自己対戦を通じてエージェントをトレーニングして、三目並べをマスターする
Training the agent through self-play to master Tic-Tac-Toe.
驚くべきことに、ソフトウェアエージェントはゲームに飽きることがありません。
ああ、小学校!これは私たちが読み書きや算数、そして最適な三目並べのプレイなど、貴重なスキルを学んだ時期です。
友達と三目並べを楽しむために、先生に見つからずにプレイするのは芸術です。机の下でゲームシートをこっそりと渡す必要があり、同時に授業に集中しているように見せる必要があります。楽しさはおそらくゲームそのものよりも秘密の作戦にあったのでしょう。
教室で見つかることを避ける技術をソフトウェアエージェントに教えることはできませんが、ゲームをマスターするためにエージェントを訓練することはできるでしょうか?
以前の記事では、自己対戦を通じてゲームSumTo100を学ぶエージェントについて学びました。それは状態の価値を表示することができる簡単なゲームであり、エージェントがゲームを学習する方法についての直感を構築するのに役立ちました。三目並べでは、はるかに大きな状態空間に取り組んでいます。
- AI/MLを活用してインテリジェントなサプライチェーンを構築するための始め方
- 「検索強化生成システムのパフォーマンスを向上させるための10の方法」
- 「LLMプロンプティングにおける思考の一端:構造化されたLLM推論の概要」
このリポジトリでPythonのコードを見つけることができます。トレーニングを実行するスクリプトはlearn_tictactoe.shです:
#!/bin/bashdeclare -i NUMBER_OF_GAMES=30000declare -i NUMBER_OF_EPOCHS=5export PYTHONPATH='./'python preprocessing/generate_positions_expectations.py \ --outputDirectory=./learn_tictactoe/output_tictactoe_generate_positions_expectations_level0 \ --game=tictactoe \ --numberOfGames=$NUMBER_OF_GAMES \ --gamma=0.95 \ --randomSeed=1 \ --agentArchitecture=None \ --agentFilepath=None \ --opponentArchitecture=None \ --opponentFilepath=None \ --epsilons="[1.0]" \ --temperature=0 dataset_filepath="./learn_tictactoe/output_tictactoe_generate_positions_expectations_level0/dataset.csv" python train/train_agent.py \ $dataset_filepath \ --outputDirectory="./learn_tictactoe/output_tictactoe_train_agent_level1" \ --game=tictactoe \ --randomSeed=0 \ --validationRatio=0.2 \ --batchSize=64 \ --architecture=SaintAndre_1024 \ --dropoutRatio=0.5 \ --learningRate=0.0001 \ --weightDecay=0.00001 \ --numberOfEpochs=$NUMBER_OF_EPOCHS \ --startingNeuralNetworkFilepath=None for level in {1..16}do dataset_filepath="./learn_tictactoe/output_tictactoe_generate_positions_expectations_level${level}/dataset.csv" python