「ToolLLMをご紹介します:大規模言語モデルのAPI利用を向上させるためのデータ構築とモデルトレーニングの一般的なツールユースフレームワーク」
ToolLLM A general tool framework for data construction and model training to improve the use of large-scale language model APIs.


多くのツール(API)と効率的に接続し、困難なタスクを完了するために、ツール学習は大規模な言語モデル(LLM)の潜在能力を活用しようとします。 LLMは、APIとの接続により、消費者と大規模なアプリケーションエコシステムとの効果的な仲介役としての価値を大幅に高めることができます。オープンソースのLLMであるLLaMAやVicunaなどの指示チューニングにより、さまざまな機能を持つことができましたが、ユーザーの指示を理解し、ツール(API)との効果的なインターフェースを実現するなど、より高度なタスクを処理する必要があります。これは、現在の指示チューニングが主に単純な言語タスク(例:カジュアルチャット)に焦点を当てているためです。
一方、ツールの使用に優れたスキルを持つGPT-4などの最新の状態-of-the-art(SOTA)LLMは、クローズドソースであり、内部動作に不透明です。そのため、コミュニティ主導のイノベーションやAI技術の民主化の幅が制約されます。このような観点では、オープンソースのLLMがさまざまなAPIを適切に理解できるようにすることが重要であると見なされています。以前の研究では、ツールの使用に対する指示チューニングデータの作成に取り組んでいましたが、内在的な制約により、LLM内のツールの使用能力を完全に刺激することはできませんでした。 (1) 制約されたAPI:現実のAPI(RESTAPIなど)を無視するか、十分な多様性を持たない狭い範囲のAPIのみを考慮しています。 (2) 制約されたシナリオ:既存の研究は、単一のツールのみを使用する指示に限定されています。一方、現実の設定では、多数のツールを組み合わせて多ラウンドのツール実行を行い、困難なタスクを完了する必要がある場合があります。
さらに、多数のAPIが提供されている場合、ユーザーが特定のコマンドに最適なAPIセットを事前に決定することを前提としていますが、これは不可能です。 (3) 低品質な計画と推論:既存の研究では、モデルの推論のために単純なプロンプトメカニズム(チェーンオブソートやReACTなど)が使用されており、完全にLLMにエンコードされた能力を引き出すことができず、複雑な指示を処理することができません。これは、オープンソースのLLMにとって特に深刻な問題であり、SOTAのLLMよりも推論能力がはるかに劣っています。さらに、一部の研究では、後続のモデル開発において重要なデータである真の応答を取得するためにさえAPIを使用していません。彼らは、オープンソースのLLM内でツールの使用能力を刺激するためのデータ生成、モデルトレーニング、評価のための一般的なツール使用フレームワークであるToolLLMを提案します。
- 「データクリーニングと前処理の技術をマスターするための7つのステップ」
- 「LP-MusicCapsに会ってください:データの乏しさ問題に対処するための大規模言語モデルを使用したタグから疑似キャプション生成アプローチによる自動音楽キャプション作成」
- 「ゼロから効果的なデータ品質戦略を構築するためのステップバイステップガイド」
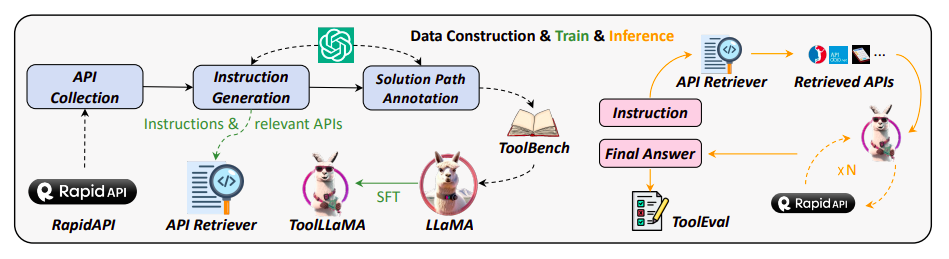
指示の推論中にAPIリトリーバーが関連するAPIをToolLLaMAに提案し、ToolLLaMAは最終結果に到達するために多くのAPI呼び出しを行います。ToolEvalは審議の全体プロセスを評価します。
彼らはまず、図1に示すような高品質の指示チューニングデータセットであるToolBenchを収集します。最新のChatGPT(gpt-3.5-turbo-16k)を使用して、自動的に生成されます。表1には、ToolBenchと以前の取り組みの比較が示されています。特に、ToolBenchの作成には3つのステージがあります:
