複数の画像やテキストの解釈 Computer Vision - Section 31

「ビデオ編集はもはや難問ではありません:INVEはインタラクティブなニューラルビデオ編集を可能にするAI手法です」
イメージ編集なしのインターネットを想像することができますか? すべての面白いミーム、素敵なインスタグラムの写真、魅力的...

思っているベイダーではありません 3D VADERは3Dモデルを拡散するAIモデルです
イメージ生成はこれまでにないほど簡単になりました。生成型AIモデルの台頭により、プロセスは本当に簡単になりました。まる...

このAI研究では、詳細な全身のジオメトリと高品質のテクスチャを持つ、リアルな3Dの服を着た人物を、単一の画像から再構築するためのテクノロジー(TeCH)を提案します
ハイフィデリティ ゲーム、ソーシャルネットワーキング、教育、eコマース、没入型テレプレゼンスなど、多くの拡張現実と仮想...

「ペンの向こう側:視覚的な原型からの手書きテキスト生成におけるAIの芸術性」
個々の作家の独自の書道スタイルを再現する手書きテキスト生成(HTG)という新興の分野は、手書きテキスト認識(HTR)モデル...

CMUの研究者たちは、視覚的な先行知識をロボティクスのタスクに転送するためのシンプルなディスタンスラーニングAIメソッドを開発しました:ベースラインに比べてポリシーラーニングを20%改善
ロボット学習における重要な障壁の一つは、十分な大規模データセットの不足です。ロボティクスのデータセットには、(a)スケー...

スウィン・トランスフォーマー | モダンなコンピュータビジョンタスク
イントロダクション Swin Transformerは、ビジョントランスフォーマーの分野における重要なイノベーションです。トランスフォ...
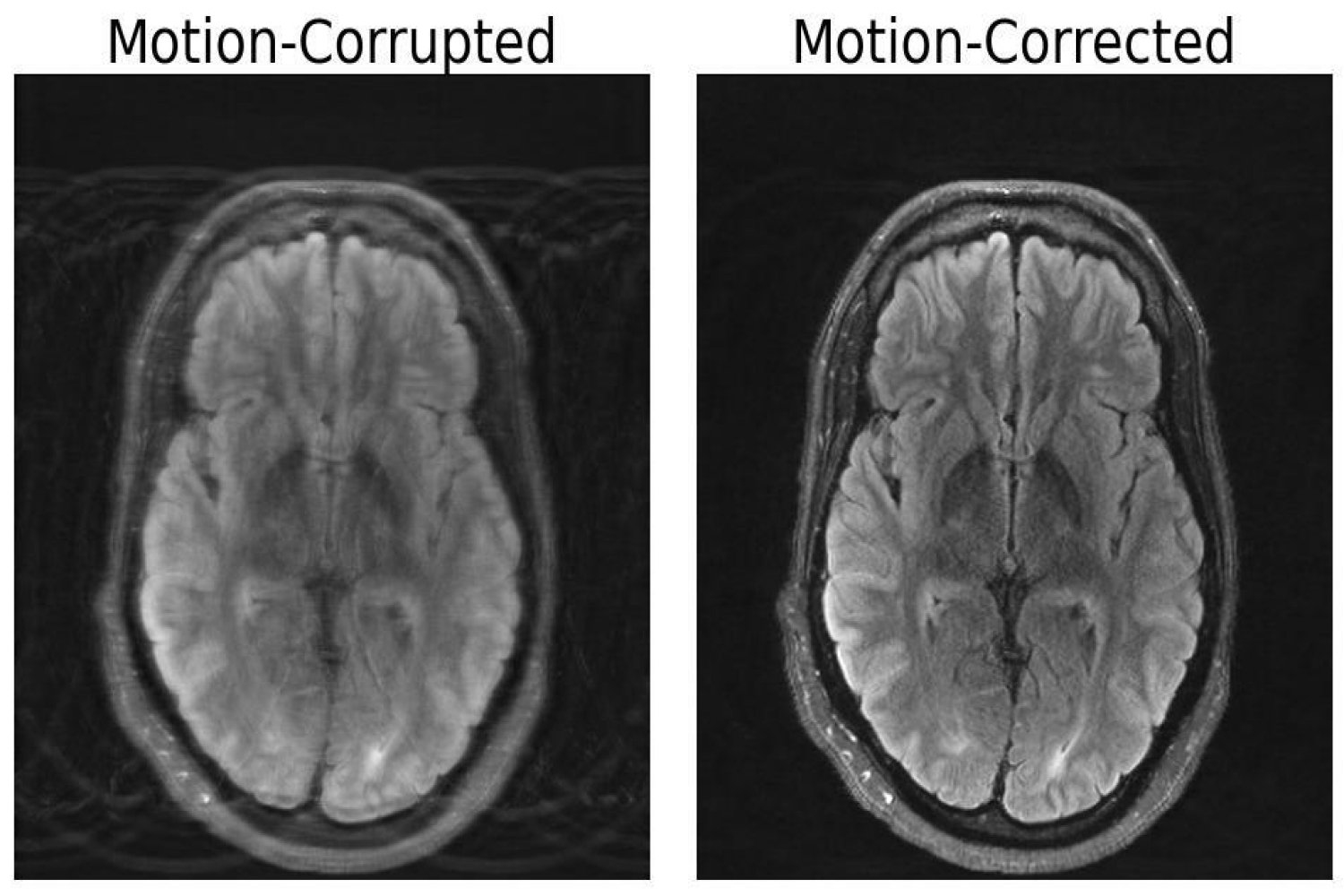
MITの研究者は、ディープラーニングと物理学を組み合わせて、動きによって損傷を受けたMRIスキャンを修正する方法を開発しました
「この課題は、ぼやけたJPEG画像以上のものです医療画像の動きのアーティファクトを修正するには、より高度なアプローチが必...

