「トランスフォーマーの簡素化:理解できる単語を使った最先端の自然言語処理(NLP)-パート2- 入力」
Transformer Simplification Advanced Natural Language Processing (NLP) Using Understandable Vocabulary - Part 2 - Input
トランスフォーマの入力の構築方法を詳しく調べる
入力
ドラゴンは卵から孵り、赤ちゃんはお腹から飛び出し、AIによって生成されたテキストは入力から始まります。私たちは皆、どこかでスタートを切らなければなりません。どのような入力が必要かは、そのタスクに依存します。言語モデルを構築している場合、関連するテキストを生成する方法を知っているソフトウェア(トランスフォーマのアーキテクチャは様々なシナリオで役立ちます)の場合、入力はテキストです。それにもかかわらず、コンピュータはどの種類の入力(テキスト、画像、音声)でも受け取ってそれをどのように処理するかを魔法のように知っているわけではありません。
おそらく、言葉にはあまり得意ではないが数字には長けている人を知っていると思います。コンピュータもそれに似ています。テキストを直接CPU/GPU(計算が行われる場所)で処理することはできませんが、数字で作業することはできます!まもなく見るように、これらの単語を数値として表現する方法は秘密のソースの重要な要素です。
トークナイザー
トークナイゼーションは、機械がより良く利用できるように、コーパス(持っているすべてのテキスト)をより小さな部分に変換するプロセスです。たとえば、10,000のウィキペディアの記事のデータセットがあるとします。それぞれの文字を取り、変換(トークナイズ)します。テキストをトークナイズするためのさまざまな方法がありますが、以下のテキストをOpenAiのトークナイザーでどのように行うかを見てみましょう:
「多くの単語は1つのトークンにマップされますが、一部はそうではありません:不可分です。
- 「Declarai、FastAPI、およびStreamlitを使用してLLMチャットアプリケーションを展開する」
- Google AIが教育環境でのオーディオブックに対するソーシャル意識を持つ時間的因果関係を考慮したレコメンダーシステム「STUDY」を紹介します
- スウィン・トランスフォーマー | モダンなコンピュータビジョンタスク
絵文字のようなUnicode文字は、基礎となるバイトを含む複数のトークンに分割される場合があります:🤚🏾
互いに隣り合ってよく見られる文字のシーケンスは、グループ化される場合があります:1234567890″
これがトークナイズの結果です:

ご覧の通り、おおよそ40の単語(句読点をどのように数えるかによります)があります。これらの40の単語から64のトークンが生成されました。トークンは、「Many, words, map」といった単語全体であることもあれば、「Unicode」といった単語の一部であることもあります。なぜ単語全体をより小さな部分に分割するのでしょうか?なぜ文を分割するのでしょうか?それらを連絡しないでおくこともできました。最終的には、どのようにトークンが3文字長いのか30文字長いのか、コンピュータの視点ではどのような違いがあるのでしょうか?トークンはモデルの学習を助けます。なぜなら、テキストが私たちのデータであり、トークンはそのデータの特徴だからです。これらの特徴をエンジニアリングするさまざまな方法は、パフォーマンスの違いをもたらします。たとえば、「Get out!!!!!!!」という文では、「!」が複数ある場合と1つだけの場合とは異なるかどうかを決定する必要があります。技術的には文全体を保持することもできましたが、群衆を見るか個々の人を個別に見るか、どちらのシナリオでより良い洞察を得られるでしょうか?
