複数の画像やテキストの解釈 データサイエンス - Section 166
データ サイエンスの芸術と科学でデータの力を解き放ちます

「大規模な言語モデルとベクトルデータベースを使用してビデオ推薦システムを構築した方法」
私たちの世代は、音声からビデオコンテンツまで、あらゆる種類のストリーミングサービスを利用できるという点で幸運です私た...

「Amazon Redshift」からのデータを使用して、Amazon SageMaker Feature Storeで大規模なML機能を構築します
Amazon Redshiftは、一日にエクサバイトのデータを分析するために数万人の顧客に利用されている、最も人気のあるクラウドデー...
「正しい方法で新しいデータサイエンスのスキルを学ぶ」
「私たちは学習曲線を整然とした滑らかな上昇線と考える傾向がありますしかし、学習の旅をよく見ると、途中には数多くの下降...

「機械学習モデルが医学的診断と治療において不公平を増幅する方法」
「MITの研究者たちは、代表的でないグループの間の医療格差の原因を調査しています」
「初心者のためのPandasを使ったデータフォーマットのナビゲーション」
はじめに Pandasとは、名前だけではありません – それは「パネルデータ」の略です。では、それが具体的に何を意味する...

「GPT4のデータなしでコードLLMのインストラクションチューニングを行う方法は? OctoPackに会いましょう:インストラクションチューニングコード大規模言語モデルのためのAIモデルのセット」
大規模言語モデル(LLM)の使いやすさと全体的なパフォーマンスは、指示を介して提供されるさまざまな言語タスク(指示チュー...
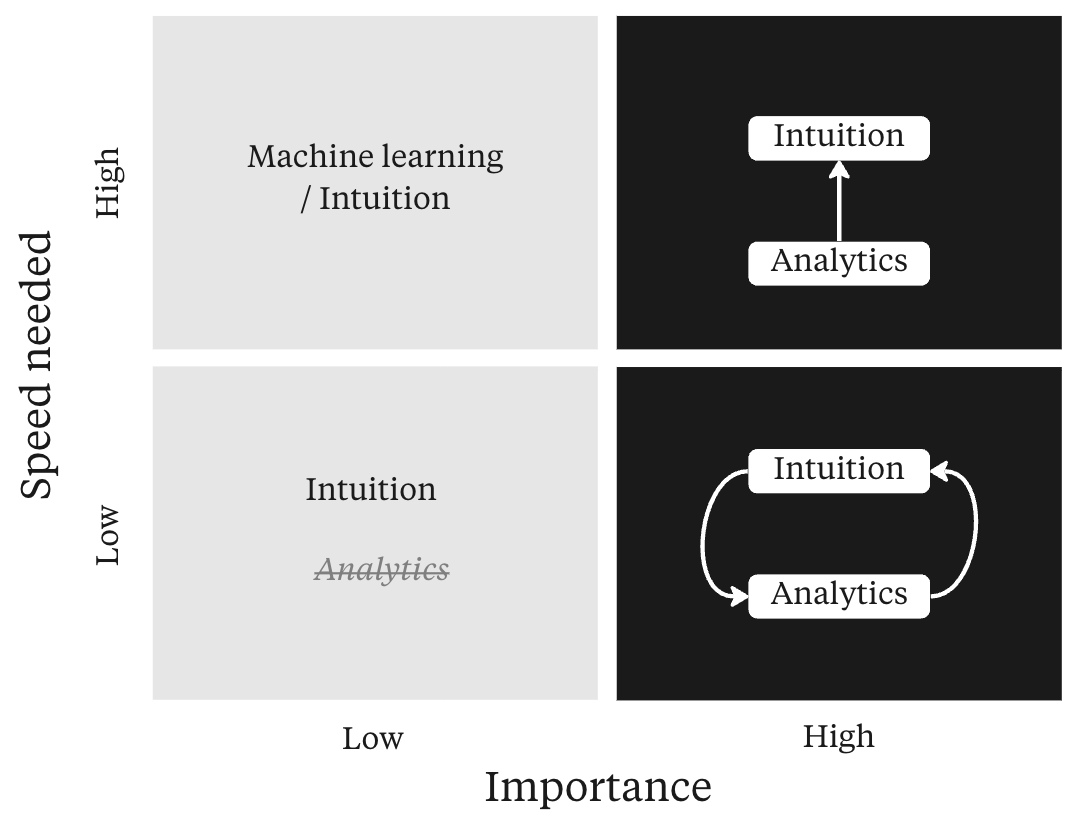
「データ主導的なアプローチを取るべきか?時にはそうである」
「Covid-19が発生したとき、私はAirbnbでデータサイエンティストとして働いていましたそして、おそらく予想しているように、C...

「Azure Data Factory(ADF)とは何ですか?特徴とアプリケーション」
イントロダクション データ駆動型の意思決定の時代において、データを効率的に統合することは重要です。Azure Data Factory(...

「pandasのCopy-on-Writeモードの深い探求-パートII」
最初の投稿では、Copy-on-Writeメカニズムの動作方法について説明しましたコピーがワークフローに導入されるいくつかの領域を...

「データサイエンス(2023年)で学ぶべきこと」
初心者や既存の機械学習の実践者やデータサイエンティストさえも、広大な情報の海に迷い込んでしまいます情報の過多により、...

- You may be interested
- NVIDIA RTXビデオスーパーレゾリューショ...
- PDFとのチャット | PythonとOpenAIによる...
- 「OpenLLMの紹介:LLMのためのオープンソ...
- LangChainによるAIの変革:テキストデータ...
- 確率的なML(機械学習)とは、Pythonを使...
- ロボットは人間と同じく植物を育てること...
- 「Mixtral 8x7Bについて知っていること ミ...
- 『ScaleCrafterを知る:事前学習済みの拡...
- マシンラーニングのロードマップ:コミュ...
- 「クルーズ、サンフランシスコでの自動運...
- 新しいAmazon SageMakerコンテナでLLMの推...
- 複数の時間軸での予測 天気データの例
- 「リオール・ハキム、Hour Oneの共同創設...
- インドでのGoogle検索は今やAIによって動...
- 「屋内モデリングのための3Dポイントクラ...
Find your business way
Globalization of Business, We can all achieve our own Success.