複数の画像やテキストの解釈 Representation Learning

In this translation, Notes is translated to メモ (memo), CLIP remains as CLIP, Connecting is translated to 連結 (renketsu), Text is translated to テキスト (tekisuto), and Images is translated to 画像 (gazo).
上記論文の著者たちは、最小限またはほとんど監督を必要とせずに、さまざまなタスクに使用できる画像の良い表現(特徴)を生...

BYOL(Bootstrap Your Own Latent)— コントラスティブな自己教示学習の代替手段
『今日の論文分析では、BYOL(Bootstrap Your Own Latent)の背後にある論文に詳しく触れますこれは、対比的な自己教師あり学...
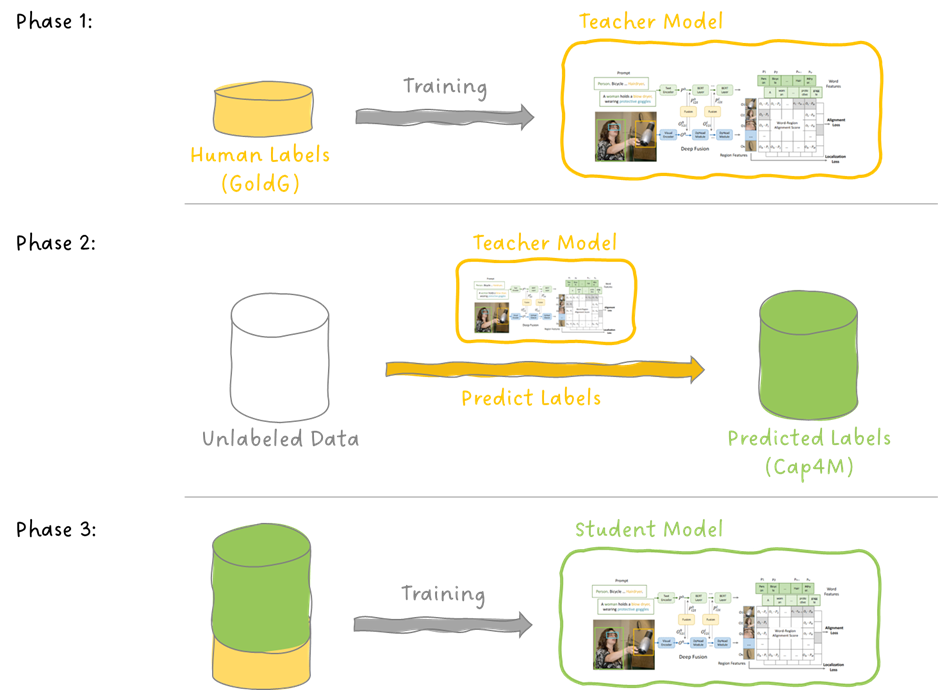
GLIP オブジェクト検出への言語-画像事前学習の導入
今日は、言語-画像の事前学習であるCLIPの素晴らしい成功を基に、物体検出のタスクに拡張した論文であるGLIPについて掘り下げ...

- You may be interested
- 「リコメンデーションシステムにおける2つ...
- 医療における臨床家と言語モデルのギャッ...
- 韓国大学の研究者たちは、HierSpeech++を...
- 「枝は何も必要ありません:私たちの主観...
- 「生成AIは私たちをAIの転換点へと押し進...
- 機能データの異常検出のための密度カーネ...
- 「ワンダー3Dに会おう:単一視点画像から...
- 「検索補完生成を用いてより能力の高いLLM...
- 「モデルガバナンスを向上させるために、A...
- PySparkでのランダムフォレスト回帰の実装...
- FlashAttentionアルゴリズムの深い探求-パ...
- 「Amazon EC2 Inf1&Inf2インスタンス上の...
- エッセンシャルコンプレクシティは、開発...
- 会社独自のChatGPTを開発するには、技術の...
- 「Lab Sessions 実験的なAIの新しいコラボ...
Find your business way
Globalization of Business, We can all achieve our own Success.