複数の画像やテキストの解釈 データサイエンス - Section 205
データ サイエンスの芸術と科学でデータの力を解き放ちます

13分でハミルトンを使用したメンテナブルでモジュラーなLLMアプリケーションスタックの構築
この投稿では、オープンソースのフレームワークであるHamiltonが、大規模な言語モデル(LLM)アプリケーションスタックのため...
「LLMsの実践的な導入」
「これは、実践で Large Language Models (LLMs) を使用するシリーズの最初の記事ですここでは、LLMs の紹介とそれらとの作業...
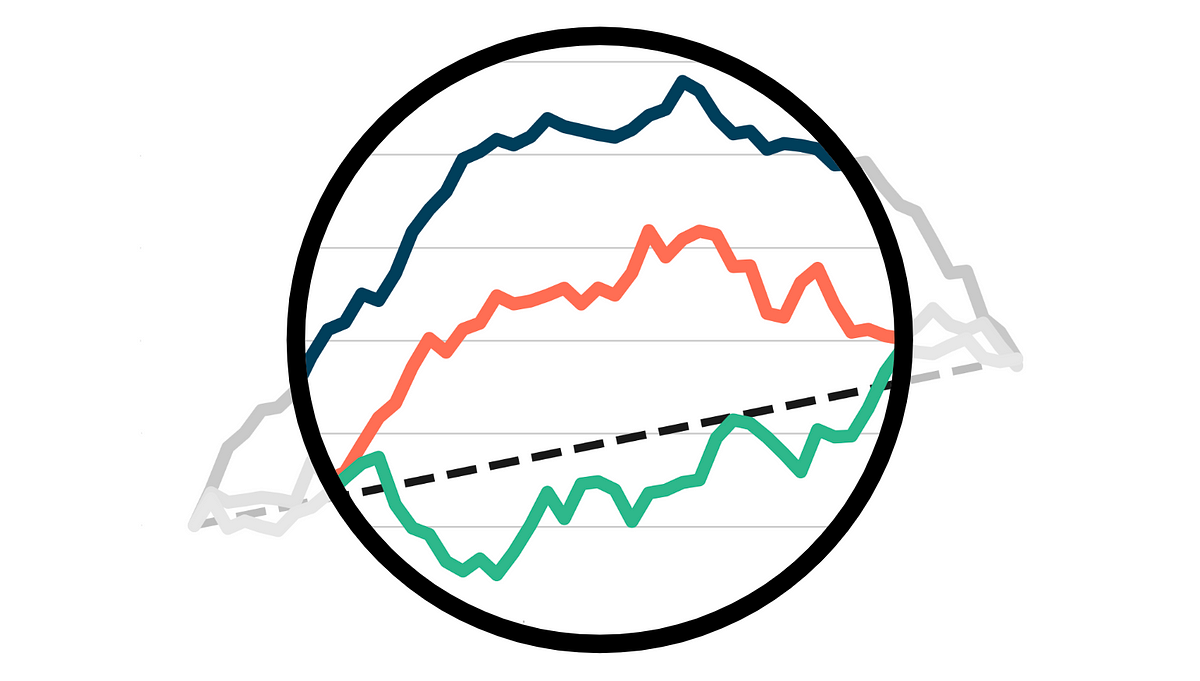
アップリフトモデルの評価
業界での因果推論の最も広く利用されているアプリケーションの1つは、アップリフトモデリング、または条件付き平均治療効果の...

「知識グラフの力を利用する:構造化データでLLMを豊かにする」
近年、大規模な言語モデル(LLM)が広まってきていますおそらく最も有名なLLMはChatGPTで、それはOpenAIによって2022年11月に...

「Pythonデータ構造について知っておくべき3つの重要な概念」
これらはPythonのデータ構造について知っておくべきいくつかのことですこれらの違いには確かに理由があり、それぞれが特定の...

「Jaro-Winklerアルゴリズムを使用して小規模言語モデル(SLM)を構築し、スペルエラーを改善・強化する」
「Jaro-Winklerアルゴリズムを使って、小さな固定定義データセットでSmall Language Model(SLM)を構築し、システムのスペル...

データベースの最適化:SQLにおけるインデックスの探索
SQLにおけるインデックスについて学び、SELECTクエリとWHERE句の検索速度を向上させる方法について学びましょう

LAION AIは、Video2Datasetを紹介しますこれは、効率的かつスケールでビデオとオーディオのデータセットをキュレーションするために設計されたオープンソースツールです
CLIP、Stable Diffusion、Flamingoなどの大規模な基盤モデルは、過去数年間にわたり、マルチモーダルな深層学習を劇的に向上...
学習トランスフォーマーコード第2部 – GPTを間近で観察
私のプロジェクトの第2部へようこそここでは、TinyStoriesデータセットとnanoGPTを使用して、トランスフォーマーとGPTベース...
成功に導くデータチームの意思決定
現実は複雑です:人々や組織は予期しない方法で行動し、外部の出来事は私たちの最もうまくいくワークフローに次々と障害を投...

- You may be interested
- T5:テキスト対テキスト変換器(パート1)
- 「ジェネレーティブAI(2024)の10の重要...
- Googleの安全なAIフレームワークを紹介します
- 一般的なエージェント
- 「企業が職場のAIを求める中、テック企業...
- 効率的にPythonコードを書く方法:初心者...
- 「Juliaプログラミング言語の探求 ユニッ...
- 「AIチャットボットが言語理解に取り組む」
- イノベーションと持続可能性のバランス:...
- コンピュータ芸術の先駆者、ヴェラ・モル...
- 成功に導くデータチームの意思決定
- 「勉強ルーティンにおけるワードウォール...
- 学校でのChatGPTの影響となぜ禁止されつつ...
- スタンフォード大学とGoogleからのこのAI...
- 「Non-engineers guide LLaMA 2チャットボ...
Find your business way
Globalization of Business, We can all achieve our own Success.