トークンがあるので、単語を置き換えてインデックス(数値)を使用するためのルックアップ辞書を作成することができます。たとえば、データセット全体が「Where is god」という文の場合、次のような語彙を作成することができます。これは、単語とそれを表す単一の番号のキー:値のペアです。毎回、単語全体を使用する必要はありません。番号を使用できます。たとえば:{Where: 0, is: 1, god: 2}。単語「is」が出現するたびに、それを1で置き換えます。トークナイザーのさらなる例については、Googleが開発したものをチェックしたり、OpenAIのTikTokenを試したりしてみてください。
ワード・トゥ・ベクター
直感単語を数値で表現するための旅路で素晴らしい進展を遂げています。次のステップは、これらのトークンから数値的な意味表現を生成することです。そのために、Word2Vecと呼ばれるアルゴリズムを使用することができます。詳細は現時点では非常に重要ではありませんが、主なアイデアは、任意のサイズの数値のベクトル(単純化して考えると、通常のリスト)を取り、この数値のリストが単語の意味を表すものであるべきだということです。たとえば、[-2、4、-3.7、41…-0.98]のような数値のリストが、単語の意味表現を保持していると想像してください。これらのベクトルを2Dグラフにプロットすると、類似した用語は類似した用語よりも近くになります。
以下のHTMLを日本語に翻訳します(HTMLコードは結果に含めます):
この写真(ここから取得)でわかるように、「Baby」は「Aww」と「Asleep」に近く、「Citizen」/「State」/「America’s」もある程度グループ化されています。 *2Dワードベクトル(2つの数字のリスト)は、1つの単語についても正確な意味を保持することはできません。著者は512個の数字を使用しました。512次元で何かをプロットすることはできないため、PCAという方法を使用して次元数を2つに減らし、元の意味をできるだけ保持しようとします。このシリーズの第3部では、それがどのように行われるかについて少し詳しく説明します。
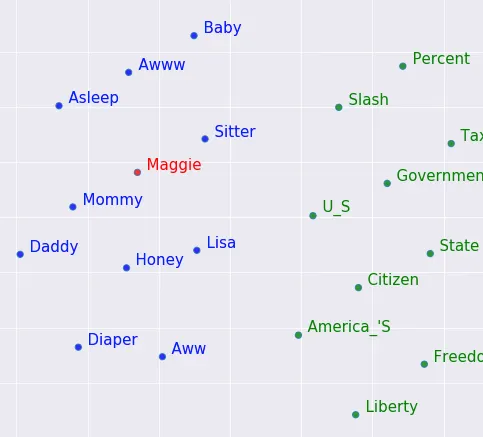
うまくいきます!実際には、意味を保持する数値のリストを生成できるモデルをトレーニングすることができます。コンピュータは、赤ちゃんが泣き叫ぶ、睡眠不足(超かわいい)小さな人間であることを知りませんが、通常は「aww」の周りで「baby」という単語をより頻繁に見ます。「State」と「Government」よりも頻繁にです。それがどのようにして起こるのかについては、後で詳しく書きますが、興味がある場合は、これをチェックするのに良い場所かもしれません。
これらの「数値のリスト」は非常に重要ですので、ML用語では埋め込みという独自の名前が付けられます。なぜ埋め込みを使用するのか?なぜなら、埋め込み(創造的な)を実行しているからです。これは、1つの形式(単語)から別の形式(数値のリスト)へのマッピング(変換)のプロセスです。これらはたくさんあります()。これ以降、単語を埋め込みと呼びます。説明したように、埋め込みは、トレーニングされた単語を表す任意の単語の意味を保持する数値のリストです。
PyTorchを使用した埋め込みの作成
まず、ユニークなトークンの数を計算します。簡単のために、2とします。Transformerアーキテクチャの最初の部分である埋め込み層の作成は、次のコードを書くだけで簡単です:
*一般的なコードの注釈 — このコードとその慣習を良いコーディングスタイルとして受け取らないでください。理解しやすくするために特に書かれています。
コード
import torch.nn as nnvocabulary_size = 2num_dimensions_per_word = 2embds = nn.Embedding(vocabulary_size, num_dimensions_per_word)print(embds.weight)---------------------output:Parameter containing:tensor([[-1.5218, -2.5683], [-0.6769, -0.7848]], requires_grad=True)これで、この場合は2×2の行列である埋め込み行列が得られました。この行列は、正規分布N(0,1)から導かれたランダムな数値で生成されます(例:平均0、分散1の分布)。requires_grad=Trueに注目してください。これは、これらの4つの数値が学習可能な重みであることをPyTorchの言語で示しています。これらは学習プロセスでカスタマイズされ、モデルが受け取るデータをよりよく表現するために変更されます。
より現実的なシナリオでは、データセット全体を数値で表す10,000×512の行列に近いものが期待されます。
