複数の画像やテキストの解釈 Computer Vision - Section 24

「BLIVAと出会ってください:テキスト豊かなビジュアル質問をより良く扱うためのマルチモーダルな大規模言語モデル」
最近、大規模言語モデル(LLMs)は、自然言語理解の分野で重要な役割を果たしており、ゼロショットやフューショットのシナリ...

2023年にディープラーニングのためのマルチGPUシステムを構築する方法
「これは、予算内でディープラーニングのためのマルチGPUシステムを構築する方法についてのガイドです特に、コンピュータビジ...

「Würstchenをご紹介します:高速かつ効率的な拡散モデルで、テキスト条件付きコンポーネントは画像の高圧縮潜在空間で動作します」
テキストから画像を生成することは、テキストの説明から画像を作成する人工知能の難しい課題です。この問題は計算量が多く、...

「リソース制約のあるアプリケーションにおいて、スパースなモバイルビジョンMoEsが密な対応物よりも効率的なビジョンTransformerの活用を解き放つ方法」
ミクスチャー・オブ・エキスパート(MoE)と呼ばれるニューラルネットワークのアーキテクチャは、さまざまなエキスパートニュ...

「MITの研究者が、デバイス内の意味的セグメンテーションのための新しい軽量マルチスケールアテンションを紹介」
セマンティックセグメンテーションは、コンピュータビジョンの基本的な課題であり、入力画像の各ピクセルを特定のクラスに分...

「なんでもセグメント:任意のオブジェクトのセグメンテーションを促す」
今日の論文解説はビジュアルになります!私たちはMetaのAI研究チームによる論文「Segment Anything」を分析しますこの論文は...

テルアビブとコペンハーゲン大学からの新しいAI研究は、識別信号を使用して、テキストから画像への拡散モデルを迅速に微調整するための「プラグアンドプレイ」アプローチを紹介しています
テキストから画像への拡散モデルは、入力テキストの説明に基づいて多様で高品質な画像を生成することで印象的な成功を収めて...
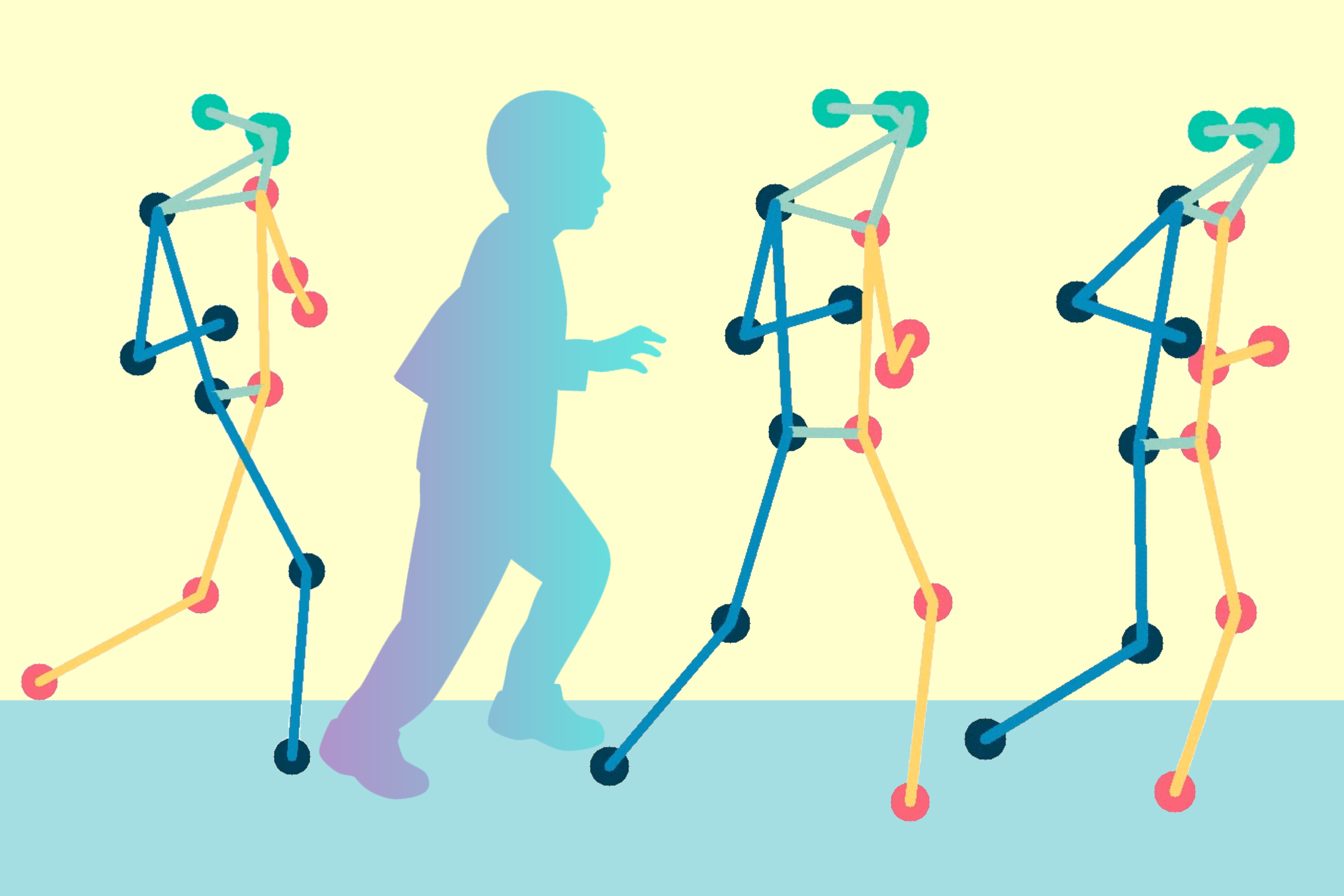
「ポーズマッピング技術によって、脳性麻痺の患者を遠隔で評価することができます」
「機械学習の手法は、ほとんどのモバイルデバイスで動作し、医師のオフィス以外の他の運動障害の評価にも拡張することができ...

クローズドソース対オープンソース画像注釈
このブログでは、オープンソースとクローズドソースの画像注釈ツールを比較し、それがAIモデル開発者の生活を簡単かつ便利に...

マイクロソフトの研究者が「InstructDiffusion:コンピュータビジョンタスクを人間の指示に合わせるための包括的かつ汎用的なAIフレームワーク」というタイトルで発表しました
マイクロソフトリサーチアジアの研究者たちは、適応性のある汎用的なビジョンモデルに向けた画期的な進展であるInstructDiffu...

- You may be interested
- エッジMLのタイプとエンタープライズのユ...
- コンピュータ科学者がAIを活用して危険な...
- 「Amazon Comprehendのカスタム分類を使用...
- 「Pantsを使用してMachine LearningのMono...
- このAI研究は、OpenAIの埋め込みを使用し...
- 「2023年の最高の声クローニングソフトウ...
- 「効果的なマーケティング戦略開発のため...
- 「メタのラマ2がOpenAIのChatGPTに挑戦:A...
- 「完璧なPythonデータ可視化のためのAIプ...
- 「AI倫理ツールキットが機能する理由を探る」
- 「Pythonを使用して、複数のファイル(ま...
- 「Langchainとは何ですか?そして、大規模...
- このAI研究では、LSS Transformerを発表し...
- 「機械学習のための完璧なデータ注釈プロ...
- 「対数正規分布の簡単な説明」
Find your business way
Globalization of Business, We can all achieve our own Success.