「トルコ地震ツイートに対する感情分析」
Turkish Earthquake Tweet Sentiment Analysis

感情分析は、与えられたテキストをその感情によってタグ付けするために使用される自然言語処理の技術です。感情は通常、ポジティブ、ネガティブ、または中立といった形で表されます。
通常、感情分析はマーケティングにおいて顧客のニーズをよりよく考慮するために使用され、特定の製品について人々がどのように考えているかを監視し、予想されるトレンドに関する情報を抽出してマーケティング戦略を改善するための手がかりを得るために使用されます。マーケティング保険においても感情分析は使用されますが、それだけでなくリスク評価にも役立ちます。ツイートから感情をモデリングすることで、保険リスクモデリングに使用できるリスクファクターを構築する機会があります。次のジョブは、TextBlobベンチマークツールを使用してトルコ地震ツイートに適用された感情分析の例です。ハギングフェイスハブから取得したファインチューニングされた事前学習モデルと比較されています。このノートブックでコードをフォローすることができます。
Hugging Faceとは何ですか?
- PyTorch LSTM — 入力、隠れ状態、セル状態、および出力の形状
- 『3Dディープラーニングへの道:Pythonでの人工ニューラルネットワーク』
- 「Google AIの新しいパラダイムは、多段階の機械学習MLアルゴリズムの組成コストを削減して、強化されたユーティリティを実現する方法は何ですか」
Hugging Faceは、人工知能を民主化するために構築されたプラットフォームで、データサイエンティストや機械学習エンジニアがモデルやデータセットを共同で作成し、アプリケーションを展開する機会を提供しています。
まず、私はKaggleから2023年2月に発生したトルコ地震に関するツイートデータセットを取得しました。
次の図では、感情ラベル以外の多くの特徴があります。
極性ラベルを持つ感情分析は、トレーニングセット上でモデルを適合させ、テストセット上でそのパフォーマンスを評価することで、テキスト分類タスクと関連付けることができます。これにより、同じ構造の他の未知のデータでも使用できるようになります。しかし、このデータセットではモデルをトレーニングするためのラベルがありません。そのため、データセットが何千もの行に及ぶ場合、手動のラベリング作業は時間がかかります。このため、自動的に極性ラベルを生成するツールを使用するアイデアがあります。
感情分析を実行するためには、いくつかのパッケージが利用可能です。よく知られているものには、TextBlob、VADER、Flairなどがあります。このジョブでは、ベンチマークとしてTextBlobを選択しました。その後、Hugging Faceから取得したファインチューニングされた事前学習された大規模言語モデル(LLM)の結果と比較しました。使用したモデルは、cardiffnlp/twitter-roberta-base-sentiment-latest、cardiffnlp/bert-base-multilingual-cased-sentiment-multilingual、philschmid/distilbert-base-multilingual-cased-sentiment-2です。
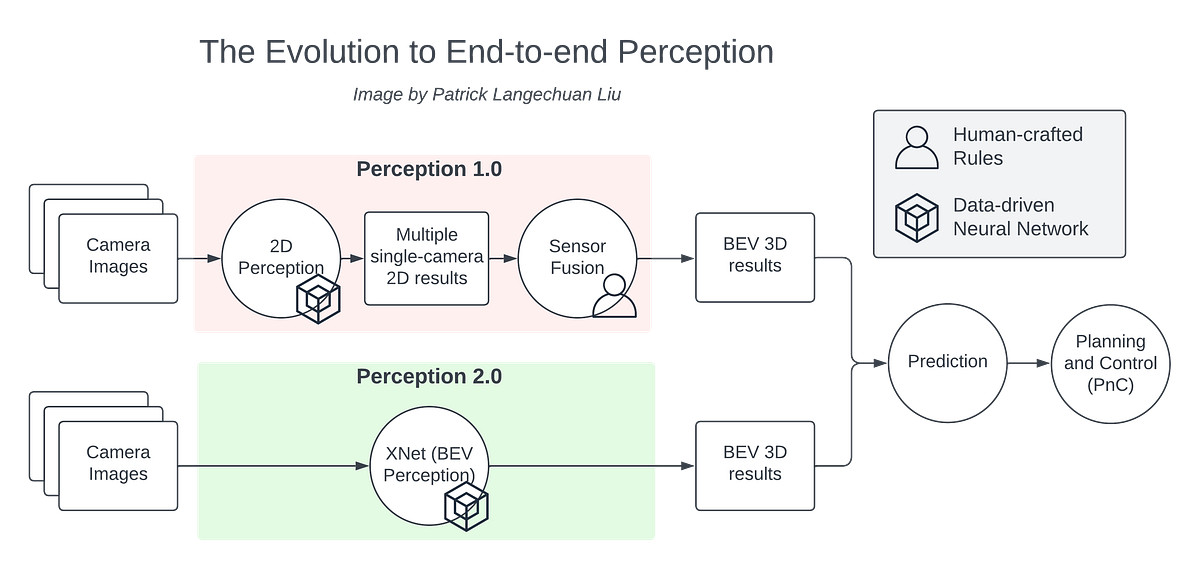
モデルに進む前に、データセットに戻ります。このデータセットには、16の変数(インデックスとしてアップロードされたIDを含む)と28844の行があり、一部の特徴にはn/aのデータがあります。ツイートは2023年2月7日から2023年2月26日までの間に記録されています。私は「date」、「text」、「user_location」という列に興味があり、これらの列を使用してデータをフィルタリングしました。
次の図では、言語検出から、ツイートが英語で書かれていることがわかります。