vocabulary_size = 10_000num_dimensions_per_word = 512embds = nn.Embedding(vocabulary_size, num_dimensions_per_word)print(embds)---------------------output:Embedding(10000, 512)*おもしろい事実(もっと楽しいことを考えることができます)、言語モデルでは数十億のパラメータを使用することがあります。この初期の、あまりクレイジーではないレイヤーには、10,000×512のパラメータが含まれており、これは500万のパラメータです。このLLM(Large Language Model)は難しいものです。多くの計算が必要です。ここでのパラメータとは、それらの数値(-1.525など)のことを指しますが、変更される可能性があり、トレーニング中に変更されます。これらの数値は、機械の学習です。後で入力を与えると、入力をこれらの数値と乗算し、良い結果が得られることを期待します。何を知っていますか、数値は重要です。重要なものは独自の名前を持つので、これらは単なる数値ではなく、パラメータです。
なぜ512個もの数値を使用するのでしょうか?5個ではなく?なぜなら、より多くの数値はおそらくより正確な意味を生成できる可能性があるからです。素晴らしい、小さなことを考えるのをやめて、100万個を使いましょう!なぜですか?なぜなら、より多くの数値はより多くの計算、より多くの計算能力、より高価なトレーニングなどを意味します。512は中間地点として良いとされています。
シーケンスの長さ
モデルの学習時には、たくさんの単語をまとめて入力します。これは計算効率がよく、モデルがより多くの文脈を把握するのに役立ちます。前述の通り、すべての単語は512次元のベクトル(512個の数値のリスト)で表され、モデルに入力を送るたびに(フォワードパスとも呼ばれる)、1つの文だけでなく、複数の文を送ります。たとえば、50単語のシーケンスをサポートすることにしました。これは、文の中のx個の単語を取り、xが50より大きい場合は分割して最初の50個だけを取り、xが50より小さい場合でも、サイズが完全に同じでなければならないためです(なぜかはすぐに説明します)。これを解決するために、パディングという特別なダミー文字列を残りの文に追加します。たとえば、7単語の文をサポートし、文が「Where is god」である場合、4つのパディングを追加して、モデルへの入力は「Where is god <PAD> <PAD> <PAD> <PAD>」となります。実際には、通常、文が始まる位置と終わる位置をモデルが認識できるように、少なくとも2つ以上の特別なパディングを追加します。したがって、実際には「<StartOfSentence> Where is god <PAD> <PAD> <EndOfSentence>」のようになります。
* なぜすべての入力ベクトルのサイズが同じでなければならないのでしょうか?ソフトウェアには「期待値」があり、行列にはさらに厳しい期待値があります。思いのままの「数学的な」計算を行うことはできません。一定のルールに従わなければならず、そのルールの1つが適切なベクトルサイズです。
位置エンコーディング
直感私たちは今、語彙の中の単語を表現(および学習)する方法を持っています。単語の位置をエンコードしてさらに良くしましょう。なぜこれが重要なのでしょうか?次の2つの文を考えてみましょう。
1. The man played with my cat2. The cat played with my man
これらの2つの文を正確に同じ埋め込みを使って表現することができますが、文には異なる意味があります。順序が重要ではないデータを考えることができます。何かの合計を計算している場合、どこから始めても問題ありません。言語では、順序は通常重要です。埋め込みは意味的な意味を持っていますが、正確な順序の意味はありません。これらの埋め込みは、元々ある言語論的なロジックに基づいて作成されたものです(例えば、babyはsleepに近く、stateには近くない)。しかし、同じ単語でも複数の意味を持ち、さらに重要なのは、異なる文脈では異なる意味を持つことがあるということです。
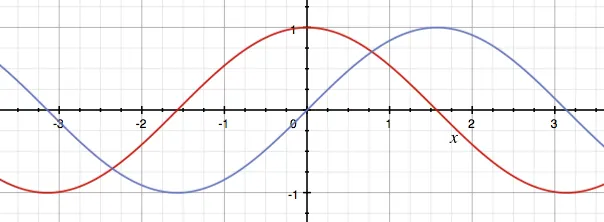
単語を順序なしのテキストとして表現するだけでは十分ではありません。これを改善することができます。著者たちは、埋め込みに位置エンコーディングを追加することを提案しています。これは、各単語に対して位置ベクトルを計算し、2つのベクトルを加算(合計)することで行います。位置エンコーディングベクトルは、加算できるように同じサイズでなければなりません。位置エンコーディングの式は、2つの関数を使用します。偶数の位置にはサイン関数(たとえば、0番目の単語、2番目の単語、4番目の単語、6番目の単語など)を使用し、奇数の位置にはコサイン関数(たとえば、1番目の単語、3番目の単語、5番目の単語など)を使用します。
