assign()メソッドでratio_casual_registeredを追加した後でも、元のDataFrameにはratio_casual_registered列が存在しないためエラーが発生します。この概念が理解できない場合、ラムダ関数を使用するかどうかを決定するのが難しい場合は、単に使用することをお勧めします! - ボーナス!メソッドを使用して算術演算を行う一般的でない方法をいくつか紹介します。
☕️ メソッド#2:.groupby()
さて、.groupby()メソッドは珍しくはありませんが、次のメソッドに深入りする前に始めるために必要です。しばしば見落とされ、語られないことの1つは、.groupby()メソッドが遅延評価される性質を持っていることです。つまり、すぐに評価されないということです。そのため、.groupby()メソッドを呼び出した直後に<pandas.core.groupby.generic.DataFrameGroupBy object at 0x14fdc3610>のような表示がよく見られます。
Pandas DataFrameのドキュメント²によると、パラメータbyに渡す値は、マッピング、関数、ラベル、pd.Grouper、またはそのリストを指定できます。ただし、おそらく最も一般的なのは、列名でグループ化することです(カンマで区切られたSeries名のリスト)。.groupby()操作の後、.mean()、.median()、または.apply()を使用してカスタム関数を適用するなどの操作を行うことができます。
.groupby()メソッドのbyパラメータに指定した列の値は、結果のインデックスになります。グループ化する列を1つ以上指定する場合、MultiIndexを取得します。
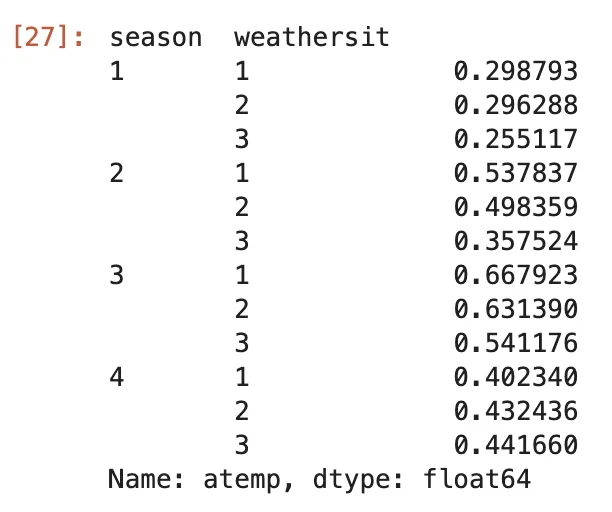
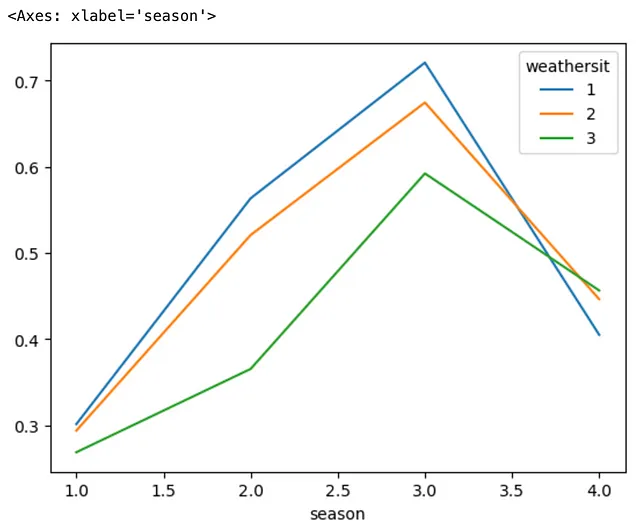
(bike .groupby(['season', 'weathersit']) .mean(numeric_only=True) #alternative version: apply(lambda df_: df_.mean(numeric_only=True)) .atemp)ここでは、DataFrameを列seasonとweathersitでグループ化し、平均値を計算して列atempのみを抽出しています。
☕️ メソッド#3:.agg()
Pandasのドキュメント²を細かく読んでいれば、.agg()メソッドと.aggregate()メソッドの両方に遭遇するかもしれません。これらの違いやどちらを使用するかについて疑問に思うかもしれません。時間を節約してください!これらは同じです。単に.agg()は.aggregate()の別名に過ぎません。
.agg()にはfuncというパラメータがあり、関数、文字列の関数名、または関数のリストを受け取ります。ちなみに、異なる関数を列ごとに集計することもできます!上記の例を続けましょう!
