複数の画像やテキストの解釈 Foundation Models

「DINO — コンピュータビジョンのための基盤モデル」
「コンピュータビジョンにとっては、エキサイティングな10年です自然言語の分野での大成功がビジョンの領域にも移されており...

BYOL(Bootstrap Your Own Latent)— コントラスティブな自己教示学習の代替手段
『今日の論文分析では、BYOL(Bootstrap Your Own Latent)の背後にある論文に詳しく触れますこれは、対比的な自己教師あり学...
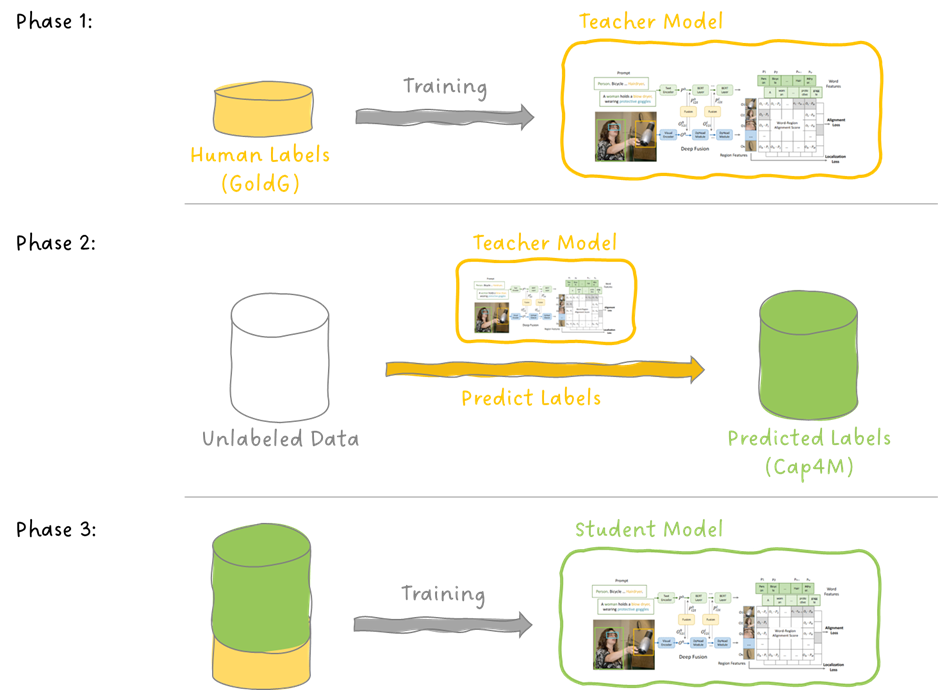
GLIP オブジェクト検出への言語-画像事前学習の導入
今日は、言語-画像の事前学習であるCLIPの素晴らしい成功を基に、物体検出のタスクに拡張した論文であるGLIPについて掘り下げ...
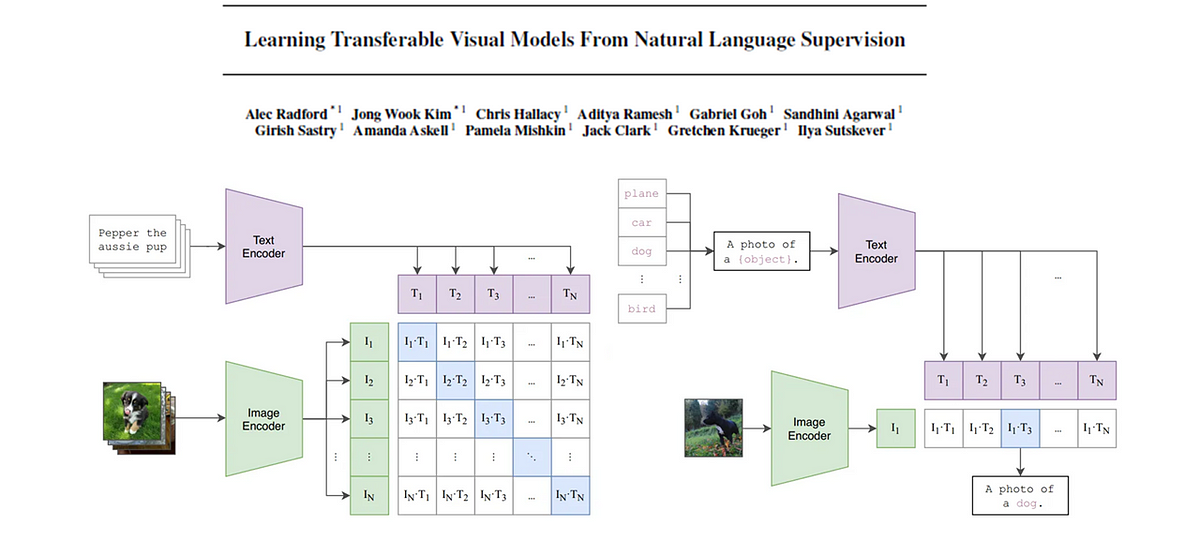
CLIP基礎モデル
この記事では、CLIP(対照的な言語画像事前学習)の背後にある論文を詳しく解説しますキーコンセプトを抽出し、わかりやすく...

「生成AI、基礎モデル、および大規模言語モデルの世界を探求する:概念、ツール、およびトレンド」
最近、人工知能(AI)は大きな進歩を遂げており、主にディープラーニングの進展によって推進されています昨年のChatGPTの登場...

- You may be interested
- 合成データプラットフォーム:構造化デー...
- KiliとHuggingFace AutoTrainを使用した意...
- 「AIルネサンス:デジタル時代における就...
- (Shōrai no toppu 10 de-ta saiensu no ky...
- 「Amazon SageMakerを使用して、マルチク...
- 「エンジニアは失敗を見つける使命に就い...
- マサチューセッツ大学アマースト校のコン...
- 言葉の解明:AIによる詩と文学の進化̵...
- Pythonアプリケーション | 速度と効率の向...
- 制限から自由:MoMAでのマシン幻覚の検証
- 「AWSサービスを使用して完全なウェブアプ...
- AI/DLの最新トレンドを探る:メタバースか...
- XGen-Image-1の内部:Salesforce Research...
- 「iPhoneに感染させるために使用された3つ...
- Google AI研究のTranslatotron 3:革新的...
Find your business way
Globalization of Business, We can all achieve our own Success.