preprocessing/generate_positions_expectations.py \ --outputDirectory="./learn_tictactoe/output_tictactoe_generate_positions_expectations_level${level}" \ --game=tictactoe \ --numberOfGames=$NUMBER_OF_GAMES \ --gamma=0.95 \ --randomSeed=0 \ --agentArchitecture=SaintAndre_1024 \ --agentFilepath="./learn_tictactoe/output_tictactoe_train_agent_level${level}/SaintAndre_1024.pth" \ --opponentArchitecture=SaintAndre_1024 \ --opponentFilepath="./learn_tictactoe/output_tictactoe_train_agent_level${level}/SaintAndre_1024.pth" \ --epsilons="[0.5, 0.5, 0.1]" \ --temperature=0 declare -i next_level=$((level + 1)) python train/train_agent.py \ "./learn_tictactoe/output_tictactoe_generate_positions_expectations_level${level}/dataset.csv" \ --outputDirectory="./learn_tictactoe/output_tictactoe_train_agent_level${next_level}" \ --game=tictactoe \ --randomSeed=0 \ --validationRatio=0.2 \ --batchSize=64 \ --architecture=SaintAndre_1024 \ --dropoutRatio=0.5 \ --learningRate=0.0001 \ --weightDecay=0.00001 \ --numberOfEpochs=$NUMBER_OF_EPOCHS \ --startingNeuralNetworkFilepath="./learn_tictactoe/output_tictactoe_train_agent_level${level}/SaintAndre_1024.pth" doneスクリプトは2つのプログラムを呼び出すことを繰り返します:
- generate_positions_expectations.py:試合をシミュレートし、割引された期待収益でゲームの状態を保存します。
- train_agent.py:最新のデータセットでいくつかのエポックにわたってニューラルネットワークのトレーニングを行います。
トレーニングサイクル
エージェントによるゲームの学習は、試合の生成とゲームの状態から試合の結果を予測するためのトレーニングのサイクルを通じて行われます:
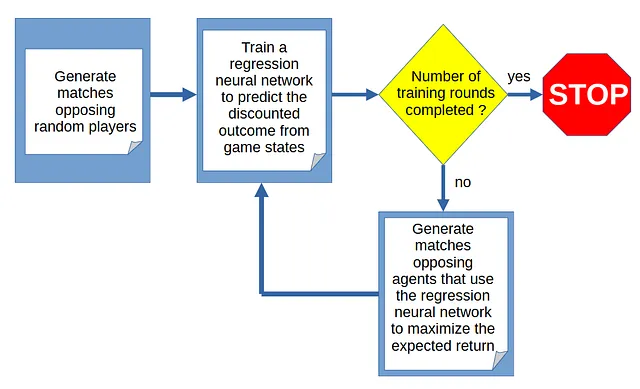
試合の生成
サイクルは、ランダムなプレイヤー間の試合のシミュレーションから始まります。つまり、与えられたゲームの状態で合法的なアクションのリストからランダムに選択するプレイヤーです。
なぜランダムに試合を生成しているのですか?
このプロジェクトは自己対戦による学習に関するものですので、エージェントに対してどのようにプレイするかの事前情報は与えることができません。最初のサイクルでは、エージェントは良い手か悪い手かについて何の知識も持っていないため、試合はランダムプレイによって生成されなければなりません。
図2は、ランダムプレイヤー間の試合の例を示しています:
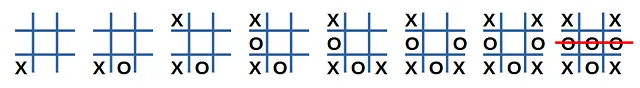