#Example 1: 複数の関数を使用して集計(bike .groupby(['season']) .agg(['mean', 'median']) .atemp)#Example 2: 異なる列に異なる関数を使用して集計(bike .groupby(['season']) .agg(Meann=('temp', 'mean'), Mediann=('atemp', np.median)))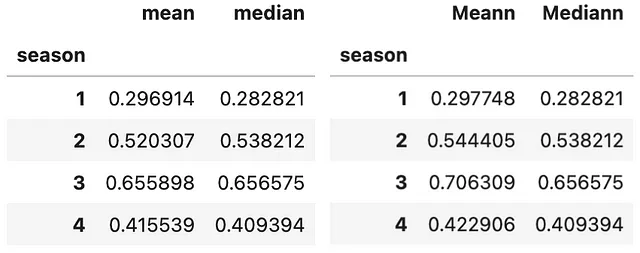
☕️ メソッド #4: .transform()
.agg()を使用すると、初期データセットと比較して、次元が削減された結果が得られます。単純に言えば、データの次元は、集計情報を含むより少ない行と列で縮小します。グループ化されたデータを要約し、集計値を取得することが目的であれば、.groupby()が解決策です。
.transform()を使用すると、情報の集計を行う意図で開始します。しかし、情報の要約を作成する代わりに、元のDataFrameと同じ形状の出力を得たいのです。データセットのサイズを縮小しないようにします。
SQLなどのデータベースシステムに詳しい方は、.transform()のアイデアがWindow関数に似ていると感じるかもしれません。上記の例で.transform()がどのように機能するか見てみましょう!
(bike .assign(mean_atemp_season = lambda df_: df_ .groupby(['season']) .atemp .transform(np.mean, numeric_only=True)))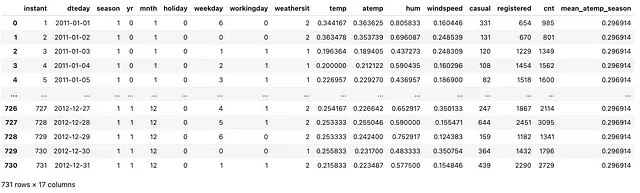
上記のように、mean_atemp_seasonという列名の新しい列を作成し、atemp列の集計(平均)で列を埋めます。したがって、seasonが1の場合、mean_atemp_seasonには同じ値があります。ここで重要な観察結果は、元のデータセットの次元が保持され、1つの追加の列があることです!
☕️ メソッド #5: .pivot_table()
Microsoft Excelに夢中な方へのボーナスです。サマリーテーブルを作成するために.pivot_table()を使用することに誘惑されるかもしれません。もちろん、この方法も機能します!しかし、ここで2セント、.groupby()はより多目的で、単に再形成するだけでなく、フィルタリング、変換、またはグループ固有の計算など、さまざまな操作に使用されます。
簡単に使い方を説明します。引数のvaluesで集計したい列を指定します。次に、元のDataFrameのサブセットを使用して作成するサマリーテーブルのインデックスを指定します。これは複数の列であり、サマリーテーブルはMultiIndexのDataFrameになります。次に、インデックスとして選択されていない元のDataFrameのサブセットを使用して作成するサマリーテーブルの列を指定します。最後に、aggfuncを指定するのを忘れないでください!さっそく見てみましょう!
