複数の画像やテキストの解釈 Multimodal
「LLaVAと一緒にあなたのビジョンチャットアシスタントを作りましょう」
大規模な言語モデルは、革命的な技術であることが証明されていますその能力を活用した数多くのアプリケーションがすでに開発...

マルチモーダルデータ統合:人工知能ががん治療を革命へ導く
最近、私はこの記事(リンク)を読みましたそれは癌のための人工知能(AI)との多模式データ統合についてのものでした扱われ...

「比喩的に言えば、ChatGPTは生きている」
ChatGPTの成長は年々劇的に進んできました最近、OpenAIはChatGPTが聞くこと、見ること、話すことができるようになったことを...

「GPT-4を超えて 新機能は何ですか?」
「GPT-4を超えて:生成AIの4つの主要なトレンド:LLMからマルチモーダル、ベクトルデータベースへの接続、エージェントからOS...
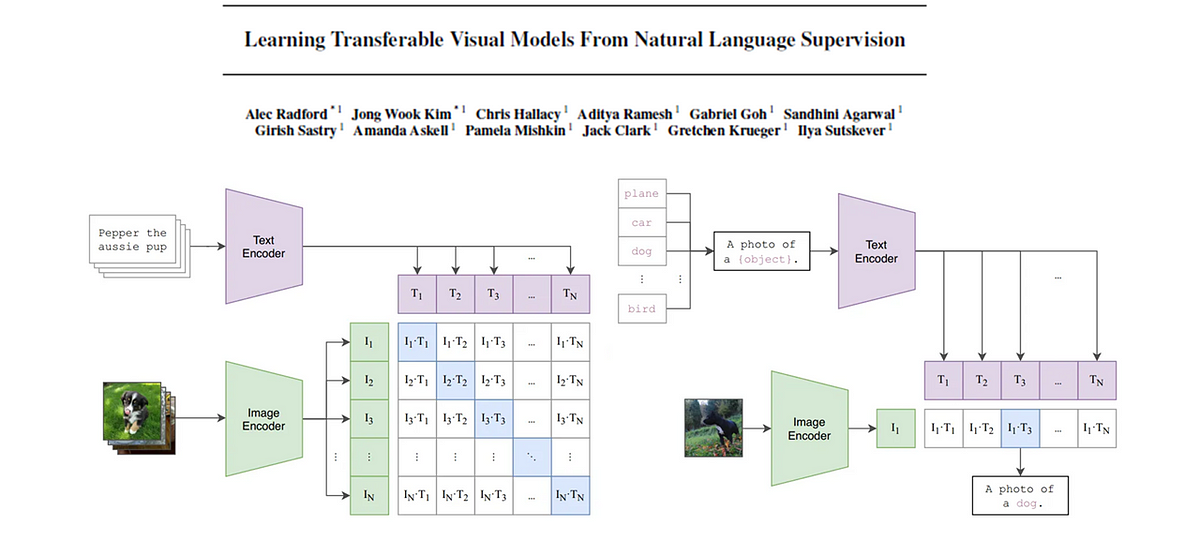
CLIP基礎モデル
この記事では、CLIP(対照的な言語画像事前学習)の背後にある論文を詳しく解説しますキーコンセプトを抽出し、わかりやすく...

- You may be interested
- 「Flick Review リーチを向上させるための...
- 2023年の音楽制作に最適なAIツール
- Google DeepMindの研究者がDiLoCoを導入:...
- 「質問、肩をすくめること、そして次は何...
- ChatGPTによって発明された10の感情(驚く...
- データは「何を」教えてくれますが、私た...
- Google Bardのビジュアル機能を活用する8...
- 「ODSCウェストからの9つのセッション、私...
- 「AUDITに会おう:潜在拡散モデルに基づく...
- 「InstagramがAIによって生成されたコンテ...
- 「脳活動計測と仮想現実の統合」
- 『Amazon Search M5がAWS Trainiumを使用...
- OpenAIがグローバルイルミネーションを引...
- 「ジェイソン・フラックスとともに会話型A...
- 「研究者がChatGPTを破った方法と、将来の...
Find your business way
Globalization of Business, We can all achieve our own Success.