この試合を観察することで何を学ぶことができるでしょうか? ‘X’プレイヤーの観点からは、これは敗北で終わったため、プレイが貧弱な例と考えることができます。どの手が敗北に寄与したのかはわかりませんので、’X’プレイヤーによって行われたすべての決定が悪かったと仮定します。いくつかの決定が良かった場合、予測された状態値を修正するために統計学に頼ります(他のシミュレーションでも同様の状態になる可能性があります)。
プレイヤー ‘X’の最後のアクションには値-1が与えられます。他のアクションは、最初の手に向かって幾何学的に減衰する割引された負の値を受け取ります(γ(ガンマ)∈[0、1])。
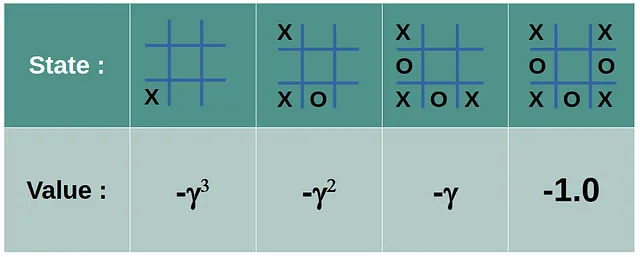
勝利した試合から得られた状態は、同様の正の割引値を受けます。引き分けから引き出された状態は値0を受けます。エージェントは、最初のプレイヤーと2番目のプレイヤーの両方の視点を持ちます。
ゲーム状態のテンソルとしての表現
ゲームの状態のテンソル表現が必要です。[2x3x3]のテンソルを使用します。最初の次元はチャネルを表し(’X’の場合は0、’O’の場合は1)、他の2つの次元は行と列です。 (行、列)のマスの占有は、(チャネル、行、列)のエントリに1としてエンコードされます。
![Figure 4: The game state representation by a [2x3x3] tensor. Image by the author.](https://miro.medium.com/v2/resize:fit:640/format:webp/1*MJ0TM_9SmsJBGi01mufQxA.png)
試合の生成によって得られた(状態テンソル、ターゲット値)のペアは、各ラウンドでニューラルネットワークがトレーニングするデータセットを構成します。データセットはサイクルの開始時に構築され、以前のラウンドで学習が行われたことを利用しています。最初のラウンドは純粋なランダムプレイを生成しますが、それ以降のラウンドでは徐々に現実的な試合が生成されます。
ランダム性をプレイに注入する
マッチ生成の最初のラウンドでは、ランダムなプレーヤー同士が対戦します。その後のラウンドでは、エージェントは自身に対して対戦します(つまり「セルフプレイ」です)。エージェントは、マッチの結果を予測するために訓練された回帰ニューラルネットワークを搭載しており、最も期待値が高い合法的なアクションを選択することができます。多様性を促進するために、エージェントはε-グリーディアルゴリズムに基づいてアクションを選択します:確率(1-ε)で最良のアクションが選択され、それ以外の場合はランダムなアクションが選択されます。
トレーニング
図5は、最大17のトレーニングラウンドに対して5つのエポックごとのバリデーション損失の進化を示しています:
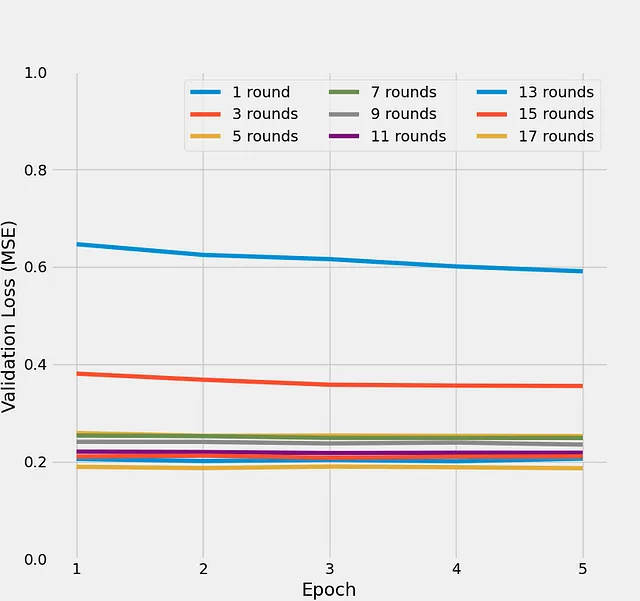
最初の数回のトレーニングラウンドでは、バリデーション損失が急速に減少し、その後は平均二乗誤差損失0.2のプラトーが見られます。この傾向は、エージェントの回帰ニューラルネットワークが、与えられたゲーム状態から自己対戦でのマッチ結果を予測する能力が向上していることを示しています。両プレーヤーのアクションが非決定論的であるため、マッチ結果の予測性には限界があります。それが何回かのラウンド後にバリデーション損失の改善が停止する理由です。
ラウンドごとの改善
SumTo100のゲームでは、状態を1次元グリッド上で表現することができました。しかし、三目並べでは状態の価値の進化を直接表示することはできません。改善の測定方法として、エージェントを以前のバージョンと対戦させ、勝利と敗北の違いを観察することができます。
比較ごとに1000回のマッチを実行し、最初のアクションにはε = 0.5、それ以降のマッチにはε = 0.1を使用した場合、以下の結果が得られます:
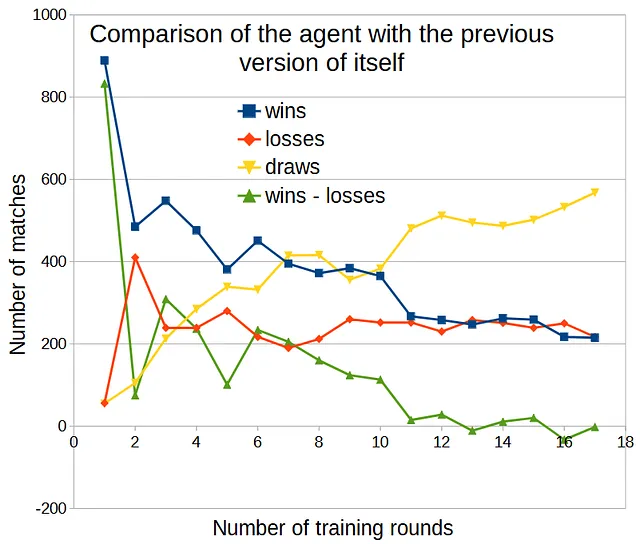
勝利回数が敗北回数を上回り(改善を示す)、10回のトレーニングラウンドまで続きました。その後、エージェントはラウンドごとの改善を見せませんでした。
テスト
さて、エージェントがどのように三目並べをプレイするか見てみましょう!