(bike .pivot_table(values=['temp', 'atemp'], index=['season'], columns=['workingday'], aggfunc=np.mean))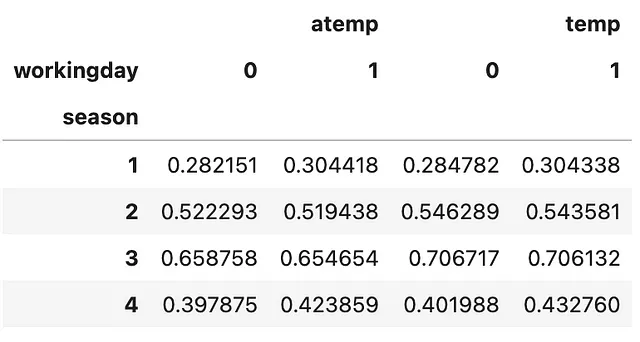
☕️ メソッド #6: .resample()
大まかに言えば、.resample()メソッドは、
データフレームまたはシリーズのインデックスが日付時間のようなオブジェクトである場合。
これにより、異なる時間の頻度(時間ごと、日ごと、週ごと、月ごとなど)に基づいてデータをグループ化および集計できます。より一般的には、.resample()は、リサンプリングを実行するためのルールとしてDateOffset、Timedelta、またはstrを受け入れることができます。前の例にこれを適用してみましょう。
def tweak_bike(bike: pd.DataFrame) -> pd.DataFrame: return (bike .drop(columns=['instant']) .assign(dteday=lambda df_: pd.to_datetime(df_.dteday)) .set_index('dteday') )bike = tweak_bike(bike)(bike .resample('M') .temp .mean())要するに、上記のコードでは、instant列を削除し、dteday列をobject型からdatetime64[ns]型に変換したdteday列で上書きし、最後にこのdatetime64[ns]列をDataFrameのインデックスとして設定することを行っています。
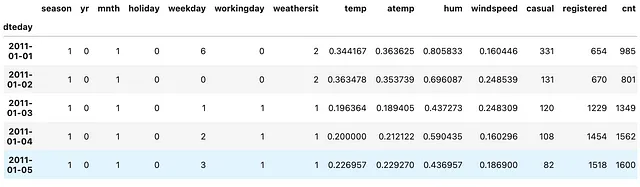
(bike .resample('M') .temp .mean())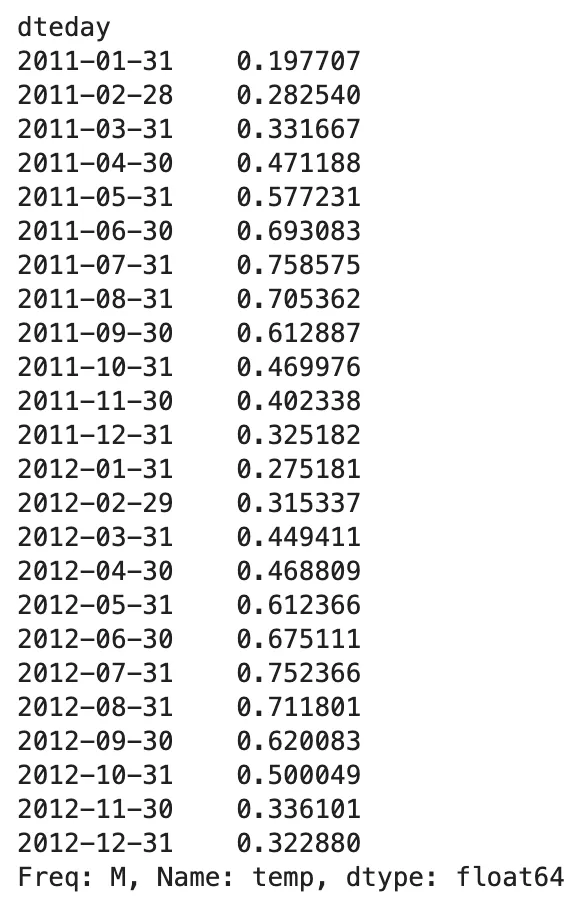
ここでは、.resample()メソッドを使用して、tempフィーチャーの月次の平均値という記述統計の要約を取得しています。 Q、2M、Aなどの異なる頻度を使用して.resample()メソッドを試してみてください。
☕️ メソッド #7: .unstack()
終わりが近づいています! .unstack()がなぜ強力で便利なのかをお見せしましょう。しかし、その前に、.groupby()と.agg()を使用してさまざまな季節と天候状況ごとの平均気温を見つけたいとする以前の例に戻りましょう。
(bike .groupby(['season', 'weathersit']) .agg('mean') .temp)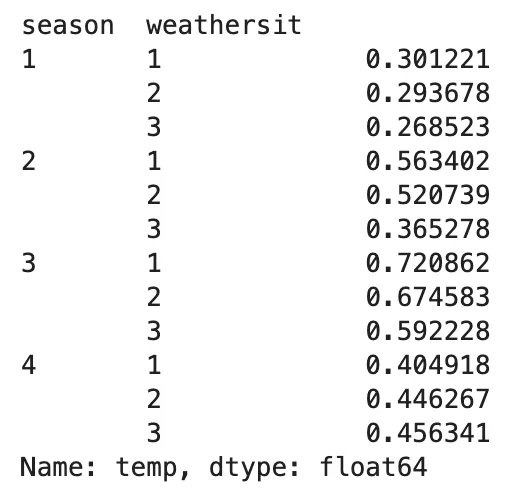
さて、これを最小限に抑えたラインチャートを使用して可視化しましょう。上記のコードに.plotと.line()メソッドを連鎖させることで、PandasはMatplotlibのプロットバックエンドを活用してプロットタスクを実行します。これにより、次の結果が得られます。ただし、私たちの誰もが望んでいない結果です。プロットのx軸がMultiIndexでグループ化されているため、解釈が困難で意味が少なくなっています。
