「LLMsを使用した用語の翻訳(GPTとVertex AI/Google Bard)」
Translation of terms using LLMs (GPT and Vertex AI/Google Bard)
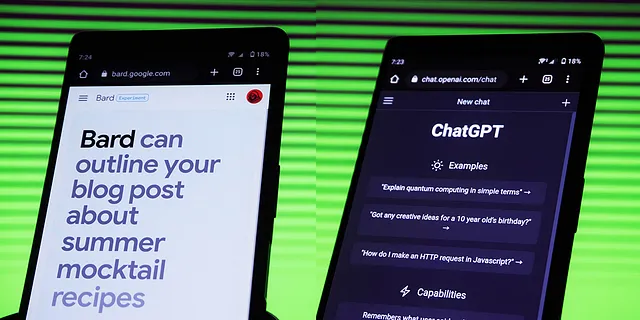
ChatGPTのようなLLMは、人間よりも正確に翻訳を行うことができるのでしょうか?私たちが使用できるLLMのオプションにはどのようなものがありますか?生成的AIを使用して異なる言語での翻訳を行う方法について詳しく学びましょう。
背景
この記事を書いている時点で、私はほぼ10年間データとローカリゼーションに関わってきました。クラスタリング、分類、感情分析など、さまざまな形式の人工知能についての経験があります。機械翻訳(MT)はローカリゼーションでよく使用されます。Google翻訳にテキストを入力して他の言語に翻訳するように要求すると考えてください。私の経験では、機械翻訳は一般的に80%の正確さを持っていますが、依然として人間が翻訳のミスを見直し修正する必要があります。
ChatGPTやGoogle Bardなどの大規模言語モデル(LLM)の台頭により、LLMに追加の文脈(定義や品詞など)を提供することで、人間の翻訳により近い精度を得ることができるかもしれません。
- 『George R.R.マーティン氏と他の作家がOpenAIを訴える』
- 「環境持続可能性のために生成型AIのワークロードを最適化する」
- NVIDIA Studio LineupにRTX搭載のMicrosoft Surface Laptop Studio 2が追加されました
仮説
LLMはプロンプトベースの入力で動作します。つまり、プロンプトにできるだけ多くの情報と文脈を提供すれば、LLMからの出力が向上します。英語の用語とその定義、品詞のサンプルを与えられた場合、LLMが用語を異なる言語に翻訳する際の結果が改善されるかどうかを確認したいと思います。使用する2つのLLMは、GPT(OpenAI APIを介したJupyter Notebookを通じて)とVertex AI(Google BigQueryのML.GENERATE_TEXT関数を介して)です。後者はセットアップがより多く必要ですが、SQLのクエリコンソールで直接実行することができます。
LLMを使用して翻訳する
GPT
Jupyter NotebookにOpenAIのPythonライブラリをインストールして始めましょう
import sys !{sys.executable} -m pip install openaiデータフレームで作業するためにpandasをインポートします。先にインストールしたopenaiライブラリをインポートし、APIキーを設定します。データをデータフレームに読み込みます。一緒に進める場合は、私が使用するデータはこちらで見つけることができます。
import pandasimport openai openai.api_key = "YOUR_API_KEY" # APIキーを設定します df = pd.read_csv('mydata/terms_sample.csv')リストに、単語を翻訳したい言語を設定します。
languages = ['スペイン語(スペイン)', 'スペイン語(中南米)', 'ドイツ語', 'イタリア語', '日本語', '中国語(簡体)', 'フランス語'データフレームの行とリストの言語を繰り返し処理して、それぞれの用語を翻訳する関数を作成します。プロンプトは「メッセージ」セクションに入力されます。GPT 3.5を使用し、温度を非常に小さな数に設定してLLMから正確/創造的でない応答を得るようにします。
def translate_terms(row, target_language): """用語を翻訳する""" user_message = ( f"以下の英語の用語を{target_language}に翻訳してください: '" + row['用語'] + "'。\n次に、より文脈を提供するための用語の定義を示します:\n" + row['定義'] + "'。\n次に、より文脈を提供するための用語の品詞を示します:\n" + row['品詞'] + "。\n翻訳では、用語のみを翻訳し、定義以外の追加のテキストは提供しないでください。" ) response = openai.ChatCompletion.create( model="gpt-3.5-turbo", messages=[ {"role": "system", "content": "あなたは英語の用語と定義を与えられた場合に、他の言語に翻訳する役に立つ翻訳アシスタントです。"}, {"role": "user", "content": user_message}, ], max_tokens=50, n=1, temperature=0.1 ) return response['choices'][0]['message']['content']最終的なステップは、リスト内の各言語に対してデータフレーム上で繰り返し翻訳関数を適用し、その言語に対応する用語の新しい列を作成することです。参考のために、完全なコードを以下に示します。
# 各言語に対して関数をデータフレームに適用する
for language in languages:
df[language+'_terms'] = df.apply(translate_terms, axis=1, args=(language,))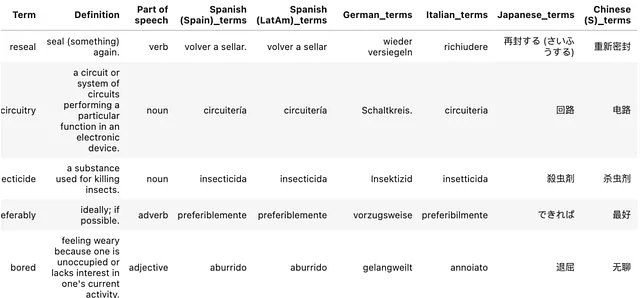
Google Bard / text-bisonm / Vertex AI
