複数の画像やテキストの解釈 On-device Learning
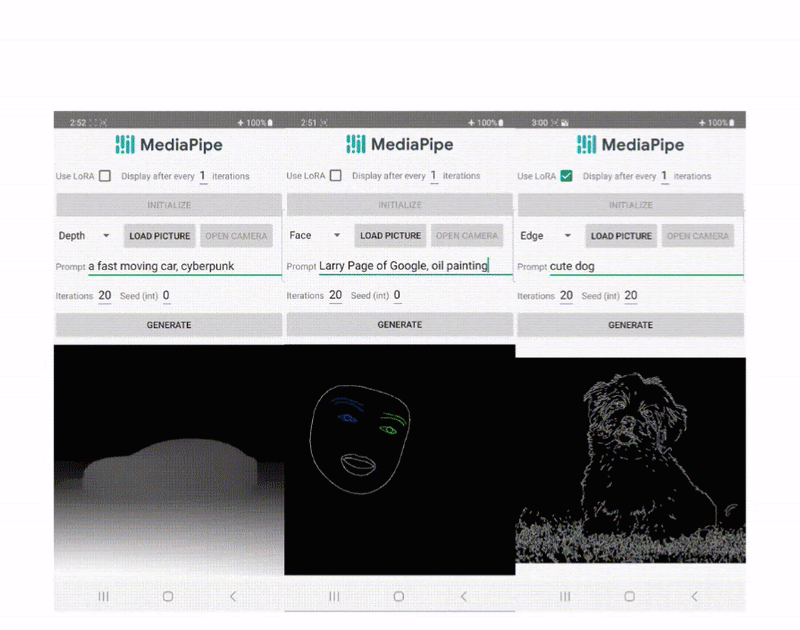
デバイス上での条件付きテキストから画像生成のための拡散プラグイン
Yang ZhaoとTingbo Houによる投稿、ソフトウェアエンジニア、Core ML 近年、拡散モデルはテキストから画像を生成する際に非常...

- You may be interested
- シミュレーション105:数値積分によるダブ...
- 「トリントの創設者兼CEO、ジェフ・コフマ...
- テックとマインドのバランス:メンタルヘ...
- 将来のPythonバージョン(3.12など)に一...
- エンジニアにとって役立つ6つのリソース
- 「主要なウェブサイトは、AIクローラーが...
- 『あなた自身の個人用ChatGPT』
- 「Google DeepMindの研究者が『プロンプト...
- 大規模言語モデルに関するより多くの無料...
- 「データセンターは冷房を少なくしても同...
- DeepMindの研究とAlphabet製品の連携
- 日付時刻データを扱うための便利なPandas...
- 「プログラマーを支援するためにコードを...
- ヒットパウ写真エンハンサーレビュー:最...
- 技術と金融の交差点における成功
Find your business way
Globalization of Business, We can all achieve our own Success.