上記のプロットと、.unstack()メソッドを導入した後のプロットを比較してみましょう。
(bike .groupby(['season', 'weathersit']) .agg('mean') .temp .unstack() .plot .line())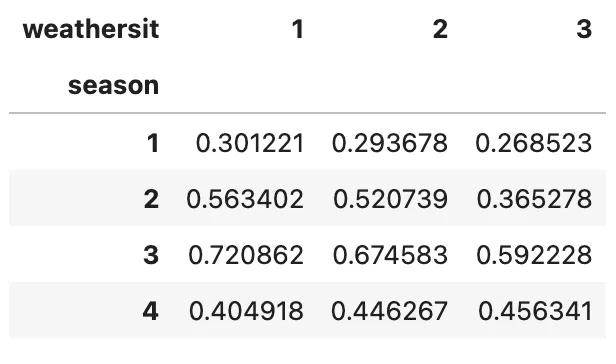
要するに、.unstack()メソッドは、MultiIndex DataFrameの最も内側のインデックス(この場合、weathersit)をアンスタックし、新しいDataFrameの列になります。これにより、比較のためにより意味のある結果を提供することができます。
DataFrameの最も外側のインデックスをアンスタックすることもできます。その場合、.unstack()メソッドの一部として引数level=0を指定します。これをどのように実現できるか見てみましょう。
(bike .groupby(['season', 'weathersit']) .agg('mean') .temp .unstack(level=0) .plot .line())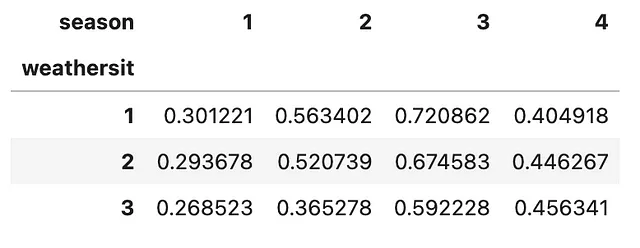
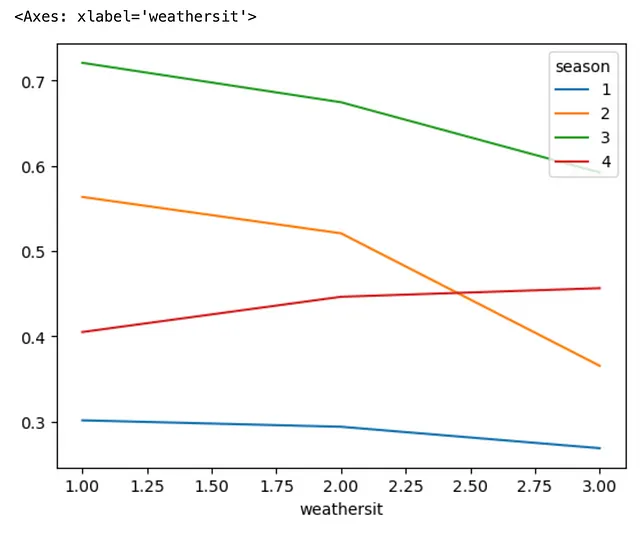
☕️ メソッド #8: .pipe()
私の観察によれば、オンラインで検索すると、一般の人々がこのメソッドをPandasのコードで実装することはほとんどありません。その理由の1つは、.pipe()は何とも説明のつかない不思議なオーラを持っており、初心者や中級者には親しみがないということです。Pandasのドキュメント²を見ると、「シリーズやデータフレームを期待するチェーン可能な関数を適用する」という短い説明があります。個人的には、この説明は少し混乱し、実際には役に立たないと思います。特に、チェーンを行ったことがない場合です。
要するに、.pipe()が提供するのは、データフレームを返す操作を実行するための明確な解決策が見つからない場合に、関数を使用してメソッドチェーンテクニックを継続する能力です。
.pipe()メソッドは関数を受け取り、それによってチェーンの外部にメソッドを定義し、そのメソッドを.pipe()メソッドの引数として参照することができます。
.pipe()を使用すると、カスタム関数の第1引数としてデータフレームまたはシリーズを渡すことができ、その関数は渡されたオブジェクトに適用され、その後に指定された追加の引数が続きます。
ほとんどの場合、.pipe()メソッド内部には、便宜上のための1行のラムダ関数が表示されます(つまり、チェーンプロセスでの変更後の最新のデータフレームにアクセスするため)。
簡単な例で説明します。次の質問について洞察を得たいとします。「2012年において、1シーズンあたりの稼働日の割合は、その年の総稼働日に対してどれくらいですか?」
