複数の画像やテキストの解釈 Computer Vision - Section 44

DORSalとは 3Dシーンの生成とオブジェクトレベルの編集のための3D構造拡散モデル
人工知能は、Generative AIとLarge Language Models(LLMs)の導入により進化しています。GPT、BERT、PaLMなどのよく知られた...
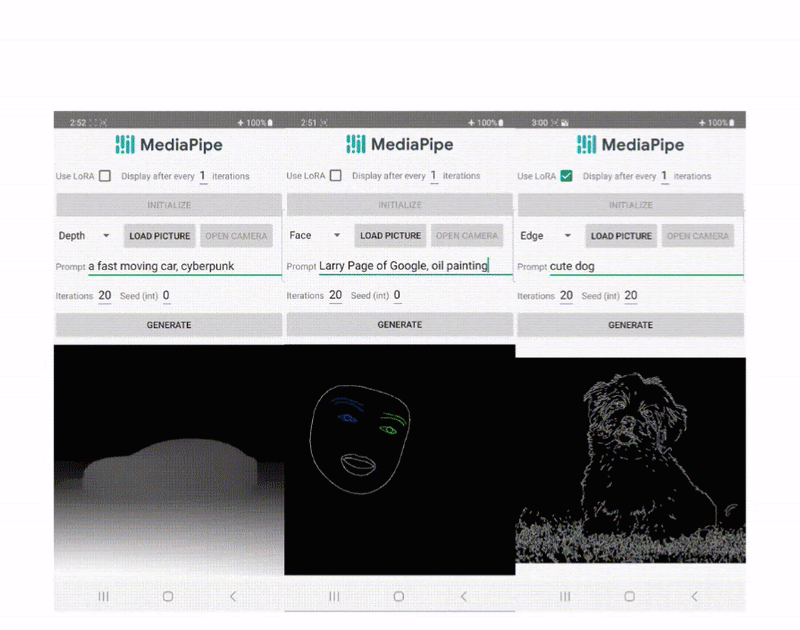
デバイス上での条件付きテキストから画像生成のための拡散プラグイン
Yang ZhaoとTingbo Houによる投稿、ソフトウェアエンジニア、Core ML 近年、拡散モデルはテキストから画像を生成する際に非常...

複雑なタスクの実行におけるロボットの強化:Meta AIが人間の行動のインターネット動画を使用して視覚的な手がかりモデルを開発する
メタAIは、先進的な人工知能(AI)研究機関であり、最近、ロボティクスの分野を革命的に変えると約束する画期的なアルゴリズ...
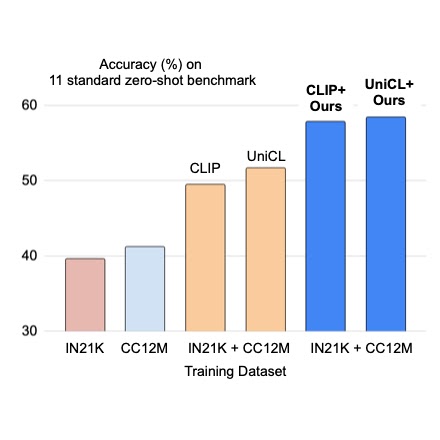
プレフィックス条件付きの画像キャプションと画像分類のデータセットの統合
クラウドAIチームの学生研究者である斎藤邦明と知識チームの研究科学者であるソン・キヒョクによる投稿 ウェブスケールの画像...
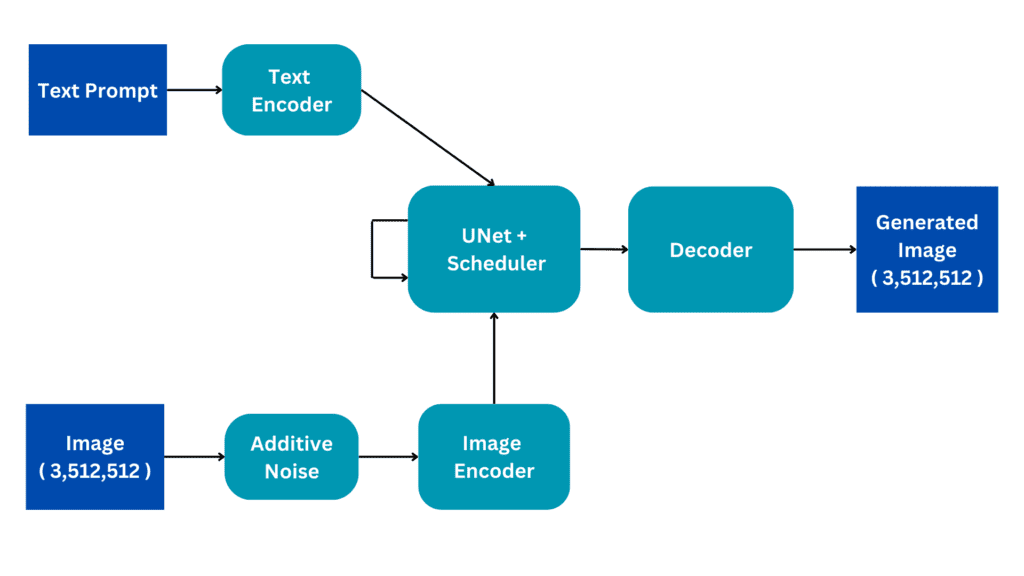
安定した拡散:生成AIの基本的な直感
この記事では、ステーブルディフュージョンについて一般的な概要を提供し、生成型人工知能がどのように動作するかの基本的な...

ProFusion における AI 非正則化フレームワーク テキストから画像合成における詳細保存に向けて
テキストから画像生成の領域は長年にわたって広範に研究され、最近では大きな進歩がなされています。研究者たちは、大規模な...

コンピュータビジョンシステムは、画像認識と生成を結びつけたものです
MAGEは、通常は別々に訓練される画像生成と認識の2つの主要なタスクを1つのシステムに統合します

フィールドからフォークへ:スタートアップが食品業界にAIのスモーガスボードを提供
それは魔法のように機能しました。データセンターで実行されているコンピュータービジョンアルゴリズムが、インドの遠い小麦...
このスペースを見る:AIを使用してリスクを推定し、資産を監視し、クレームを分析する新しい空間金融の分野
金融の意思決定をする際には、ドローン、衛星、またはAIパワードセンサーから取得した大局的な情報を見ることが重要です。 空...

NVIDIA H100 GPUがMLPerfベンチマークのデビューで生成型AIの標準を設定
主要のユーザーと業界標準のベンチマークによれば、NVIDIAのH100 Tensor Core GPUは特に生成型AIを駆動する大規模言語モデル...

- You may be interested
- 「月に10000ドルを稼ぐために私が使用する...
- 「大規模なラスター人口データの探索」
- 「ナレ・ヴァンダニャン、Ntropyの共同創...
- 文書解析の革命:階層構造抽出のための最...
- 気候変動との戦いをリードする6人の女性
- Googleはチャットボットの使用について従...
- アップルの研究者が提案する「大規模な言...
- 「ワイルドワイルドRAG…(パート1)」
- 「SQLで移動平均と累積合計をマスターする...
- 「大規模言語モデルの謎解き:インフルエ...
- このAI研究は、ポイントクラウドを2D画像...
- スタンフォード、NVIDIA、およびUT Austin...
- このAI論文は、大規模言語モデルに対する...
- 「Matplotlibを使用してリップスティック...
- 「ターシャーに会ってください:GPT4のよ...
Find your business way
Globalization of Business, We can all achieve our own Success.