次の図では、「user_location」の特徴によってメッセージのトップ5の出どころがわかります。トルコはインドに次いで2位です。

この段階で、トルコに絞ったデータdf_.query(‘user_location==”Turkey”‘)をフィルタリングし、538行に減らし、少しクリーニングを行った後、感情分析を開始する準備が整いました。
最初のアプローチでは、ベンチマークツールとしてTextBlobを適用しました。
TextBlobはどのように機能しますか?
TextBlobは、いくつかのNLPタスクにアクセスするためのAPIを備えたPythonライブラリです。TextBlobの感情分析器は極性や主観性に使用することができます。極性は、[-1,1]の範囲にある浮動小数点の結果を提供します。-1はネガティブな感情を示し、+1はポジティブな感情を示します。私のジョブでは、中立的な感情には0の値も使用しました。主観性も、[0,1]の範囲にある浮動小数点の結果を提供します。主観性は一般的に個人の意見、感情、判断に使用されます。問題は、TextBlobが自身のボキャブラリにない単語を無視することで、極性を適用できる単語やフレーズに対してのみ注意を払い、それらを平均して最終的なスコアを得ることです。
この時点で、1つのツールだけを使うことの信頼性に自信がなく、結果の良さを理解することができないため、私は高度なツールを使用することにしました:大規模な言語モデル(BERT、RoBERTa、DistillBERT)を、Hugging Faceプラットフォームから取得した感情分析とテキスト分類のタスクで事前学習および微調整を行いました。
BERT、RoBERTa、DistillBERTの違いは何ですか?
BERTは、Googleの研究者によって2018年に発表された自然言語処理モデルで、Bidirectional Encoder Representation from Transformerの略です。これは基本的にはトランスフォーマーアーキテクチャのエンコーダースタックです。トランスフォーマーアーキテクチャは、エンコーダーサイドでセルフアテンション、デコーダーサイドでアテンションを使用するエンコーダーデコーダーネットワークです。トランスフォーマーのエンコーダーは双方向であり、文を左から右に読むことができます。トランスフォーマーのエンコーダーに文を入力すると、各単語の文脈表現(埋め込み)を出力します。エンコーダーは、マルチヘッドアテンションメカニズム(単語とその隣接単語の関係を見る方法)を使用して文の各単語の文脈を理解し、文の各単語の文脈表現を出力します。そのため、BERTは文脈に基づく埋め込みモデルです。事前学習のプロセスでは、BERTは2つの教師なし学習タスクを使用します:マスク言語モデリング(MLM)と次の文予測(NSP)。前者は文のいくつかの単語をランダムにマスクし、モデルに周囲の単語の文脈に基づいてマスクされた単語を予測させるものです。後者は、2つの文が連続しているかどうかを予測するようモデルを訓練します。このジョブで使用されるBERTは、ツイートに対してbert-base-multilingual-casedの微調整バージョンです。一方、BERTマルチリンガルベースモデルは、最大のWikipediaコーパスのマルチリンガルデータで事前学習されています。
RoBERTaは、Facebook AIの研究者によって開発されたRobustly Optimized BERT Pre-training Approachの略です。BERTと同様に、これもトランスフォーマーアーキテクチャに基づいており、入力シーケンスを処理し、文の単語の文脈化表現を生成するためにセルフアテンションメカニズムを使用しています。BERTとは異なり、より大規模なデータセットでトレーニングされ、トレーニング中にダイナミックマスキング技術を使用して、より堅牢な単語の表現を学習するのに役立ちます。このジョブで使用されるRoBERTaは、2021年1月から2021年12月までの約124Mのツイートからトレーニングされたtwitter-roberta-base-2021–124mの微調整バージョンです。
DistillBERTは、BERTの蒸留バージョンであり、大きなサイズを削減し、BERTの速度を高めることを目指しているため、より小さく高速なバージョンです。DistillBERTは、BERTと同様の一般的なアーキテクチャを使用していますが、エンコーダーブロックが少なく、事前学習中に知識の蒸留技術を使用して、より小さなモデルがより大きなモデルの振る舞いを模倣するように訓練されます。このジョブで使用されるDistillBERTは、amazon_reviews_multiデータセットでトレーニングされたdistilbert-base-multilingual-casedの微調整バージョンです。
結果を見てみましょう
私は3つの極性を使用しました:ポジティブ、ネガティブ、中立。
TextBlobの結果を示す最初のチャートを見ると、07/02/2023から21/02/2023までの間、中立の感情が時間とともに優勢です。RoBERTaを使用すると中立の感情は減少しましたが、それでも全ツイートの53.2%に関連しています。TextBlobを使用すると55%です。