前と同じ用語を翻訳するために、Googleのtext-bisonモデル内のML.GENERATE_TEXT関数を使用します。このプロセスは少しリソースを必要としますが、一度セットアップされると、SQLクエリで直接LLMを呼び出すことができます。
セットアップ
Google Cloudのインフラストラクチャは個々のニーズに合わせてユニークですので、詳細なセットアップガイドは提供しません。代わりに、ボールを転がす方法についての高レベルな概要とリンクを提供します。
- Vertex AIのユーザーロールがサービスアカウントにアクセス可能になっていることを確認します。
- Google Cloudの指示に従ってリモートクラウド接続を設定します。
- リモートクラウド接続でLLMモデルを作成します。
- ML.GENERATE_TEXT関数を使用してLLMモデルを実行できるはずです。必要なパラメータを理解するために関数の引数を調べることをお勧めします。
- データを請求プロジェクトにアップロードしてクエリを実行できるようにします。
コード
以下に翻訳を生成するために使用されたコードを示します。自分の制限とクエリエンジンの制約の組み合わせのため、前のjupyter notebookと同じように言語の配列をループする代わりに、各言語のコードを個別に実行することを決めました(太字のテキストを手動で置き換える)。
DECLARE USER_MESSAGE_PREFIX STRING DEFAULT ( '英語の用語と定義が与えられた場合に、他の言語に用語を翻訳する役に立つ翻訳アシスタントです。'|| '\n\n' || '以下の英語の用語をフランス語に翻訳してください。定義も翻訳しないでください。'|| '\n\n' || '用語: ');DECLARE USER_MESSAGE_SUFFIX DEFAULT ( '\n\n' || '文脈を考慮するために用語の定義を以下に示します: '|| '\n\n');DECLARE USER_MESSAGE_SUFFIX2 DEFAULT ( '\n\n' || '文脈を考慮するために用語の品詞を以下に示します: '|| '\n\n');DECLARE USER_MESSAGE_SUFFIX3 DEFAULT ( '\n\n' || '用語のフランス語訳:');DECLARE languages ARRAY<string>;SET languages = ['スペイン語(スペイン)'、'スペイン語(ラテンアメリカ)'、'ドイツ語'、'イタリア語'、'日本語'、'中国語(簡体字)'、'フランス語'];SELECT ml_generate_text_result['predictions'][0]['content'] AS generated_text, ml_generate_text_result['predictions'][0]['safetyAttributes'] AS safety_attributes, * EXCEPT (ml_generate_text_result)FROM ML.GENERATE_TEXT( MODEL `YOUR_BILLING_PROJECT.YOUR_DATASET.YOUR_LLM`, ( SELECT Term, Definition, USER_MESSAGE_PREFIX || SUBSTRING(TERM, 1, 8192) || USER_MESSAGE_SUFFIX || SUBSTRING(Definition, 1, 8192) || USER_MESSAGE_SUFFIX2 || SUBSTRING(Part_of_speech, 1, 8192) || USER_MESSAGE_SUFFIX3 AS prompt FROM `YOUR_BILLING_PROJECT.YOUR_DATASET.terms_sample` ), STRUCT( 0 AS temperature, 100 AS max_output_tokens ) );結果の解釈
注意:英語以外のこれらの言語は話せないため、私の結論は参考程度にお考えください。
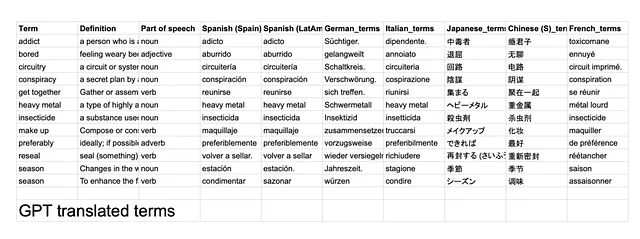
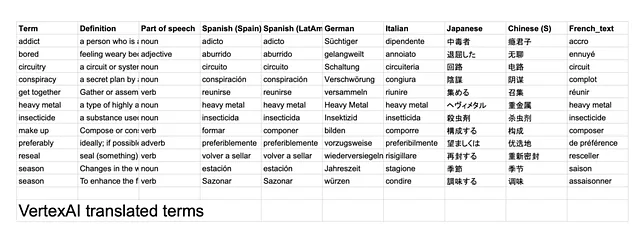
結果はこちらで見つけることができます。私がメモしたいくつかの発見:
- 両方のLLMによる翻訳のうち、47 / 84(56%)が完全に同じでした。- GPTは単語の末尾に(.)ピリオドを頻繁に付けていました。これらを削除することで、一致率が63%に向上します。
- 日本語とフランス語が2つのLLMの間で最も一致しない翻訳であるようです。
- GPTは、化粧品の意味で「make up」という用語を理解しているようで、これは懸念材料です。つまり、翻訳を行う前にその用語の定義と品詞を活用していないようです。- これは、私のプロンプトの構造が最適ではなかったためかもしれません。例えば、用語の前に定義を提供して、LLMがまずその情報を処理できるようにすることができます。
- ヘビーメタル(固有名詞)は、特にドイツ語では、GPTによって文字通りに翻訳されるようです。この場合、音楽ジャンルに対応しない用語に翻訳されました。
最終的には、両方のLLMにはそれぞれ利点と欠点があると言えるでしょう。GPTはPythonで簡単にセットアップして実行できますが、Vertex AIはプロンプトをより明確に理解し、翻訳を行う前に全体の文脈を把握します。LLMは通常の機械翻訳よりも優れた仕事をすると思います。なぜなら、彼らはプロンプトの追加の文脈を処理できるからです。どう思いますか。もっと良くすることができたでしょうか?
元の記事はhttps://shafquatarefeen.comで公開されています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






