複数の画像やテキストの解釈 NLP - Section 14

「データサイエンティストが読むべきトップ7のNLP(自然言語処理)の本」
はじめに 自然言語処理(NLP)の最近の進歩は、データサイエンティストが最新の情報を把握するために不可欠です。NLPの書籍は...

「Hugging Faceを使用してLLMsを使ったテキスト要約機を構築する」
はじめに 最近、LLMs(Large Language Models)を使用したテキスト要約は多くの関心を集めています。これらのモデルは、GPT-3...

「Gensimを使ったWord2Vecのステップバイステップガイド」
はじめに 数か月前、Office Peopleで働き始めた当初、私は言語モデル、特にWord2Vecに興味を持ちました。ネイティブのPython...

テキストデータのチャンキング方法-比較分析
自然言語処理(NLP)における「テキストチャンキング」プロセスは、非構造化テキストデータを意味のある単位に変換することを...

現代の自然言語処理(NLP):詳細な概要パート1:トランスフォーマー
最近の半年間で、私たちはBERTやGPTなどのアイデアの導入により、自然言語処理の領域で大きな成果を見てきましたこの記事では...

「テキスト要約の革新:GPT-2とXLNetトランスフォーマーの探索」
イントロダクション すべてを読んで理解するためには時間が足りません。そこでテキスト要約が登場します。テキスト要約は、テ...
「Transformerモデルの実践的な導入 BERT」
ハンズオンチュートリアルでBERTを探索してください:トランスフォーマーを理解し、プレトレーニングとファインチューニング...
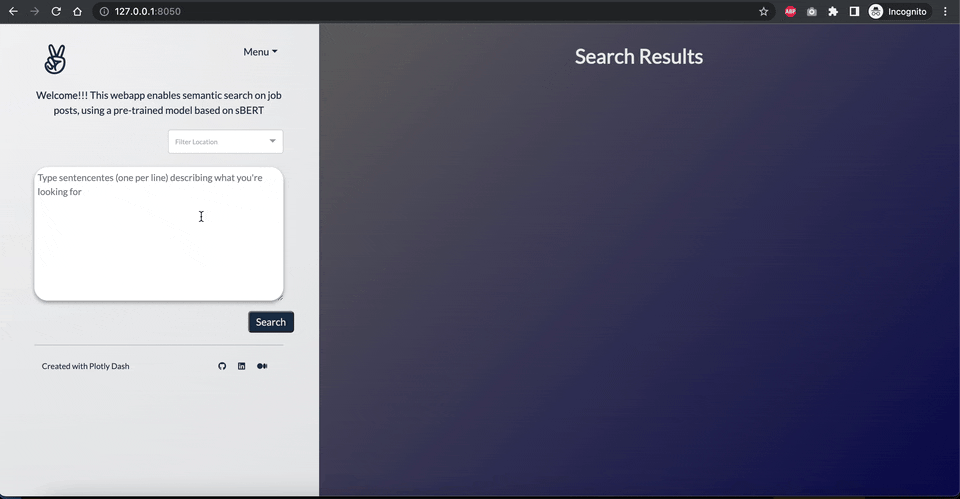
NLP で仕事検索を強化しましょう
最も一般的な求人プラットフォームでは、検索機能はいくつかの入力単語といくつかのフィルタ(場所など)に基づいて求人を絞...
「ベクトルデータベースの力を活用する:個別の情報で言語モデルに影響を与える」
この記事では、ベクトルデータベースと大規模言語モデルという2つの新しい技術がどのように連携して動作するかについて学びま...

「検索拡張生成のための情報検索」
「情報検索のパフォーマンスを劇的に向上させるための、3つ(と半分)のシンプルで実戦済みのヒント」

- You may be interested
- 「OpenAIのChatGPTコードインタプリタの探...
- 「ポーラーズ.ローリングは、列の数とどの...
- 「Pythonにおける断続的な時系列の予測」
- 『クラウド上で大規模な言語モデルを使用...
- 「MFAを超えて:オクタがエンタープライズ...
- 「カオスから秩序へ:データクラスタリン...
- 「あなたがその仕事を手に入れることを保...
- 「初めてのデータサイエンスプロジェクト...
- Google AIは、オーディオ、ビデオ、テキス...
- NVIDIAの最高科学者、ビル・ダリー氏がHot...
- 「Java ZGCアルゴリズムのチューニング」
- 「CMUの研究者たちがRoboToolを公開:自然...
- 「新しい攻撃が主要なAIチャットボットに...
- 「DERAに会ってください:対話可能な解決...
- プレイヤーの離脱を予測する方法、ChatGPT...
Find your business way
Globalization of Business, We can all achieve our own Success.