複数の画像やテキストの解釈 Quantization

エクスラマV2:LLMを実行するための最速のライブラリ
ExLlamaV2は、GPTQからさらに高いパフォーマンスを引き出すために設計されたライブラリです新しいカーネルのおかげで、(超高...

QLoRA:16GBのGPUで大規模な言語モデルの訓練を行う
「我々は、モデルのための量子化などの体重減少技術と、パラメータ効率の良いファインチューニング技術であるLoRAを組み合わ...
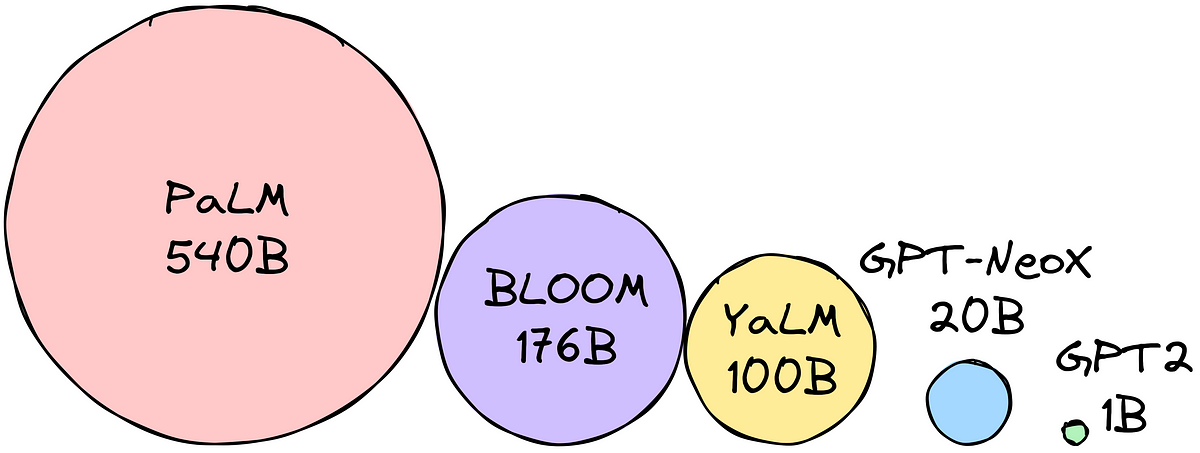
小さなメモリに大きな言語モデルを適合させる方法:量子化
大型言語モデルは、テキスト生成、翻訳、質問応答などのタスクに使用することができますしかし、LLM(大型言語モデル)は非常...
「テンソル量子化:語られなかった物語」
この記事の残りの部分では、具体的な例を用いて以下の質問に答えていきますスケール:浮動小数点範囲を量子化する際、通常、...

GGMLとllama.cppを使用してLlamaモデルを量子化する
この記事では、私たちはGGMLとllama.cppを使用してファインチューニングされたLlama 2モデルを量子化しますその後、GGMLモデ...
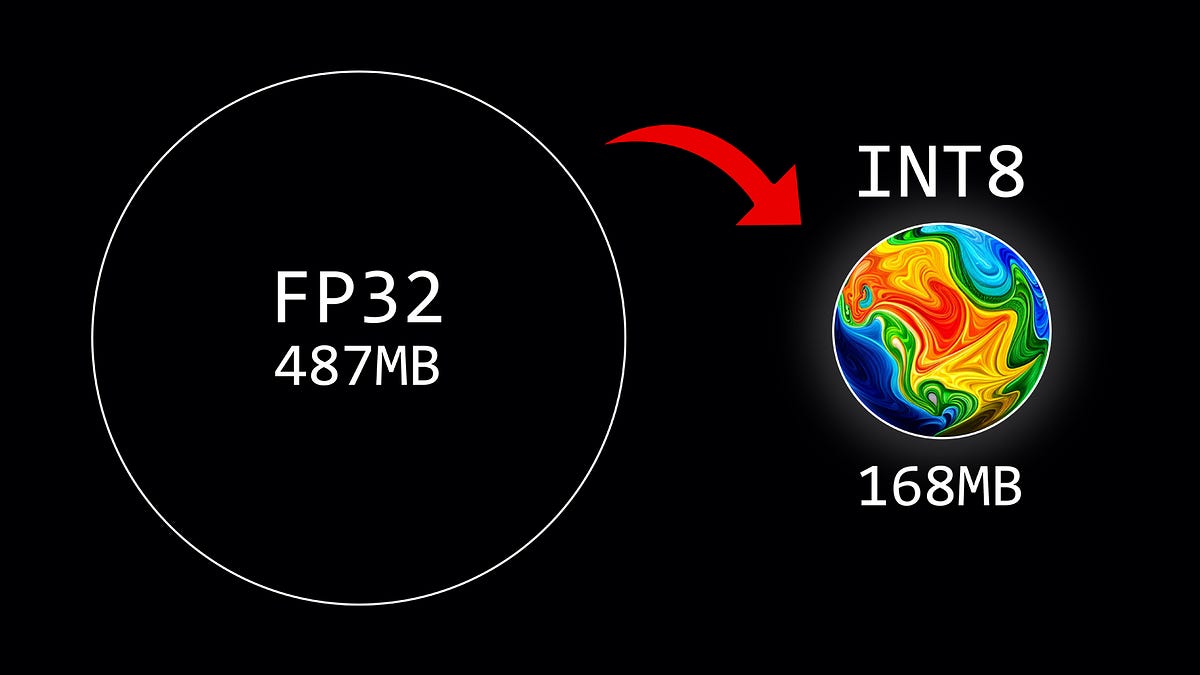
重み量子化の概要
この記事では、8ビットの量子化方式を使用して、大規模言語モデルのパラメータを量子化する方法について説明しています

- You may be interested
- アーサーがベンチを発表:仕事に最適な言...
- 『日常のデザイン(AI)』
- SalesforceはXGen-7Bを導入:1.5Tトークン...
- 「Javaプログラミングの未来:2023年に注...
- 「WavJourney:オーディオストーリーライ...
- 暗号学のゴシップ パート1と2
- 「LLM応募の準備を始めるための6つの便利...
- 「このAI研究は、深層学習と進化アルゴリ...
- 「データパイプラインについての考え方が...
- ペンシルベニア大学の研究者たちは、腎臓...
- 「SQLにおけるSUBSTRING関数とは何ですか...
- 強化学習:コンピューターに最適な決定を...
- 初心者のための2023年の機械学習論文の読み方
- 『ChatGPTを活用したソフトウェアテストと...
- 「大規模な言語モデルがコンパイラ最適化...
Find your business way
Globalization of Business, We can all achieve our own Success.