複数の画像やテキストの解釈 Data science - Section 46

細かいところに悪魔が潜んでいる:ボックスから飛び出してPower BIのチャンピオンになろう
数週間前、私はクライアントのPower BIレポートのパフォーマンスチューニングに取り組んでいましたレポートのページが非常に...
ジェネラティブAI時代におけるデータキャリアの拡大
ジェネレーティブAI時代にデータキャリアを築くために、新たなデータプロフェッショナルが持つべき基本的な知識は、データ品...

モデルの精度にだまされない方法
分類モデルの性能評価に使用される指標は、数学的な観点から見れば比較的明快ですそれにもかかわらず、私は多くのモデラーと...
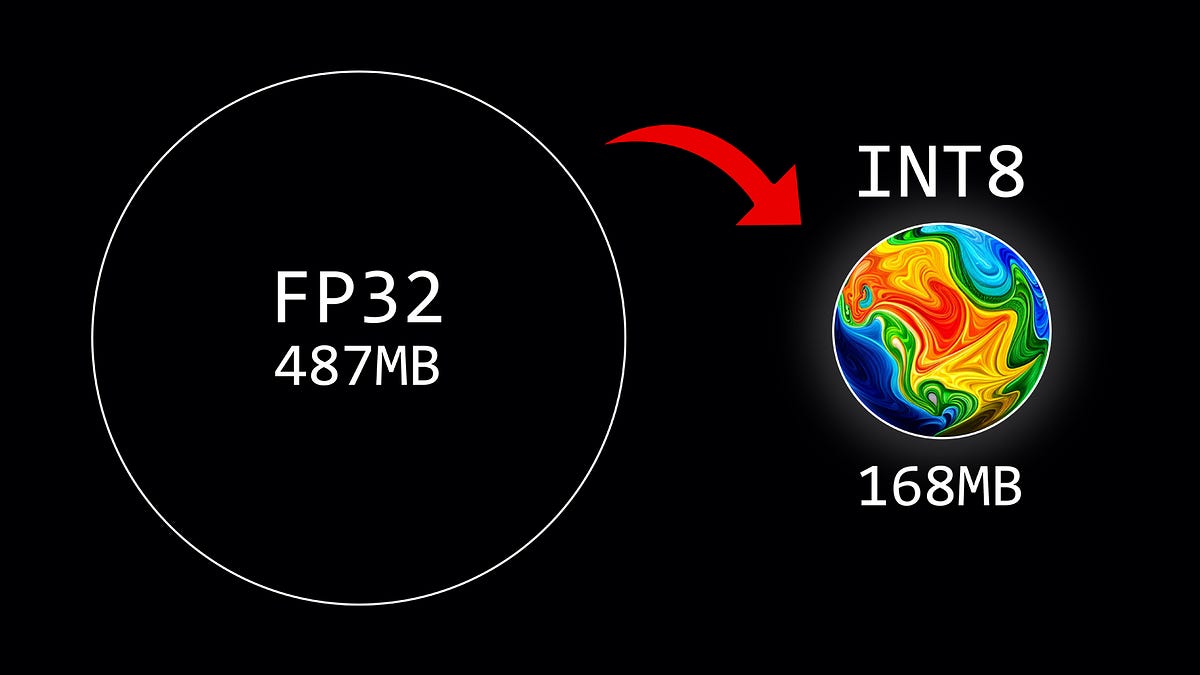
重み量子化の概要
この記事では、8ビットの量子化方式を使用して、大規模言語モデルのパラメータを量子化する方法について説明しています
極小データセットを用いたテキスト分類チャレンジ:ファインチューニング対ChatGPT
Toloka MLチームは、さまざまな条件下でのテキスト分類の異なるアプローチを継続的に研究し比較していますここでは、NLPのパ...
JAXの始め方
JAXは、Googleが開発したPythonライブラリであり、あらゆるタイプのデバイス(CPU、GPU、TPUなど)で高性能な数値計算を行う...
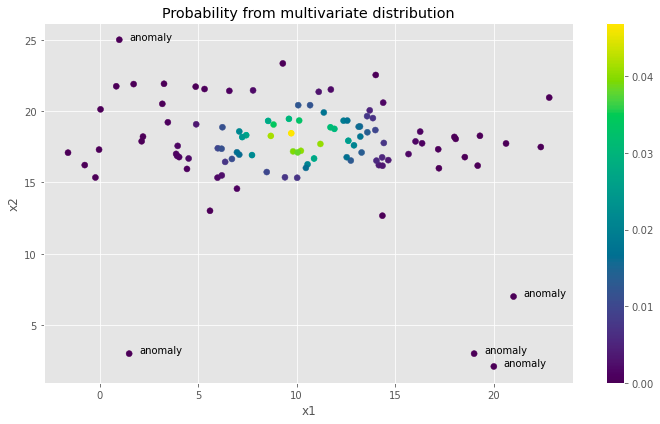
多変量ガウス分布による異常検知の基本
私たちの生まれつきのパターン認識能力によって、私たちはこのスキルを使って抜け落ちた部分を埋めたり、次に何が起こるかを...
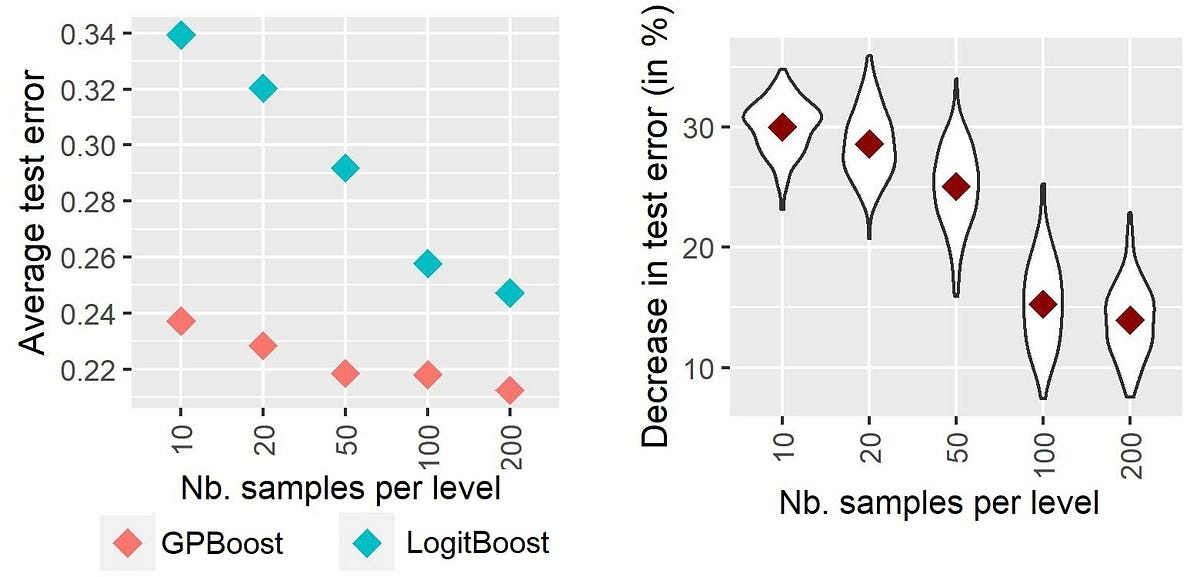