中立の感情を除くと、TextBlobではネガティブな感情が15.6%しか占めておらず、ポジティブな感情(29.4%)に比べて非常に少ないという問題がありますが、LLMではネガティブな感情がポジティブな感情に勝っています。どのツールを信頼できるのでしょうか?私たちは確かに恐怖や不安などの典型的なネガティブな感情を引き起こすイベントに対処しているため、LLMによる結果の方がベンチマークよりも信憑性が高いと言えます。

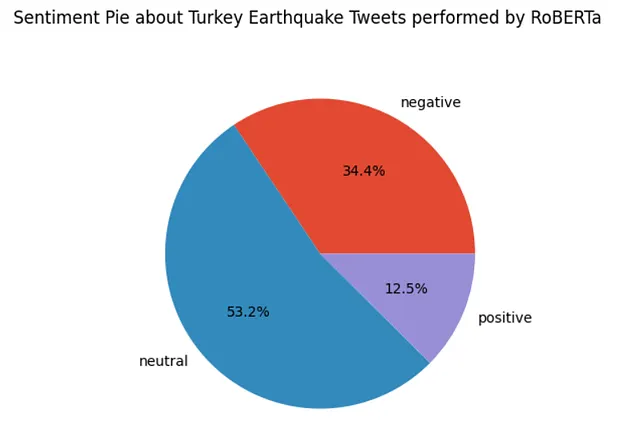
BERTの結果を見ると、ニュートラルな感情は35.9%減少し、埋めることができます。RoBERTaよりも極端な極性をより多く割り当てることができるようです。ネガティブな感情は47.2%、ポジティブな感情は16.9%です。BERTではネガティブな感情が時間の経過とともに勝ちます。一方、ニュートラルな感情は2023年2月7日、2023年2月8日、2023年2月15日のみ勝ちます。一方、2023年2月11日にはツイート間で感情の分布が均等になります。


感情分析を実行するために使用された最後のツールはDistillBERTであり、この状況ではニュートラルな感情は実質的に消えており、わずか2%です。ネガティブ極性は時間の経過とともに非常に大きく、74.9%です。また、この状況では結果に自信がありません。一方で、最も大きなネガティブ極性はイベントと一致しているため、一方でツイートはポジティブ/ネガティブの割り当てが難しく、多くのニュートラルな感情が妥当である可能性があります。


最終的な考察
ビッグデータの到来により、企業が市場のトレンドを考慮に入れるために、プライバシーを尊重しながらソーシャルネットワークを使用することは一般的な慣行となりました。この場合、利用可能なデータ量が少ない極端なイベントに関連するデータセットを使用しました。
微調整済みの事前学習モデルは興味深い結果を示し、従来の手法を超え、一方で手動でラベル付けされた活動に費やされる計算時間を節約します。もう一方で、それらは独自のカスタムデータで事前学習モデルを微調整することで、信頼できる良い結果を提供します。この点については、企業は確かにこの方法を戦略に取り入れることができます。
参考文献
データセット
ノートブック
TextBlob
BERT
RoBERTa
DistillBERT

We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles