複数の画像やテキストの解釈 audio - Section 2

「音のシンフォニーを解読する:音楽工学のためのオーディオ信号処理」
異なる種類のデータを処理し分析し、実用的な洞察を得る能力は、情報時代で最も重要なスキルの1つですデータは私たちの周りに...

「オーディオ機械学習入門」
「現在、音声音声認識システムを開発しているため、それに関する基礎知識を再確認する必要がありましたこの記事はその結果で...

メタが「AudioCraft」を発表:テキストを音声や音楽に変換するためのAIツール
Metaは、Facebook、Instagram、WhatsAppなどのソーシャルメディアプラットフォームを展開しているテックジャイアントであり、...

スポティファイはAIを取り入れる:個人に合わせたプレイリストからオーディオ広告まで
人気のある音楽ストリーミングプラットフォームであるSpotifyは、常にユーザーエクスペリエンスを向上させる方法を探求する技...

小さなオーディオ拡散:クラウドコンピューティングを必要としない波形拡散
2GB以下のVRAMを持つコンシューマーラップトップとGPUでオーディオ波形拡散を用いてモデルをトレーニングし、音を生成する方...
AudioPaLMの紹介:Googleの言語モデルにおける突破口
テック巨人Googleが、ジェネラティブAIの分野で重要な進展を遂げ、最先端のマルチモーダル言語モデルであるAudioPaLMを発表し...

ウィンブルドンがAIによる実況を導入
テニス愛好家にとって素晴らしいニュースです!世界で最も権威のあるテニストーナメントの一つであるウィンブルドンは、最新...

AIがYouTubeの多言語吹替を開始します
世界最大の動画共有プラットフォームであるYouTubeは、AI技術の統合により、コンテンツクリエイターが世界中の観客と接触する...
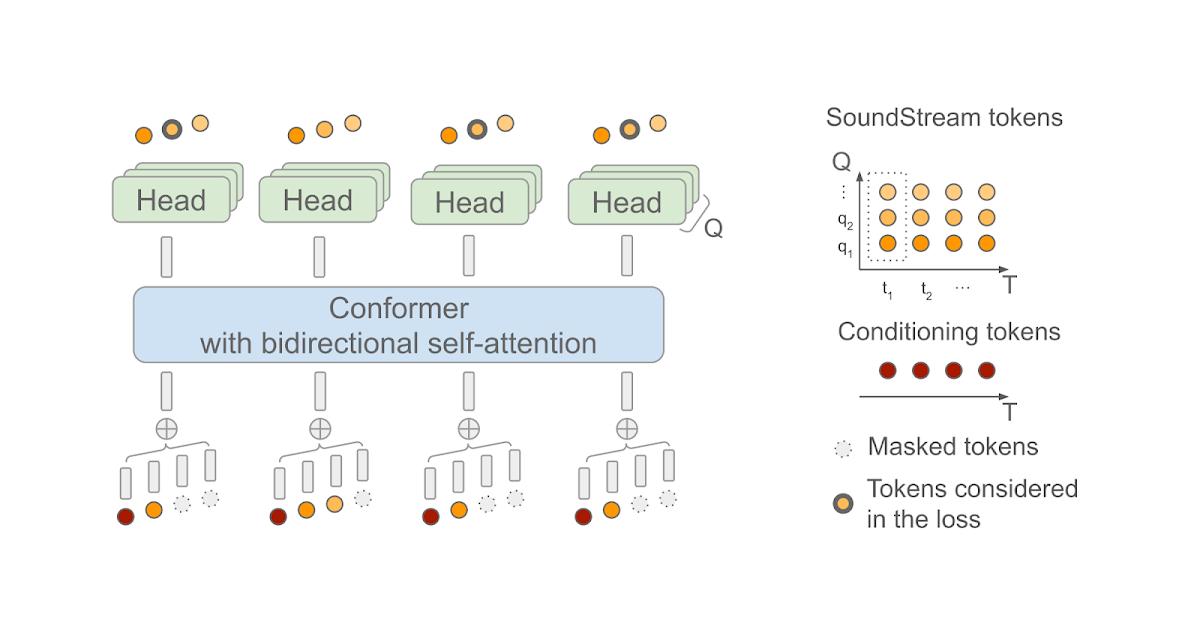
SoundStorm:効率的な並列音声生成
Zalán Borsos氏(リサーチソフトウェアエンジニア)とMarco Tagliasacchi氏(シニアスタッフリサーチサイエンティスト)がGoo...
メタのボイスボックス:すべての言語を話すAI
Facebookの親会社であるMetaは画期的な開発を発表し、最新の生成型人工知能(AI)であるVoiceboxを公開しました。従来のテキ...

- You may be interested
- 「Amazon Personalizeと生成AIでマーケテ...
- 関数呼び出し:GPTチャットボットを何にで...
- 言語ドメインにおける画期的かつオープン...
- あなたは優れたEDAフレームワークを持って...
- 「機械学習支援コンピュータアーキテクチ...
- 「成功したプロンプトの構造の探索」
- 医師たちはバーチャルリアリティでトレー...
- 「AmazonがAIによるレビューの要約を導入」
- 「クロスファンクションの機械学習プロジ...
- 「クリスマスラッシュ」3Dシーンが今週の...
- 「AIとオペレーション管理 – 天国で...
- 「ファクトテーブルとディメンションテー...
- ピクセルを説明的なラベルに変換する:Ten...
- 「中国のロボットウェイターが韓国の労働...
- Note This translation conveys the same ...
Find your business way
Globalization of Business, We can all achieve our own Success.