• APIの収集:RapidAPI2から16,464のREST(表現状態転送)APIを収集します。このプラットフォームには、開発者によって提供される実世界のAPIが多数あります。これらのAPIは、eコマース、ソーシャルネットワーキング、天気など、49の異なる領域をカバーしています。各APIの包括的なAPIドキュメントをRapidAPIからスクレイプし、機能の要約、必要な入力、API呼び出しのためのコードサンプルなどを含めます。モデルがトレーニング中に遭遇しなかったAPIにも汎化するために、LLMがこれらのドキュメントを理解することでAPIを利用することを学ぶことを期待しています。
• Instruction Generation(指示生成):彼らはまず、全体のAPIコレクションからいくつかのAPIを選び、ChatGPTにこれらのAPIに関するさまざまな指示を開発するように依頼します。シングルツールとマルチツールのシナリオをカバーする指示を選択し、実世界の状況をカバーします。これにより、モデルはさまざまなツールを個別に扱う方法と、それらを組み合わせて難しいタスクを完了する方法を学ぶことができます。
• Solution Path Annotation(解決経路の注釈):彼らはこれらの指示に対する優れた回答をハイライトします。各応答には、モデルの推論とリアルタイムのAPIリクエストの複数のイテレーションが含まれる場合があります。最も高度なLLMであるGPT-4ですら、複雑なコマンドの成功率が低いため、ツールの学習の固有の難しさにより、データ収集が効果的でなくなります。このため、彼らはユニークな深さ優先探索ベースの意思決定木(DFSDT)を作成し、LLMsの計画と推論の能力を向上させることでこれに対処します。従来の思考の連鎖(CoT)やReACTに比べて、DFSDTはLLMsがさまざまな論理を評価し、戻るか続行するかを判断する能力を持たせます。研究では、DFSDTはCoTやReACTを使用して返答できない難しい指示を効果的に完了し、注釈の効率を大幅に向上させます。
清華大学、ModelBest社、中国人民大学、イェール大学、WeChat AI、テンセント社、知乎社の研究者たちは、ChatGPTをサポートする自動評価システムであるToolEvalを作成し、LLMsのツール使用能力を評価しました。ToolEvalには2つの重要なメトリックが含まれています:(1)勝率(win rate)は、2つの解決アプローチの価値と効用を対比するものであり、(2)合格率(pass rate)は、制約されたリソース内での指示の実行能力を評価するものです。ToolEvalは人間の評価と強く関連しており、正確で拡張性があり、一貫したツール学習の評価を提供します。彼らはToolBench上のLLaMAを最適化することで、ToolLLaMAを得ました。
ToolEvalを使用した分析の結果、彼らは以下の結論に至りました:
• ToolLLaMAは、シンプルなシングルツールと洗練されたマルチツールの両方の指示を処理する能力が魅力的です。ToolLLaMAは新しいAPIに対して成功裏に一般化するためにAPIドキュメントのみを必要とし、これはこの分野で特異なものです。この適応性により、ユーザーは新しいAPIをスムーズに統合することができ、モデルの実世界の応用価値を高めることができます。12k以上のインスタンスで最適化されたにもかかわらず、ToolLLaMAは「教師モデル」とされるChatGPTと同等のツール使用性能を達成しています。
• 彼らはDFSDTがLLMsの推論能力を向上させるための広範な意思決定手法として機能することを示しています。
DFSDTは、さまざまな推論軌跡を考慮に入れることで、ReACTを上回るパフォーマンスを発揮します。さらに、ChatGPTに各指示に適切なAPIを提案させ、このデータを使用してニューラルAPI検索プログラムを訓練します。実際には、この解決策により、膨大なAPIプールからの手動選択の必要がなくなります。ToolLLaMAとAPI検索プログラムを効果的に統合することができます。図1に示すように、API検索プログラムは指示に対して関連するAPIのコレクションを提案し、それが最終的な回答を決定するためにToolLLaMAに転送されます。彼らは、検索プログラムが広範なAPIプールを整理しながら、実際のデータに密接に一致するAPIを返す驚異的な検索精度を示しています。結論として、この研究はオープンソースのLLMsが現実の状況でさまざまなAPIを使用して複雑なコマンドを実行することを可能にすることを目指しています。彼らはこの研究がツール使用と指示の調整の関係をさらに調査することを期待しています。また、彼らはGitHubページでデモとソースコードを提供しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
