複数の画像やテキストの解釈 Multimodal Learning
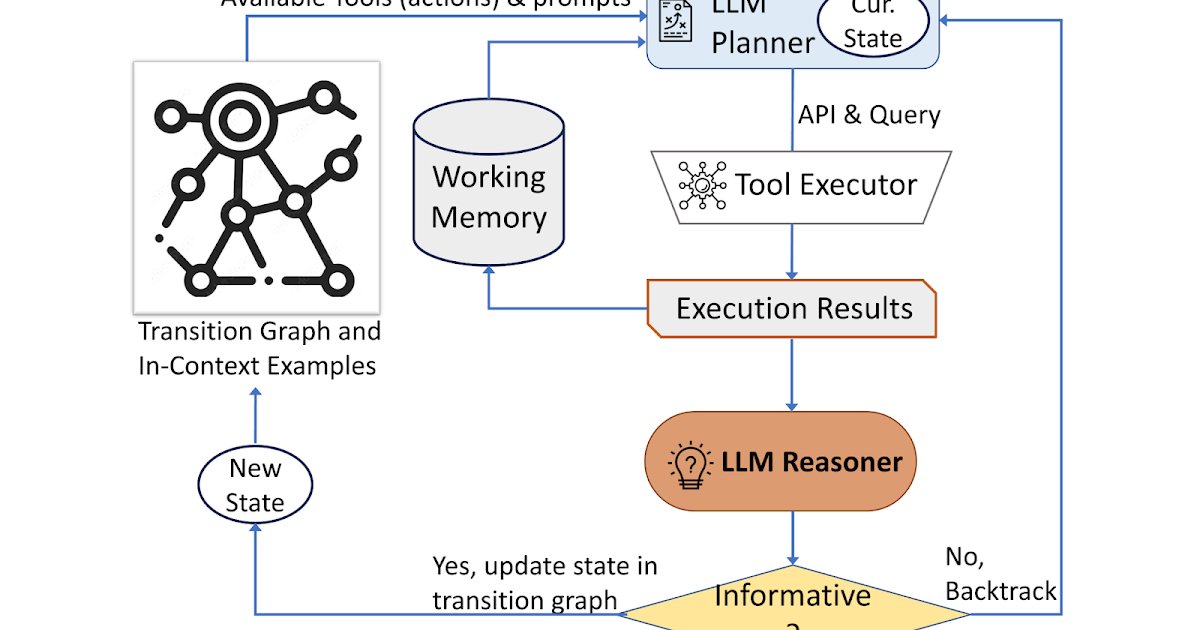
大規模な言語モデルを使用した自律型の視覚情報検索
Posted by Ziniu Hu, Student Researcher, and Alireza Fathi, Research Scientist, Google Research, Perception Team 大規...

コード生成を通じたモジュラーなビジュアル質問応答
投稿者:UCバークレーの博士課程生であるSanjay SubramanianとGoogle Researchの研究科学者であるArsha Nagrani、Perception ...
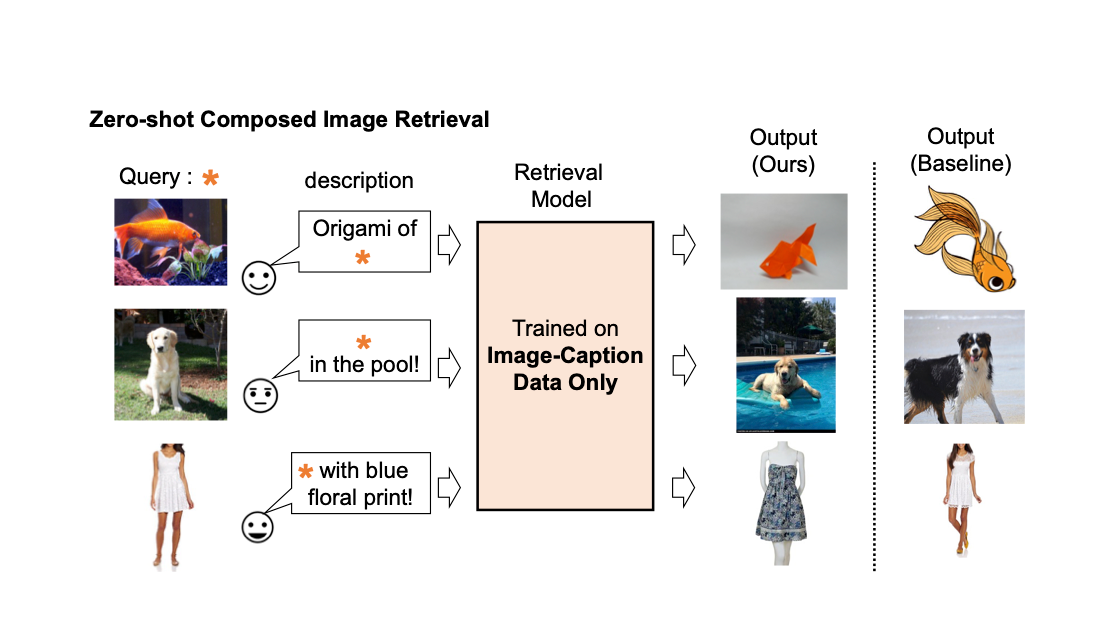
Pic2Word:ゼロショット構成画像検索のための写真から単語へのマッピング
Google Researchの学生研究者であるKuniaki SaitoとGoogle Researchの研究科学者であるKihyuk Sohnが投稿しました。 画像の検...
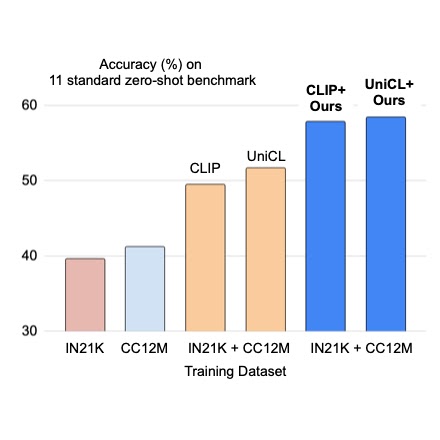
プレフィックス条件付きの画像キャプションと画像分類のデータセットの統合
クラウドAIチームの学生研究者である斎藤邦明と知識チームの研究科学者であるソン・キヒョクによる投稿 ウェブスケールの画像...