ハイカーディナリティのカテゴリカル変数に対する混合効果機械学習-第I部:異なる手法の実証的比較
高次元のカテゴリー変数のモデリングを向上させるための機械学習におけるランダム効果:アプローチの紹介と比較
自分の脳の季節性を活用した、1年間のデータサイエンスの自己学習プランの作成方法
ソーシャルメディアでは、最近自分自身でデータサイエンスを学んだ人々が3ヶ月でデータサイエンスを習得し、成功したという話...
探索的データ解析:データセットの中に隠されたストーリーを解き明かす
データの熱狂的な愛好家として、新しいデータセットの探索はワクワクする試みですこれにより、データのより深い理解を得るこ...

- You may be interested
- 「人生をゲームとして見るならば、それを...
- AIの検索アルゴリズム:最も人気のあるも...
- コーネル大学の研究者たちは、不連続処理...
- 文の補完のための言語モデル
- リアルタイムで命を救うビッグデータ:IoV...
- Twitterでの感情分析を始める
- マイクロソフトの研究者がPromptTTS 2を発...
- 『Talent.com』において
- 「デベロッパー用の15以上のAIツール(202...
- 「プラットプス:データセットのキュレー...
- 最終フロンティアの記録:30日間の#30DayM...
- 「私と一緒に読む:因果律の読書クラブ」
- 大規模言語モデルの評価:包括的かつ客観...
- 材料研究を革新するための機械学習の活用
- 「AudioLDM 2をご紹介します:音声、音楽...
Find your business way
Globalization of Business, We can all achieve our own Success.