「NTUとSenseTimeの研究者が提案するSHERF:単一の入力画像からアニメーション可能な3D人間モデルを復元するための汎用的なHuman NeRFモデル」
人工知能(AI)およびディープラーニングの分野は、常に急速に進化しています。自然言語処理に基づく大規模な言語モデルから...
「Cheetorと会ってください:幅広い種類の交互に織り交ぜられたビジョン言語の指示を効果的に処理し、最先端のゼロショットパフォーマンスを達成する、Transformerベースのマルチモーダルな大規模言語モデル(MLLMs)」
教示的なスタイルで言語タスクのグループに対する指示のチューニングを通じて、大規模言語モデル(LLM)は最近、さまざまな活...

「3D-VisTAに会いましょう:さまざまな下流タスクに簡単に適応できる、3Dビジョンとテキストの整列のための事前学習済みトランスフォーマー」
人工知能のダイナミックな景観では、進化が可能性の境界を再構築しています。三次元の視覚理解と自然言語処理(NLP)の複雑さ...

- You may be interested
- 「Scikit-Learnによるアンサンブル学習:...
- LangFlow | LLMを使用してアプリケーショ...
- 「Java での AI:Spring Boot と LangChai...
- 「MLCommonsがAIモデルを実行するための新...
- 「ダウンフォール」の欠陥が世代を超えた...
- 「データサイエンスを使って、トップのTwi...
- OpenAIがBaby Llamaを発表 – 低電力...
- 5分であなたのStreamlitウェブアプリを展...
- モデルの自信を求めて ブラックボックスを...
- Amazon SageMaker Studioで生産性を向上さ...
- MITの研究者が新しいAIツール「PhotoGuard...
- 新しいAmazon SageMakerコンテナでLLMの推...
- 「RustコードのSIMDアクセラレーションの...
- 「密度プロンプトのチェーンを通じたGPT-4...
- 「将来に備えたデータゲーム:2023年に必...
Find your business way
Globalization of Business, We can all achieve our own Success.