多言語での音声合成の評価には、SQuIdを使用する
To evaluate multilingual speech synthesis, use SQuId.
Googleの研究科学者Thibault Sellamです。
以前、私たちは1000言語イニシアチブとUniversal Speech Modelを紹介しました。これらのプロジェクトは、世界中の何十億人ものユーザーに音声および言語技術を提供することを目的としています。この取り組みの一部は、多様な言語を話すユーザー向けにVDTTSやAudioLMなどのプロジェクトをベースにした高品質の音声合成技術を開発することにあります。
 |
新しいモデルを開発した後は、生成された音声が正確で自然であるかどうかを評価する必要があります。コンテンツはタスクに関連し、発音は正確で、トーンは適切で、クラックや信号相関ノイズなどの音響アーティファクトはない必要があります。このような評価は、多言語音声システムの開発において大きなボトルネックとなります。
音声合成モデルの品質を評価する最も一般的な方法は、人間の評価です。テキストから音声(TTS)エンジニアが最新のモデルから数千の発話を生成し、数日後に結果を受け取ります。この評価フェーズには、聴取テストが含まれることが一般的で、何十もの注釈者が一つずつ発話を聴取して、自然な音に聞こえるかどうかを判断します。人間はテキストが自然かどうかを検出することでまだ敵わないことがありますが、このプロセスは実用的ではない場合があります。特に研究プロジェクトの早い段階では、エンジニアがアプローチをテストして再戦略化するために迅速なフィードバックが必要な場合があります。人間の評価は費用がかかり、時間がかかり、対象言語の評価者の可用性によって制限される場合があります。
- スピードは必要なすべてです:GPU意識の最適化による大規模拡散モデルのオンデバイス加速化
- アクセラレータの加速化:科学者がGPUとAIでCERNのHPCを高速化
- Microsoft BingはNVIDIA Tritonを使用して広告配信を高速化
進展を妨げる別の障壁は、異なるプロジェクトや機関が通常、異なる評価、プラットフォーム、およびプロトコルを使用するため、apple-to-applesの比較が不可能であることです。この点で、音声合成技術はテキスト生成に遅れを取っており、研究者らが人間の評価をBLEUや最近ではBLEURTなどの自動評価指標と補完して長年にわたって利用してきたテキスト生成から大きく遅れています。
「SQuId: Measuring Speech Naturalness in Many Languages」でICASSP 2023に発表する予定です。SQuId(Speech Quality Identification)という600Mパラメーターの回帰モデルを紹介します。このモデルは、音声がどの程度自然かを示します。SQuIdは、Googleによって開発された事前学習された音声テキストモデルであるmSLAMをベースにしており、42言語で100万件以上の品質評価をファインチューニングし、65言語でテストされました。SQuIdが多言語の評価において人間の評価を補完するためにどのように使用できるかを示します。これは、今までに行われた最大の公開努力です。
SQuIdによるTTSの評価
