複数の画像やテキストの解釈 Vision
「LLaVAと一緒にあなたのビジョンチャットアシスタントを作りましょう」
大規模な言語モデルは、革命的な技術であることが証明されていますその能力を活用した数多くのアプリケーションがすでに開発...
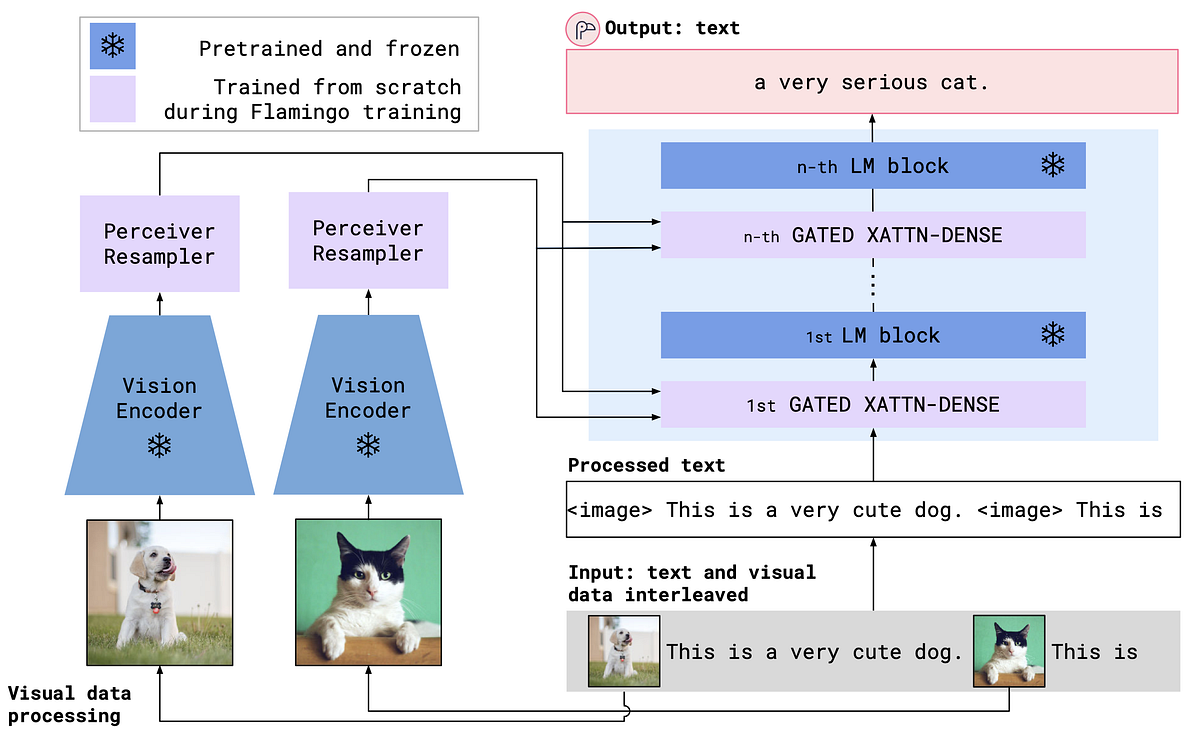
マルチモーダル言語モデルの解説:ビジュアル指示の調整
「LLMは、多くの自然言語タスクでゼロショット学習とフューショット学習の両方で有望な結果を示していますしかし、LLMは視覚...

- You may be interested
- 深層学習を用いた強力なレコメンデーショ...
- もし芸術が私たちの人間性を表現する方法...
- 「総合的な指標を通じて深層生成モデルの...
- 「Google Bard vs. ChatGPT ビジネスにお...
- 「セルフサービスデータ分析はニーズの階...
- 「ルービックとマルコフ」
- 最終的なDXAネーション
- アップルとCMUの研究者が新たなUI学習者を...
- DeepMindのロボキャットに会ってください...
- A/Bテストを超えたアプローチで戦略を最適...
- 黄金時代:『エイジ オブ エンパイア III...
- 「挑戦受けた:GeForce NOWが究極の挑戦と...
- 我々はまもなく独自のパーソナルAIムービ...
- AIによるなりすましからの戦い
- 「ChatGPTの現実世界での応用」
Find your business way
Globalization of Business, We can all achieve our own Success.