複数の画像やテキストの解釈 Object Detection

注釈の習得:LabelImgとのシームレスなDetectron統合
イントロダクション コンピュータビジョンの大局において、画像のラベリングや写真の注釈付けは困難でありました。私たちの調...

SSDを使用したリアルタイム物体検出:シングルショットマルチボックス検出器
イントロダクション リアルタイムオブジェクト検出では、従来のパラダイムは通常、バウンディングボックスの提案、ピクセルま...

「OWLv2のご紹介:ゼロショット物体検出におけるGoogleのブレークスルー」
はじめに 2023年も終わりが近づいていますが、コンピュータビジョンコミュニティにとっての興奮するニュースは、Googleが最近...
特定のドメインに特化した物体検出モデルの最適化方法
物体検出は、学術界から産業分野まで、広範な領域で広く採用されていますその理由は、低い計算コストで素晴らしい結果を提供...

「人物再識別入門」
「人物再識別」は、異なる非重複カメラビューに現れる個人を識別するプロセスですこのプロセスは、顔認識に頼らずに、服装を...
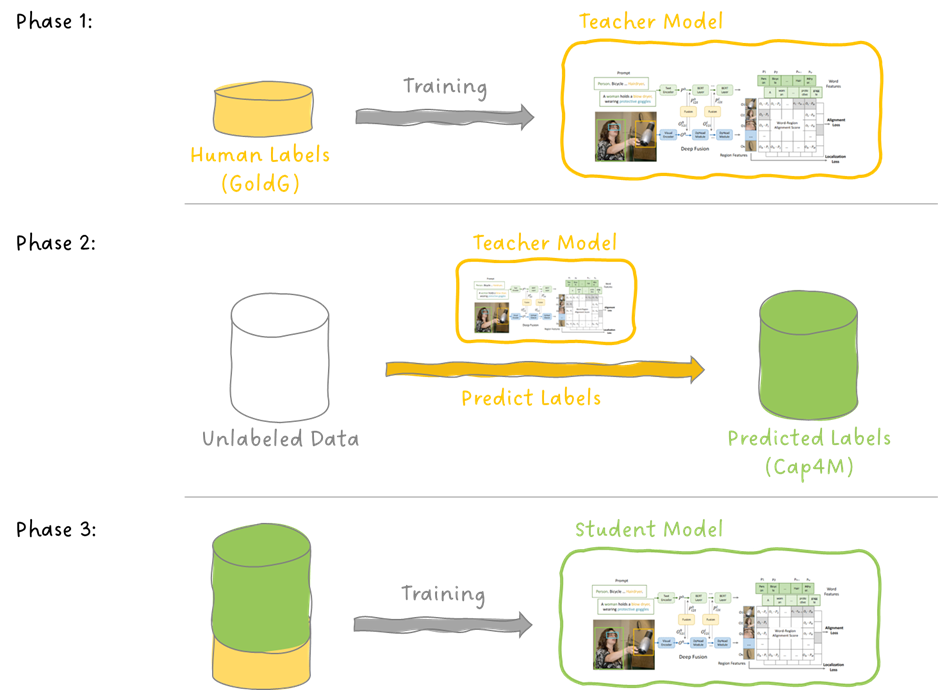
GLIP オブジェクト検出への言語-画像事前学習の導入
今日は、言語-画像の事前学習であるCLIPの素晴らしい成功を基に、物体検出のタスクに拡張した論文であるGLIPについて掘り下げ...
画像中のテーブルの行と列をトランスフォーマーを使用して検出する
はじめに 非構造化データを扱ったことがあり、ドキュメント内のテーブルの存在を検出する方法を考えたことはありますか?ドキ...

「CutLER(Cut-and-LEaRn):人間の注釈なしで物体検出とインスタンスセグメンテーションモデルをトレーニングするためのシンプルなAIアプローチによる出会い」
オブジェクト検出と画像セグメンテーションは、コンピュータビジョンと人工知能の重要なタスクです。これらは、自動車、医療...

- You may be interested
- 「GPT-4 コードインタープリター:瞬時にP...
- コードの解読:機械学習が故障診断と原因...
- VoAGIニュース、7月12日:ChatGPTに関する...
- エンタープライズAIとは何ですか?
- 「ChatGPTのコードインタプリタをデータサ...
- 「RAGを忘れて、未来はRAG-Fusionです」
- 「なぜ自宅でPythonを使って10億桁の円周...
- 大きな言語モデルはどれくらい透明性があ...
- Amazon SageMakerを使用した生成型AIモデ...
- トップ5のデータ分析の認定資格
- 商務省は、「米国人工知能安全研究所」を...
- 「iOSのための10の最高のデータ復旧ツール...
- 「Pythonでのプロトコル」
- DevOpsGPTとは、LLMとDevOpsツールを組み...
- デブオプスにおけるAI ソフトウェアの展開...
Find your business way
Globalization of Business, We can all achieve our own Success.