チューリングテスト、中国の部屋、そして大規模言語モデル
'Turing Test, Chinese Room, and Large Language Models'

チューリングテストはAIの分野での古典的なアイデアです。もともと模倣ゲームと呼ばれていたこのテストは、アラン・チューリングが1950年に「計算機械と知能」という論文で提案しました。このテストの目的は、機械が人間と同等(そしておそらく区別がつかないほど)の知的な振る舞いを示すかどうかを確認することです。
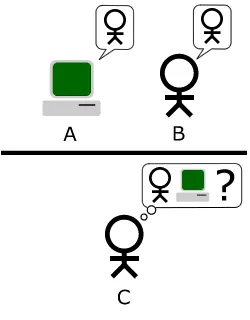
テストは次のように進行します:尋問者(プレイヤーC)は、コンピューターが接続されている他の2つの部屋(およびプレイヤー)と一緒に部屋に座っています。プレイヤーAはコンピューターであり、プレイヤーBは人間です。尋問者の役割は、プレイヤーAとプレイヤーBのどちらがコンピューターであり、どちらが人間であるかを判断することです。尋問者は自分のコンピューターに質問を入力し、書面での回答を受け取ることに制限されています。
テストでは、プレイヤーのハードウェアや脳の仕組みには触れず、知的な振る舞いをテストします。十分に知的なコンピューターは、人間として見せかけることができるとされています。
チューリングテストは、長年にわたり多くの議論と論争を引き起こし、ChatGPTなどの現在の大規模言語モデル(LLM)にこのテストを中心に置くことは有益かもしれません。
- Benfordの法則が機械学習と出会って、偽のTwitterフォロワーを検出する
- ドレスコードの解読👗 自動ファッションアイテム検出のためのディープラーニング
- 将来のアプリケーションを支える大規模言語モデル(LLM)の力
LLMはチューリングテストに合格するのでしょうか?
この問いに取り組む前に、私は私たちが自然の生物であること(時々忘れがちなこと)を指摘したいと思います。私たちは自然選択を通じて進化し、進化の歴史に由来するさまざまな特異点があります。
そのような特異点の一つは、無生物に代理能力を持たせることへの素早い傾向です。車を蹴ったり、「とうとう始まるのか!?」と叫んだりしたことはありませんか?また、ChatGPTのユーザーの中には、「お願いします」という言葉でプロンプトを始める人がどれだけいるでしょうか?それはただのプログラムですし、あなたが「アラン・チューリングについて教えてください」とプロンプトしたのか、「アラン・チューリングは誰ですか」とプロンプトしたのか、私はそれほど気にもしません。
しかし、それは私たちです。私たちはさまざまな出会った物にさまざまな特性を帰属します。なぜでしょうか?基本的には、これは自然との対処に役立った生存の恩恵があったのかもしれません。
1980年、哲学者ジョン・シアルは、チューリングテストが知能の尺度としての妥当性に関して優れた議論を提案しました。中国の部屋の論証(心、脳、およびプログラム)は、プログラムを実行するコンピューターは、どんなに知的で人間らしい振る舞いをしても、本当の意味で心や理解を持つことはできない、というものです。
論証の進行は次のようになります:誰かが中国語を理解しているかのように振る舞うAI(おそらくLLM?)を作成したとします。

プログラムは中国の文字を入力とし、コンピューターコードに従って中国の文字を出力します。そして、コンピューターはそれを非常に説得力のある方法で行い、チューリングテストに合格します。人々はコンピューターが生身の中国語話者であると信じ込みます。それは中国語でのあらゆる質問に対して答えを持っています。
シアルは問いました:この機械は本当に中国語を理解しているのか、それとも中国語を理解する能力をシミュレートしているのか?
うーん…
さて、私が部屋に入り、コンピューターを置き換えるとしましょう。

私は中国語を話せないことを保証します(残念ながら)。しかし、私にはコンピュータープログラムの英語版(うーん、大きな本ですが)の本が与えられます。私にはたくさんの下敷きと鉛筆も与えられます。ドアにはスロットがあり、人々は中国語で質問の用紙を送ることができます。
私はその中国語の文字を手元の指示書に従って処理します。それには時間がかかりますが、最終的には忍耐力を持って、紙に書かれた中国語の回答を提供します。そして、その返信をスロットから送り出します。
部屋の外の人たちは、「あの中の人は中国語を話すんだな」と思っています。しかし、私は絶対に中国語を話せません。
セアルは主張しました。私とコンピューターの間には実際には何の違いもないのだと。私たちは両方ともステップバイステップのマニュアルに従っており、中国語での知的な会話として解釈される振る舞いを生み出しているだけです。しかし、私もコンピューターも中国語を話し、理解することはありません。
そして、セアルは理解がない限り、考えることはないと主張しました。彼の巧妙な議論は激しい論争を引き起こしました。「まあ、システム全体 — 私、本、鉛筆 — は中国語を理解している」、「反対だ、システムはただの人間と物の束だ」、「でも…」などと続きました。
現在のChatGPTなどのLLMは、会話をするのが非常に上手です。チューリングテストに合格しているのでしょうか?それは意見の問題であり、私は「いや、全然」と「当然だよ」という意見があると思います。私自身の限られたLLMの経験からは、彼らは近いですが、完全には人間ではないと気づくことがあります。
しかし、たとえLLMがチューリングテストに合格したとしても、私はセアルの部屋を思い出さずにはいられません。
私たちが今見ているのが実際の意識であるかどうか疑問です。
未来については、経営コンサルタントのピーター・ドラッカーの言葉を借りて言いたいと思います。「未来を予測しようとすることは、後ろ窓から外を見ながら夜の暗い道路を車で走ろうとすることと同じです」。

(そしてもし彼らがいつか実際の意識を持つようになったとしても、それは私たちとは異なるものになるでしょう…)
死者を見る、または知性ですが、私たちが知っているものとは異なります
この絵を見てください、グラント・ウッドによる有名な絵画「アメリカン・ゴシック」:
VoAGI.com
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






