複数の画像やテキストの解釈 Reinforcement Learning - Section 2
「時間差学習と探索の重要性:図解ガイド」
最近、強化学習(RL)アルゴリズムは、タンパク質の折りたたみやドローンレースの超人レベルの到達、さらには統合などの研究...

大規模言語モデルの応用の最先端テクニック
イントロダクション 大規模言語モデル(LLM)は、人工知能の絶えず進化する風景において、注目すべきイノベーションの柱です...

データサイエンスによる在庫最適化:Pythonによるハンズオンチュートリアル
在庫最適化は、トリッキーなパズルを解くようなものです広範な問題として、さまざまなドメインで発生しますそれは、店舗のた...
自己対戦を通じてエージェントをトレーニングして、三目並べをマスターする
あぁ!小学校!これは私たちが識字、算数、そして最適な○×ゲームのプレイなど、貴重なスキルを学んだ時期です友達と○×ゲーム...

高性能意思決定のためのRLHF:戦略と最適化
はじめに 人間の要因/フィードバックからの強化学習(RLHF)は、RLの原則と人間のフィードバックを組み合わせた新興の分野で...
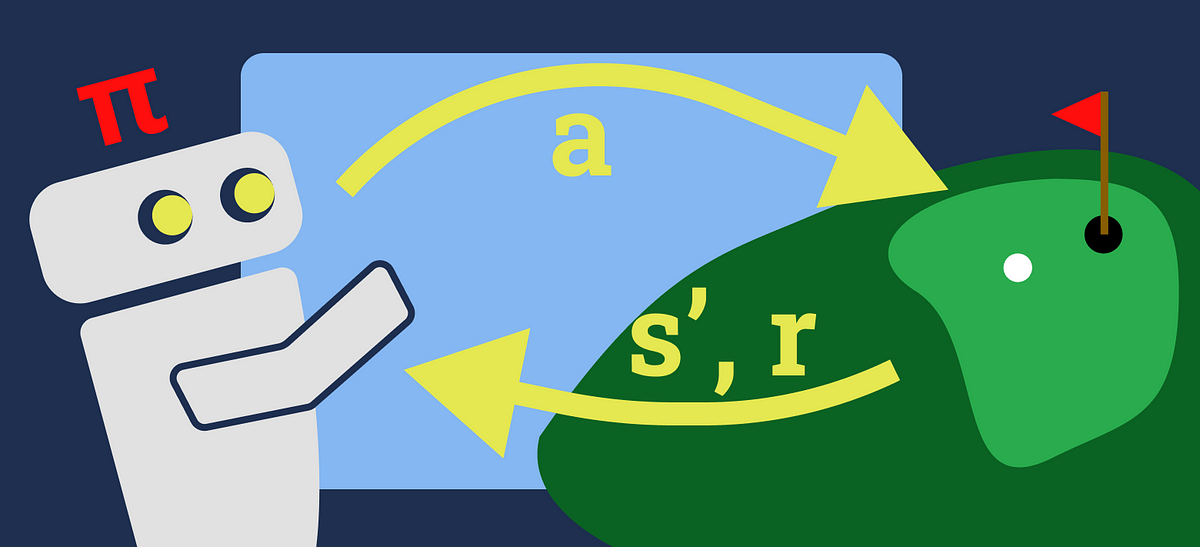
強化学習 価値反復の簡単な入門
価値反復(VI)は、通常、強化学習(RL)学習経路で最初に紹介されるアルゴリズムの一つですアルゴリズムの基本的な内容は、...

「Google Researchが探求:AIのフィードバックは、大規模な言語モデルの効果的な強化学習において人間の入力を置き換えることができるのか?」
人間のフィードバックは、機械学習モデルを改善し最適化するために不可欠です。近年、人間のフィードバックからの強化学習(R...