検索増強視覚言語事前学習
Google Research Perceptionチームの学生研究者Ziniu Huと研究科学者Alireza Fathiによる投稿 T5、GPT-3、PaLM、Flamingo、Pa...
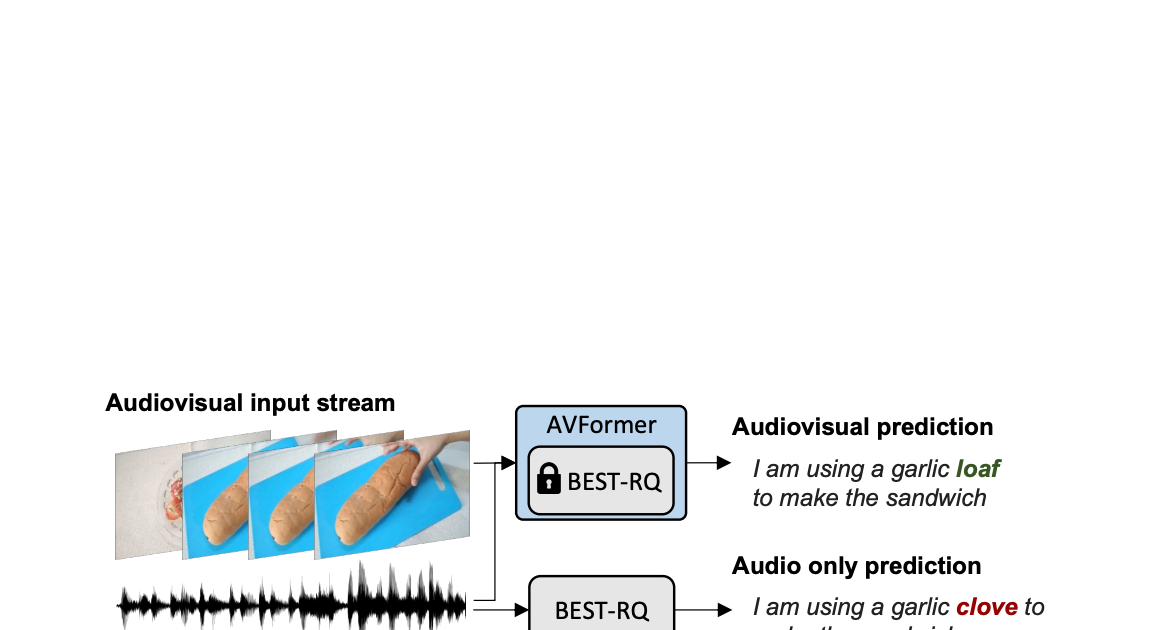
AVFormer:凍結した音声モデルにビジョンを注入して、ゼロショットAV-ASRを実現する
Google Researchの研究科学者、Arsha NagraniとPaul Hongsuck Seoによる投稿 自動音声認識(ASR)は、会議通話、ストリームビ...

- You may be interested
- 「持続的な学習:データサイエンティスト...
- マルチAIの協力により、大規模な言語モデ...
- データサイエンスによる在庫最適化:Pytho...
- 「言語の力を解き放つ:NVIDIAのアナマラ...
- イノベーションを推進するための重要なツ...
- マイクロソフトのAIチームがNaturalSpeech...
- 「IDEFICSをご紹介します:最新の視覚言語...
- 「23andMeにおける複数の個人情報漏洩」
- メタのボイスボックス:すべての言語を話すAI
- Amazon SageMaker、HashiCorp Terraform、...
- 「リアルタイムの高度な物体認識を備えたL...
- 合成データ生成のマスタリング:応用とベ...
- 「A.I.ブームで最も不可欠な賞を必死に追...
- 新しいAI論文で、CMUとGoogleの研究者が言...
- AudioPaLMの紹介:Googleの言語モデルにお...
Find your business way
Globalization of Business, We can all achieve our own Success.