SQuIdの主な仮説は、以前に収集された評価に基づいて回帰モデルをトレーニングすることで、TTSモデルの品質を評価するための低コストな方法を提供できるということです。このモデルは、TTS研究者の評価ツールボックスに貴重な追加となり、人間の評価に比べて正確性は劣るものの、ほぼ即時に提供されます。
SQuIdは、発話を入力とし、オプションのロケールタグ(つまり、”Brazilian Portuguese”や”British English”などのローカライズされた言語のバリアント)を指定することができます。SQuIdは、音声波形がどの程度自然に聞こえるかを示す1から5までのスコアを返します。スコアが高いほど、より自然な波形を示します。
内部的には、モデルには3つのコンポーネントが含まれています:(1)エンコーダー、(2)プーリング/回帰層、および(3)完全接続層。最初に、エンコーダーはスペクトログラムを入力として受け取り、1,024サイズの3,200ベクトルを含む小さな2D行列に埋め込みます。各ベクトルは、時間ステップをエンコードします。プーリング/回帰層は、ベクトルを集約し、ロケールタグを追加し、スコアを返す完全接続層に入力します。最後に、アプリケーション固有の事後処理を適用して、スコアを再スケーリングまたは正規化して、自然な評価の範囲である[1、5]の範囲内に収まるようにします。回帰損失で全モデルをエンドツーエンドでトレーニングします。
エンコーダーは、このモデルの最大かつ最も重要な部分です。私たちは、音声(51言語)およびテキスト(101言語)の両方で事前にトレーニングされた600MパラメーターのConformerであるmSLAMを使用しました。
 |
| SQuIdモデル。 |
モデルをトレーニングおよび評価するために、私たちはSQuIdコーパスを作成しました。これは、2,000以上の研究および製品のTTSプロジェクトのために収集された、66言語をカバーする1.9百万の評価済み発話のコレクションです。SQuIdコーパスは、連結型およびニューラルモデルを含むさまざまなシステムをカバーし、運転案内やバーチャルアシスタントなどの幅広い用途に対応しています。手動での検査では、SQuIdが広範囲のTTSエラーにさらされていることがわかりました。例えば、音響的なアーティファクト(クラックやポップなど)、不適切な韻律(英語の疑問文に上昇イントネーションがないなど)、テキストの正規化エラー(「7/7」を「七分の七」と発音する代わりに「7月7日」と発音するなど)、または発音ミス(「tough」を「toe」と発音するなど)が含まれます。
多言語システムをトレーニングする際に生じる一般的な問題は、興味のあるすべての言語についてトレーニングデータが均一に利用できない場合があることです。SQuIdも例外ではありませんでした。以下の図は、各地域のコーパスのサイズを示しています。分布は主に米国英語によって支配されていることがわかります。
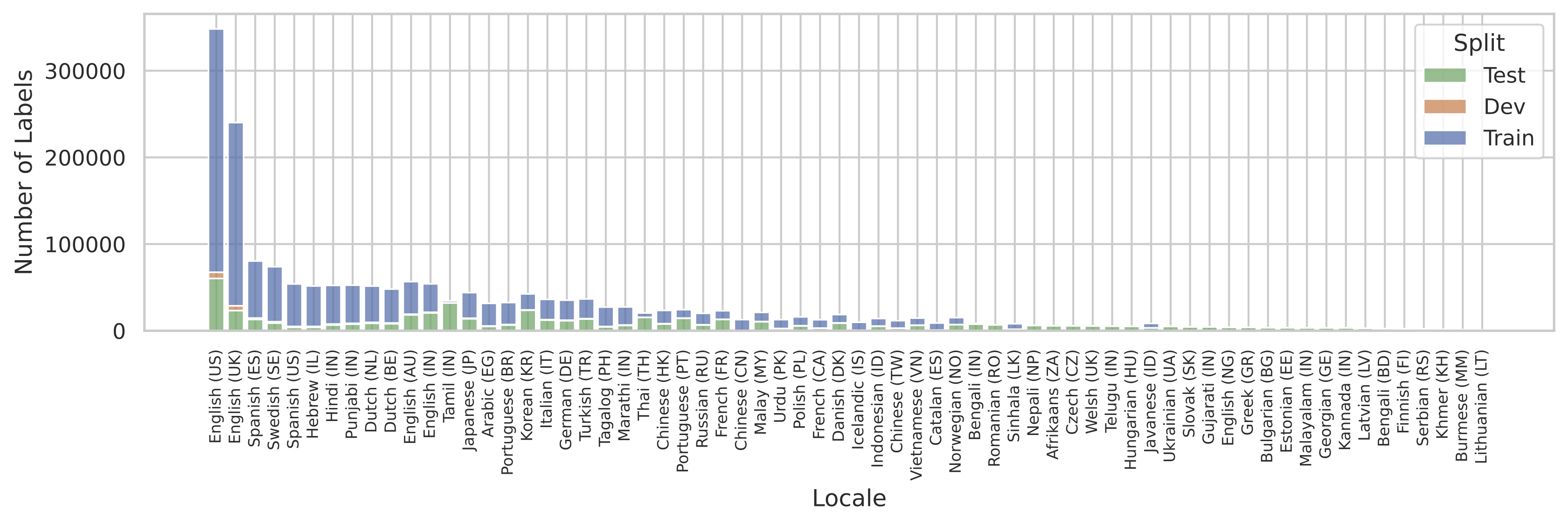 |
| SQuIdデータセット内の地域分布。 |
変動がある場合、すべての言語に対して良好な性能を提供するにはどうすればよいでしょうか?以前の機械翻訳の研究 や、音声文献の過去の研究に触発され、私たちは、各言語ごとに別々のモデルを使用する代わりに、すべての言語に対して1つのモデルをトレーニングすることにしました。仮説は、モデルが十分に大きければ、交差ロケール転送が発生し、他の言語での共同トレーニングの結果として、モデルの各ロケールにおける精度が向上するというものです。私たちの実験は、クロスロケールが性能の強力なドライバーであることを示しています。
