複数の画像やテキストの解釈 Fine Tuning Transformer

テキストをベクトルに変換する:TSDAEによる強化埋め込みの非教示アプローチ
TSDAEの事前学習を対象ドメインで行い、汎用コーパスでの教師付き微調整と組み合わせることで、特化ドメインの埋め込みの品質...
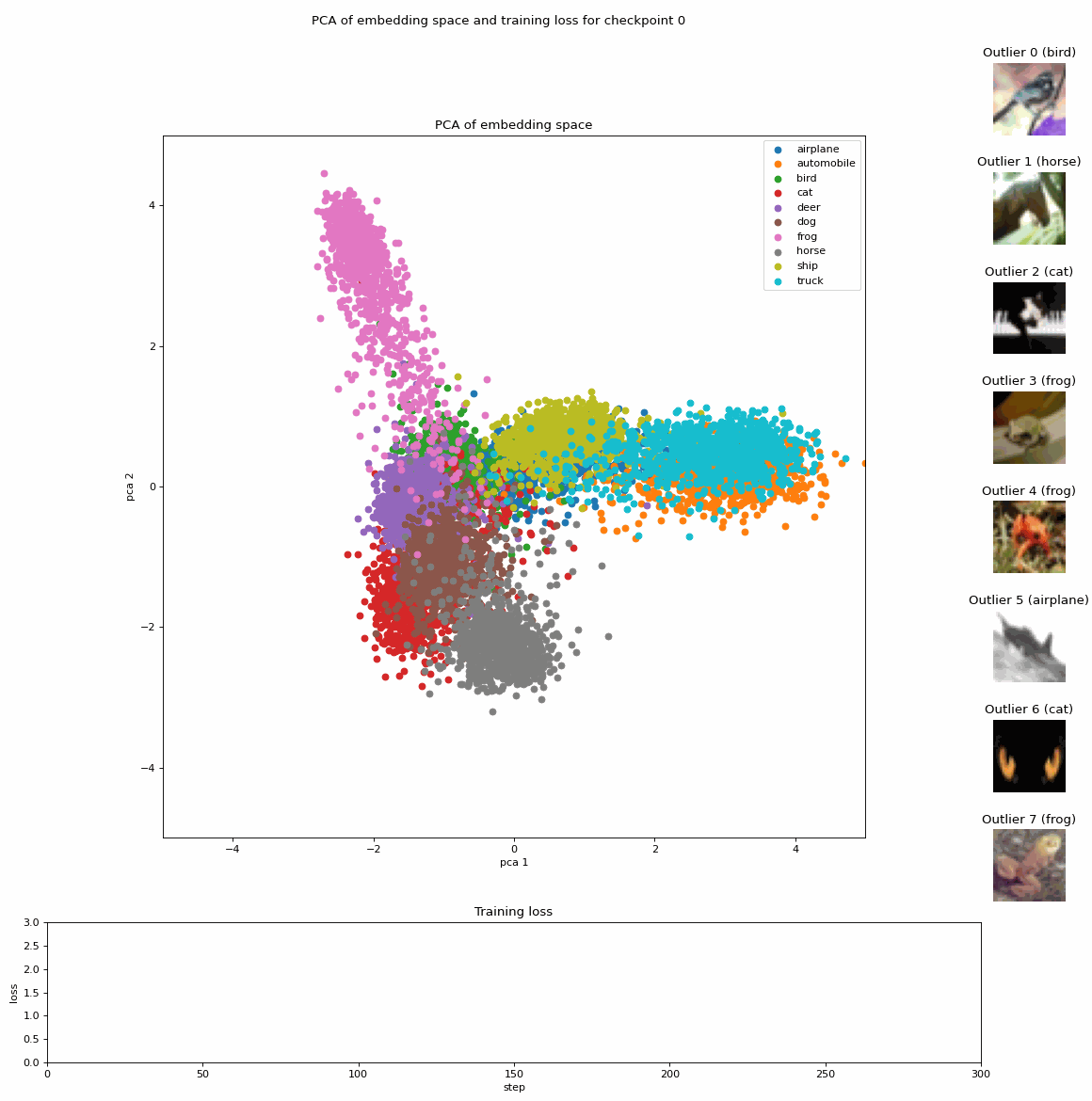
「ファインチューニング中に埋め込みのアニメーションを作成する方法」
「機械学習の分野では、ビジョントランスフォーマー(ViT)は画像分類に使用されるモデルの一種です従来の畳み込みニューラル...

- You may be interested
- 省エネAI:ニューロモーフィックコンピュ...
- 時間シリーズのフーリエ変換:画像畳み込...
- 「ChatGPTを使用してAI幻覚を回避する方法」
- 「ソフトウェア開発者のための機械学習フ...
- 「AI週間ニュース、2023年7月31日:」
- 「ピアソン、スピアマン、ケンドール相関...
- 「AIの力による消費者の支払い行動予測」
- GPT-4の主な6つの利用事例
- ファイル共有を簡単にする
- あなたのビジネスに適応型AIを実装する方法
- ETHチューリッヒとマイクロソフトの研究者...
- 2Dアセット生成:ゲーム開発のためのAI #4
- 「スローリー・チェンジング・ディメンシ...
- 「グラミー賞のCEOによる新しいAIポリシー...
- Office 365の移行と管理を外部委託する主...
Find your business way
Globalization of Business, We can all achieve our own Success.