視覚化これらの関数(赤色のサイン、青色のコサイン)を見ると、なぜこれらの2つの関数が特に選ばれたのかを想像できるかもしれません。関数間にはいくつかの対称性があります。単語とそれに続く単語の間にも対称性があり、これによって関連する位置をモデルが(表現)できるようになります。また、これらの関数は-1から1までの値を出力し、非常に安定した数値であります(非常に大きくならないか、非常に小さくならない)。
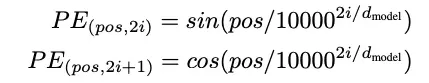
上記の式では、上の行は0から始まる偶数の番号(i = 0)を表し、偶数番号(2 * 1、2 * 2、2 * 3など)で続きます。2行目は同様に奇数の番号を表します。
各位置ベクトルは、次元数(この場合は512)の数値ベクトルであり、0から1までの数値を持ちます。
コード
from math import sin, cosmax_seq_len = 50 number_of_model_dimensions = 512positions_vector = np.zeros((max_seq_len, number_of_model_dimensions))for position in range(max_seq_len): for index in range(number_of_model_dimensions//2): theta = pos / (10000 ** ((2*i)/number_of_model_dimensions)) positions_vector[position, 2*index ] = sin(theta) positions_vector[position, 2*index + 1] = cos(theta)print(positions_vector)---------------------output:(50, 512)最初の単語を出力すると、0と1が交互に表示されます。
print(positions_vector[0][:10])---------------------output:array([0., 1., 0., 1., 0., 1., 0., 1., 0., 1.])2番目の数値はすでに多様性があります。
print(positions_vector[1][:10])---------------------output:array([0.84147098, 0.54030231, 0.82185619, 0.56969501, 0.8019618 , 0.59737533, 0.78188711, 0.62342004, 0.76172041, 0.64790587])*コードのインスピレーションはここから得られました。
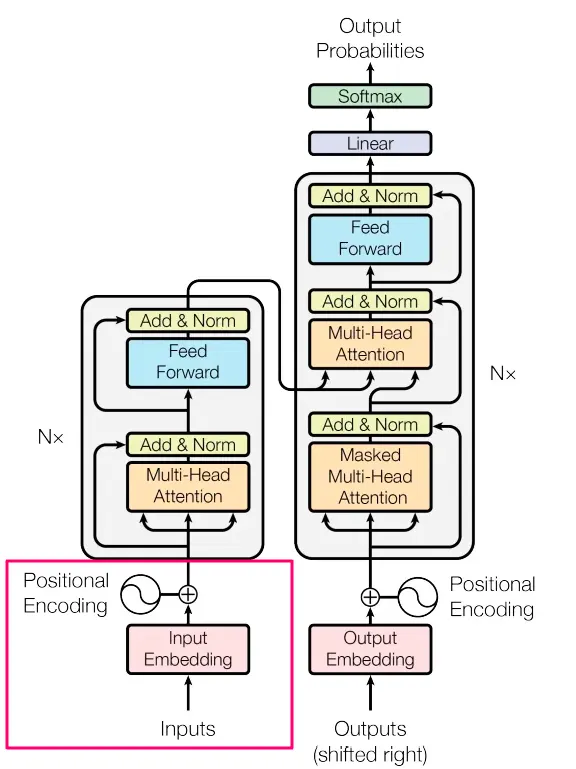
異なる位置は異なる表現を生み出すことがわかりました。このセクションの入力全体(下の赤い四角で囲まれた部分)を最終的に完成させるために、位置行列の数値を入力エンベッディング行列に追加します。この結果、埋め込みと同じサイズの行列が得られますが、この時点では数値には意味と順序が含まれています。

まとめこれでシリーズの第1部が終了しました(赤い四角で囲まれています)。モデルが入力を取得する方法について話しました。テキストを特徴(トークン)に分解し、それらを数値(埋め込み)として表現し、これらの数値に位置符号化をスマートに追加する方法を見ました。
次の部分では、エンコーダーブロックの異なるメカニズムに焦点を当てます(最初の灰色の四角形)、各セクションが異なる色の四角形を説明します(例:マルチヘッドアテンション、追加&正規化など)。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 『強化学習における大規模な行動空間を処理する5つの方法』
- このNYUとGoogleの論文は、クロスモーダル表現におけるシーケンス長の不一致を克服するための共同音声テキストエンコーダの仕組みを説明しています
- 「機械に学習させ、そして彼らが私たちに再学習をさせる:AIの構築の再帰的性質」
- 『Photoshopを越えて:Inst-Inpaintが拡散モデルでオブジェクト除去を揺るがす』
- 「トランスフォーマーの単純化:あなたが理解する言葉を使った最先端の自然言語処理(NLP)— パート1 — イントロ」
- テキストからビデオ生成 ステップバイステップガイド
- 「Transformerベースの拡散モデルによる画像生成の革新的なアーキテクチャイノベーションを実現するDiffusion Transformers(DiTs)」