回帰ニューラルネットワークを持つことの利点の一つは、エージェントが各合法な手の評価を表示できることです。オプションの判断方法を示しながら、エージェントと対戦してゲームをプレイしましょう。
手動プレイ
エージェントが始めて、’X’をプレイします:
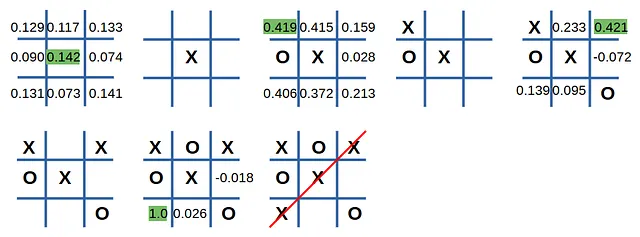
これが冷酷な三目並べマシンによって粉砕される方法です!
(1, 0)のマスに’O’を入れると、期待リターンが0.142から0.419に増加し、私の運命は決まりました。
次に、エージェントが2番目にプレイする場合を見てみましょう:
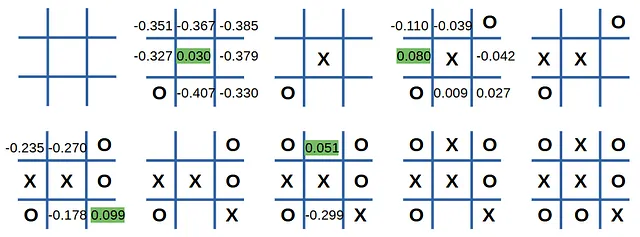
それは罠にはまらず、試合は引き分けでした。
ランダムなプレイヤーとの対戦
ランダムなプレイヤーとの大量の試合をシミュレーションすると、次のような結果が得られます:
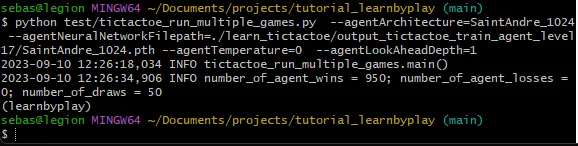
1000試合中(エージェントは半分の試合で先攻でした)、エージェントは950試合に勝ち、誰にも負けず、50試合は引き分けでした。これは私たちのエージェントが最適にプレイしていることの証拠ではありませんが、確かに優れたプレイレベルに達しています。
結論
ゲームが簡単に解読でき、状態空間が小さいという「自己対戦を通じてシンプルなゲームをマスターする」という記事の続編として、同じ技術を使って三目並べをマスターしました。これはまだおもちゃの問題ですが、三目並べの状態空間は十分に大きいため、エージェントの回帰ニューラルネットワークは状態テンソル内のパターンを見つける必要があります。これらのパターンによって、未知の状態テンソルに対して一般化が可能となります。
このリポジトリでコードを入手できます。ぜひ試してみて、ご意見をお聞かせください!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






