このPythonライブラリ「Imitation」は、PyTorchでの模倣と報酬学習アルゴリズムのオープンソース実装を提供します
This Python library Imitation provides open-source implementations of imitation and reward learning algorithms in PyTorch.


明確な報酬関数が定義されたゲームのような領域では、強化学習(RL)は人間のパフォーマンスを上回っています。残念ながら、現実世界の多くのタスクでは報酬関数を手続き的に設計することは困難か不可能です。代わりに、ユーザーフィードバックから報酬関数やポリシーを即座に吸収する必要があります。さらに、ゲームでエージェントが勝つ場合など、報酬関数を定式化できたとしても、RLが効果的に解くためには、得られる目標がよりスパースになる必要がある場合があります。そのため、RLの最先端の結果では、しばしば模倣学習がポリシーの初期化に使用されます。
本記事では、7つの報酬と模倣学習アルゴリズムの優れた、信頼性の高い、モジュラーな実装を提供するライブラリであるimitationについて説明します。重要なことは、彼らのアルゴリズムのインターフェースが一貫しているため、さまざまな方法をトレーニングして比較することが容易になることです。また、PyTorchやStable Baselines3などの最新のバックエンドを使用してimitationを構築しています。それに対して、以前のライブラリは複数のアルゴリズムをサポートしていることが多く、更新されていないことがあり、時代遅れのフレームワークで構築されていました。imitationは実験のベースラインとして多くの重要なアプリケーションを持っています。以前の研究によると、模倣学習アルゴリズムの実装の細かい部分はパフォーマンスに大きな影響を与えることがあります。
imitationは、信頼性のあるベースラインを提供するだけでなく、新しい報酬と模倣学習アルゴリズムの作成プロセスを簡素化することを目指しています。不適切な実験ベースラインを使用すると、誤って肯定的な結果が報告される可能性があります。彼らの技術は慎重にベンチマーク化され、この困難を克服するために以前のソリューションと比較されています。また、彼らは静的型チェックを実施し、コードの98%をカバーするテストを行っています。彼らの実装はモジュラーであり、コードを変更せずに報酬またはポリシーネットワークのアーキテクチャ、RLアルゴリズム、およびオプティマイザを柔軟に変更することができます。
- 「Ph.D.学生や研究者向けの無料オンラインコース10選」
- サムスンのAI研究者が、ニューラルヘアカットを紹介しましたこれは、ビデオや画像から人間の髪の毛のストランドベースのジオメトリを再構築するための新しいAI手法です
- 「サリー大学の研究者が開発した新しいソフトウェアは、AIが実際にどれだけの情報を知っているかを検証することができます」
必要なメソッドをサブクラス化してオーバーライドすることで、アルゴリズムを拡張することができます。また、imitationはロールアウトの収集などのルーチンな活動に取り組むための実用的な方法を提供しており、完全に新しいアルゴリズムの作成を促進します。PyTorchやStable Baselines3などの最先端のフレームワークを使用してモデルが構築されているという利点もあります。これに対して、現在の模倣学習や報酬学習アルゴリズムの多くは数年前に公開され、最新の状態に保たれていません。これは、GAILやAIRLのコードベースなど、元の論文と一緒に提供される参照実装に特に当てはまります。
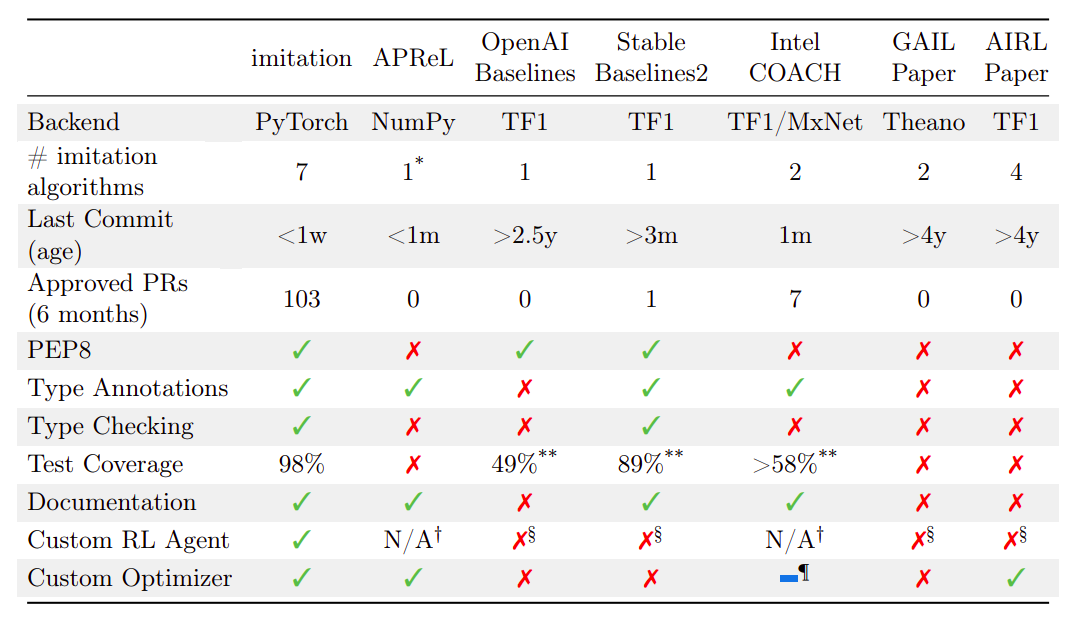
しかし、Stable Baselines2などの人気のあるライブラリももはやアクティブに開発されていません。上記の表では、さまざまな指標で代替ライブラリを比較しています。模倣学習と報酬学習アルゴリズムのすべての実装を含めることはできませんが、この表は彼らの知識に基づいて広く使用されている模倣学習ライブラリをすべて含んでいます。彼らは、模倣学習がすべての指標で他の選択肢と同等または優れていることを発見しています。APRelスコアは高く評価されていますが、低次元の特徴から学習する好み比較アルゴリズムに重点を置いています。これは、モデルとは補完的であり、より広範なアルゴリズムを提供し、実装の複雑さを増す代わりにスケーラビリティを重視しています。PyTorchの実装はGitHubで見つけることができます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 新しいAIの研究は、事前学習済みおよび指示微調整モデルのゼロショットタスクの一般化性能を改善するために、コンテキスト内の指導学習(ICIL)がどのように機能するかを説明しています
- 「スタンフォード大学の新しいAI研究は、言語モデルにおける過信と不確実性の表現の役割を説明します」
- アリババAI研究所が提案する「Composer」は、数十億の(テキスト、画像)ペアで訓練された、巨大な(50億パラメータ)コントロール可能な拡散モデルです
- UCサンディエゴとMeta AIの研究者がMonoNeRFを紹介:カメラエンコーダとデプスエンコーダを通じて、ビデオをカメラ動作とデプスマップに分解するオートエンコーダアーキテクチャ
- 「UCバークレーの研究者たちは、Chain of Hindsight(CoH)という新しい技術を提案しましたこれにより、LLMsがあらゆる形式のフィードバックから学び、モデルのパフォーマンスを向上させることが可能となります」
- UC BerkeleyとDeepmindの研究者は、SuccessVQAという成功検出の再構成を提案しましたこれは、Flamingoなどの事前学習済みVLMに適したものです
- スタンフォード大学の研究者が「局所的に条件付けられた拡散(Locally Conditioned Diffusion):拡散モデルを使用した構成的なテキストから画像への生成手法」を紹介しました