実験結果
SQuIdの全体的なパフォーマンスを理解するために、私たちは、カスタムのBig-SSL-MOSモデル(論文で説明されている)と競合するベースラインであるMOS-SSLのインスピレーションを受けた競合モデルを比較しました。Big-SSL-MOSは、w2v-BERTに基づいており、評価時点で最も人気のあるデータセットであるVoiceMOS’22 Challengeデータセットでトレーニングされました。私たちは、モデルのいくつかのバリアントで実験を行い、SQuIdが最大50.0%精度が向上することがわかりました。
 |
| SQuId対最新のベースライン。Kendall Tauを使用して人間の評価との一致を測定し、高い値ほど正確性が向上します。 |
クロスロケール転移の影響を理解するために、私たちは一連の略奪研究を行いました。私たちは、トレーニングセットに導入されたロケールの量を変化させ、SQuIdの精度に与える影響を測定しました。データセットで既に過剰表現されている英語では、ロケールを追加した効果は無視できる程度です。
 |
| 1、8、および42のロケールを使用して、米国英語におけるSQuIdのパフォーマンスを調整したもの。 |
ただし、クロスロケール転移は、ほとんどの他のロケールにとってははるかに効果的です。
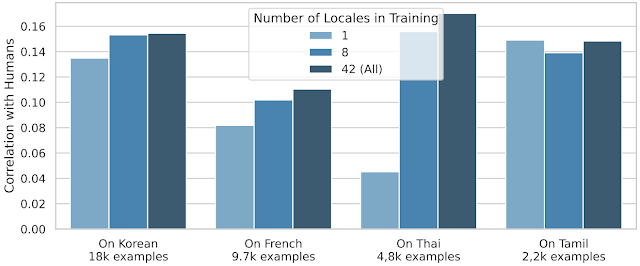 |
| 1、8、および42のロケールを使用して、4つの選択されたロケール(韓国語、フランス語、タイ語、タミル語)におけるSQuIdのパフォーマンスを調整したもの。各ロケールについて、トレーニングセットのサイズも提供しています。 |
転移を限界まで推し進めるために、私たちはトレーニング中に24のロケールを保持し、テストにのみ使用しました。したがって、SQuIdが以前に見たことのない言語の扱い方をどの程度可能かを測定します。以下のプロットは、効果が一様でないとはいえ、クロスロケール転移が機能することを示しています。
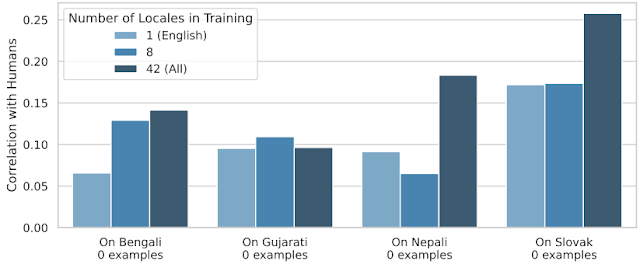 |
| 1、8、および42のロケールを使用して、4つの「ゼロショット」ロケールにおけるSQuIdのパフォーマンス。 |
いつクロスロケールが動作し、どのように動作するのでしょうか?私たちは論文でさらに多くの略奪を提示し、ブラジルポルトガル語でトレーニングすることがヨーロッパポルトガル語の助けとなるなど、言語の類似性が役割を果たすことを示しましたが、それが重要な要素であるとは驚くほど遠いことがわかりました。
結論と今後の課題
SQuIdという600Mパラメータ回帰モデルを紹介し、SQuIdデータセットとクロスロケール学習を活用して音声品質を評価し、自然な音を記述します。私たちは、SQuIdが多言語の評価において人間の評価者を補完できることを示しました。今後の課題には、精度改善、対象言語の範囲の拡大、新しいエラータイプの対処が含まれます。
謝辞
この投稿の著者は現在、Google DeepMindの一員です。論文のすべての著者、Ankur Bapna、Joshua Camp、Diana Mackinnon、Ankur P. Parikh、およびJason Riesaに多くの感謝を表します。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