(bike .loc[bike.index.year == 2012] .groupby(['season']) .workingday .agg(sum) .pipe(lambda x: x.div(x.sum())))ここでは、.pipe()を使用して関数をチェーンメソッドに挿入しています。 .agg(sum)を実行した後は、.div()を続けてチェーンすることはできません。以下のコードは機能しません。なぜなら、チェーンプロセスを通じての変更後の最新のデータフレームへのアクセスを失っているためです。
# うまくいきません!(bike .loc[bike.index.year == 2012] .groupby(['season']) .workingday .agg(sum) .div(...))ヒント: メソッドのチェーンを継続する方法が見つからない場合は、
.pipe()がどのように役立つか考えてみてください!ほとんどの場合、役立ちます!
あとがき
これでThe Underrated Gems 💎の第1部が終わりました!これらは以前あまり使用していなかったメソッドですが、コードを力ずくで書くという悪い癖のためかもしれません。「動けば十分」という考えでしたが、残念ながらそれは間違いです。
これらを適切に使用する方法を学ぶために時間を費やした後、それらは少なくとも命を救ってくれました!また、Matt Harrison氏と彼の著書「Effective Pandas³」に感謝したいと思います。これにより、私のPandasコードの書き方が大幅に変わりました。今では、コードがより簡潔で読みやすく、より理にかなっていると言えます。
この記事から何か有益な情報を得られた場合は、VoAGIでフォローしていただけると幸いです。週に1つの記事で自分自身を最新の情報に保ち、他の人よりも先を行くことができます!
私とつながる!
- LinkedIn 👔
- Twitter 🖊
参考文献
- Fanaee-T, Hadi. (2013). Bike Sharing Dataset. UCI Machine Learning Repository. https://doi.org/10.24432/C5W894.
- Pandasドキュメント: https://pandas.pydata.org/docs/reference/frame.html
- Matt HarrisonによるEffective Pandas: https://store.metasnake.com/effective-pandas-book
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「データアクセスはほとんどの企業で大きな課題であり、71%の人々が合成データが役立つと考えています」
- 「データを分析するためにOpenAIのコードインタープリタを使う方法」
- データサイエンスにおけるツールに依存しない方向へ:SQLのCase WhenとPandasのWhere
- 「私のデータサイエンスキャリアの2年後に発見した、Jupyter Notebookの5つの裏技」
- 「データサイエンス、機械学習、コンピュータビジョンプロジェクトを強化する 効果的なプロジェクト管理のための必須ツール」
- 「H1 2023 アナリティクス&データサイエンスの支出とトレンドレポート」
- 「2023年の機械学習モデルにおけるトップな合成データツール/スタートアップ」
