複数の画像やテキストの解釈 Computer Vision - Section 42

コード生成を通じたモジュラーなビジュアル質問応答
投稿者:UCバークレーの博士課程生であるSanjay SubramanianとGoogle Researchの研究科学者であるArsha Nagrani、Perception ...

セグメントエニシングモデル:画像セグメンテーションの基礎モデル
「メタAI 最新のユニバーサルセグメンテーションモデルの理解」

CVモデルの構築と展開:コンピュータビジョンエンジニアからの教訓
コンピュータビジョン(CV)モデルの設計、構築、展開の経験を3年以上積んできましたが、私は人々がこのような複雑なシステム...

DragonDiffusionをご紹介します:拡散モデルでのドラッグスタイル操作を可能にする細かい画像編集手法
大規模なテキストから画像(T2I)の拡散モデルは、与えられたテキスト/プロンプトに基づいて画像を生成することを目指してお...
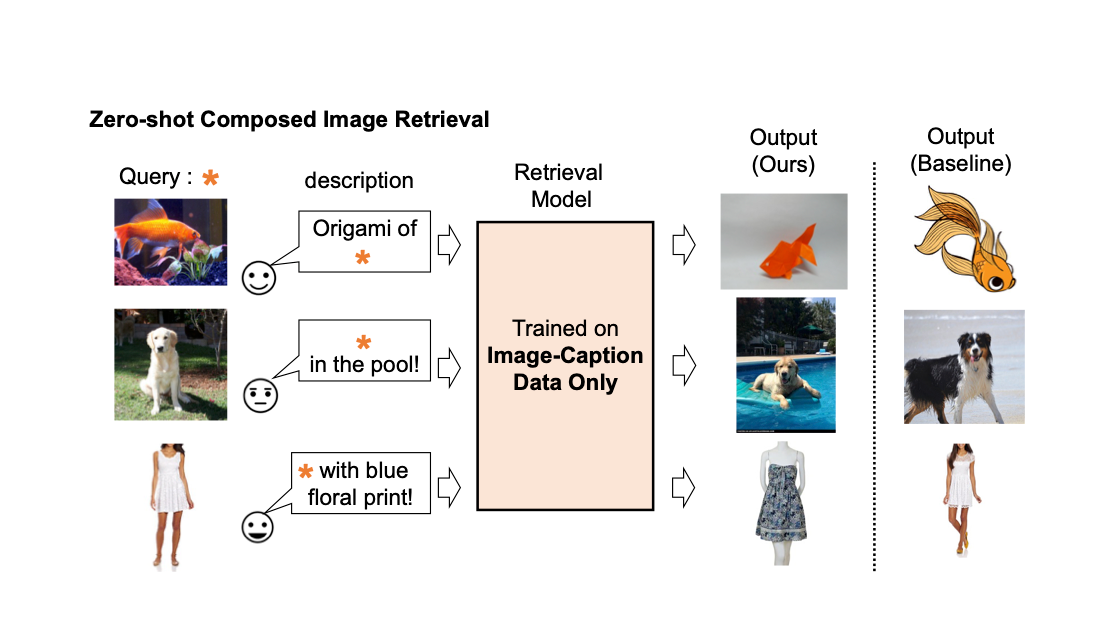
Pic2Word:ゼロショット構成画像検索のための写真から単語へのマッピング
Google Researchの学生研究者であるKuniaki SaitoとGoogle Researchの研究科学者であるKihyuk Sohnが投稿しました。 画像の検...

SAM-PTとは SAM(Segment Anything Model)の機能を拡張し、動画内の任意のオブジェクトのトラッキングとセグメンテーションを可能にする、新しいAIメソッドです
ロボティクス、自動運転、ビデオ編集など、多くのアプリケーションはビデオセグメンテーションの恩恵を受けています。深層ニ...

HuggingFace Researchが紹介するLEDITS:DDPM Inversionと強化された意味的なガイダンスを活用したリアルイメージ編集の次なる進化
テキストガイド拡散モデルを利用した写真生成の現実感と多様性の向上により、関心が大幅に高まっています。大規模モデルの導...

3Dで「ウォーリーを探せ」をプレイする:OpenMask3Dは、オープンボキャブラリークエリを使用して3Dでインスタンスをセグメント化できるAIモデルです
画像セグメンテーションは、ニューラルネットワークの進歩により、過去10年間で大きく進歩しました。複雑なシーンで複数のオ...

ウィスコンシン大学とバイトダンスの研究者は、PanoHeadを紹介しますこれは、単一のビュー画像のみでビュー一貫性のあるフルヘッド画像を合成する、初の3D GANフレームワークです
コンピュータビジョンとグラフィックスでは、写真のような写実的な肖像画像合成が常に強調されており、仮想アバター、テレプ...

コンピュータビジョンが脳のように機能するとき、それは人々が見るようにもっと見ることができます
実際の脳からのデータを使用して人工ニューラルネットワークを訓練することにより、コンピュータビジョンをより堅牢にするこ...

- You may be interested
- デジタル変革によって打撃を受ける可能性...
- 「AIと著作権に関する公開意見募集中の米...
- 「モバイルアプリに予測分析を活用する8つ...
- 「5つの最高のオープンソースLLM」
- Google at ACL 2023′ ACL 2023にお...
- UCサンディエゴとMeta AIの研究者がMonoNe...
- 「なぜ自分自身のLLMモデルを所有すること...
- 「5つのステップでPyTorchを始めましょう」
- 「AIの擬人化:人間が共感を求める場所を...
- 効果的なコーディングルーティンを開発す...
- 『ODSCのAIウィークリーレビュー:12月15...
- ジェネレーティブAIツールを使用する際に...
- NVIDIAの最高科学者、ビル・ダリー氏がHot...
- コンテンツクリエイター向けの20のクロー...
- 「このディスインフォメーションはあなた...
Find your business way
Globalization of Business, We can all achieve our own Success.