自己対戦を通じて単純なゲームをマスターするエージェントのトレーニング
「完全情報ゲームで優れるために必要なすべてがゲームのルールにすべて見えるというのはすごいことですね残念ながら、私のよ...
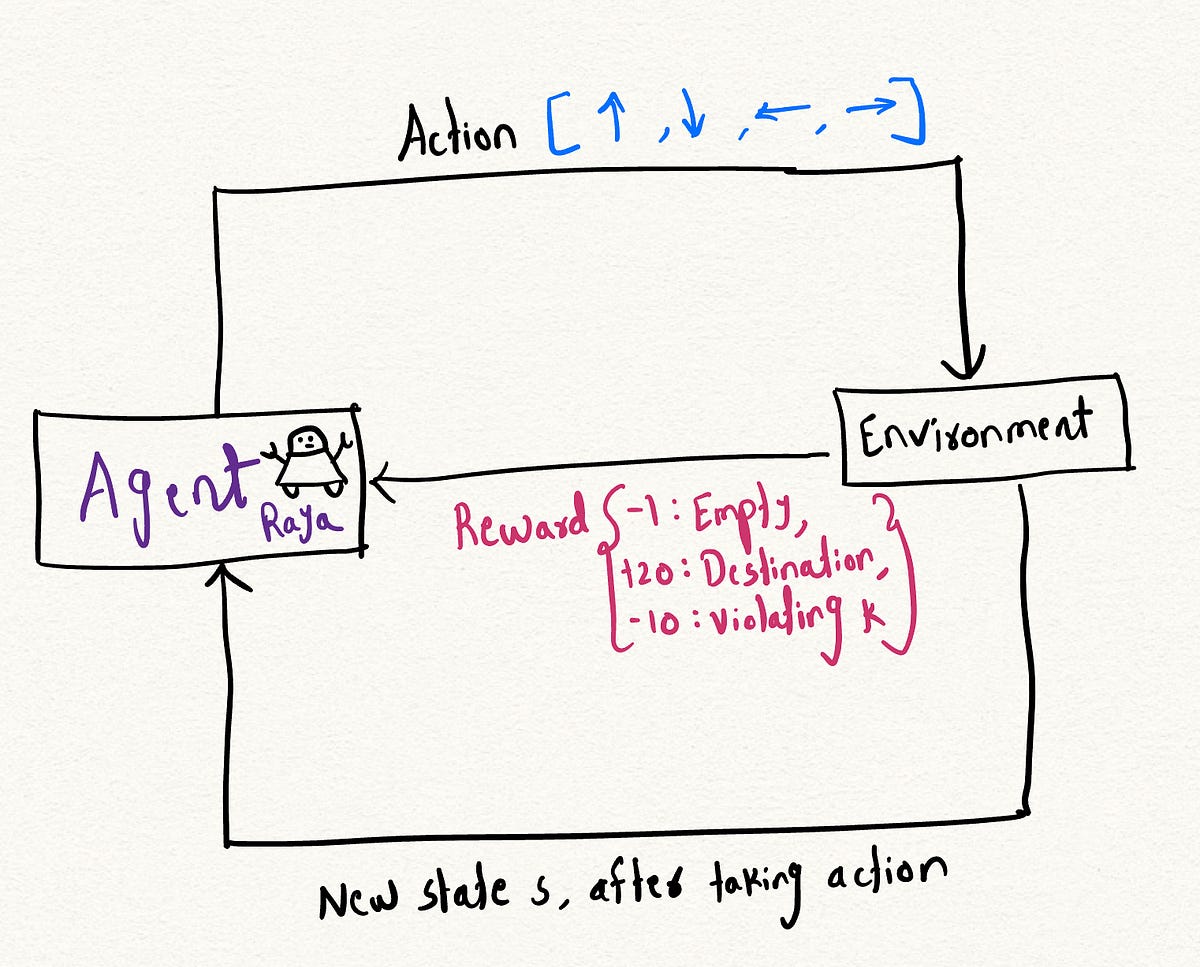
「強化学習を使用してLeetcodeの問題を解決する」
最近、leetcodeで「障害物を排除したグリッド内の最短経路」に関する質問に出会いました障害物を排除したグリッド内の最短経...

DeepMindの研究者が、成長するバッチ強化学習(RL)に触発されて、人間の好みに合わせたLLMを整列させるためのシンプルなアルゴリズムであるReinforced Self-Training(ReST)を提案しました
大規模言語モデル(LLM)は、優れた文章を生成し、さまざまな言語的な問題を解決するのに優れています。これらのモデルは、膨...

- You may be interested
- アラウカナXAI:医療における意思決定木を...
- アカデミックパートナーがスタートアップ...
- マルチマテリアルプリンターにより、柔軟...
- 「私たちの10の最大のAIの瞬間」
- 「AIが歴史学者たちに過去をより良く理解...
- カスタムレンズを使用して、優れたアーキ...
- 「3D MRIとCTスキャンに使用するディープ...
- 「言語モデルは放射線科を革新することが...
- 効率の向上:私がテックMLEとして毎日使用...
- 「エローの有名なレーティングシステムに...
- Google DeepMindは、ChatGPTを超えるアル...
- 「B2B企業におけるAIを活用した顧客セグメ...
- 巧妙な科学:データダグリングが暴露される
- Gorillaに会ってください:UCバークレーと...
- 「ウォルマート、オフィス従業員を生成AI...
Find your business way
Globalization of Business, We can all achieve our own Success.