このAI研究論文は、視覚の位置推定とマッピングのための深層学習に関する包括的な調査を提供しています
This AI research paper provides a comprehensive survey on deep learning for visual localization and mapping.


もし私があなたに「今どこにいるの?」または「周りの様子はどうですか?」と尋ねたら、人間の多感覚知覚という独特な能力のおかげで、あなたはすぐに答えることができるでしょう。この能力により、あなたは自分の動きと周囲の環境を知覚し、完全な空間認識を持つことができます。しかし、同じ質問がロボットに対して投げかけられた場合、どのようにアプローチするでしょうか。
問題は、このロボットが地図を持っていない場合、自分がどこにいるかわからないし、周りの様子も知らなければ地図も作成できないということです。要するに、これは「先に来たのは鶏か卵か?」という問題であり、機械学習の世界ではこの文脈で「位置推定と地図作成の問題」と呼ばれています。
「位置推定」とは、ロボットの動きに関連する内部システム情報を取得する能力であり、位置、方向、速度などが含まれます。一方、「地図作成」とは、周囲の環境条件を知覚する能力であり、周囲の形状、視覚的特徴、意味属性などが含まれます。これらの機能は独立して動作することもあり、一方が内部状態に焦点を当て、他方が外部条件に焦点を当てることもあります。また、同時位置推定と地図作成(SLAM)として知られる単一のシステムとして連携することもあります。
- マイクロソフトの研究者は、2段階の介入フレームワークを使用したオープンボキャブラリー責任ある視覚合成(ORES)を提案しています
- 「スピーチの回復を革新する:スタンフォード主導の研究が制約のないコミュニケーションのための高性能な神経プロステーシスを公開」
- チューリッヒ大学の研究者たちは、スイフトという自律型ビジョンベースのドローンを開発しましたこのドローンは、いくつかの公平なヘッドトゥヘッドレースで人間の世界チャンピオンに勝つことができます
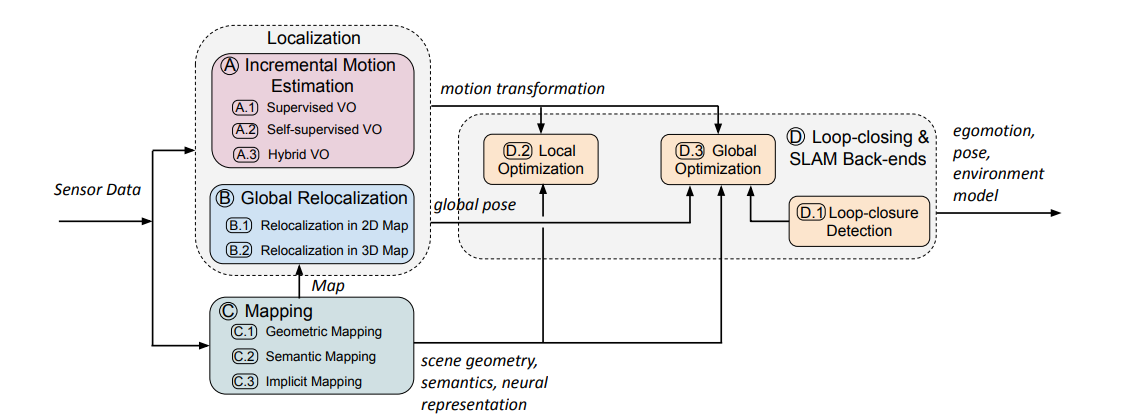
画像ベースの再配置、視覚的オドメトリ、SLAMなどのアルゴリズムには、センサーの測定の不完全さ、動的なシーン、不利な照明条件、現実世界の制約など、実用化を妨げる要素があります。上記の画像は、個々のモジュールが深層学習ベースのSLAMシステムに統合される様子を示しています。この研究では、深層学習ベースのアプローチと従来のアプローチの両方について包括的な調査を行い、次の2つの重要な質問に同時に答えます。
- 深層学習は、視覚的位置推定と地図作成に有望ですか?
研究者たちは、将来の汎用SLAMシステムにおいて、深層学習が独自の方向性を持つと考えています。以下にリストアップされた3つの特性がその理由です。
- 第一に、深層学習は、視覚的SLAMフロントエンドに統合される強力な知覚ツールを提供します。これにより、オドメトリ推定や再配置のための難しい領域で特徴を抽出し、地図作成のための密な深度を提供することができます。
- 第二に、深層学習はロボットに高度な理解力と相互作用能力を与えます。ニューラルネットワークは、マッピングやSLAMシステム内で場面の意味をラベリングするなど、一般的に数学的な方法では説明が難しい抽象概念と人間の理解可能な用語を結びつけることに優れています。
- 最後に、学習手法により、SLAMシステムや個別の位置推定/地図作成アルゴリズムが経験から学び、新しい情報を積極的に活用することができます。
- 深層学習は、視覚的位置推定と地図作成の問題を解決するためにどのように適用されるのでしょうか?
- 深層学習は、SLAMのさまざまな側面をモデリングするための多目的なツールです。たとえば、画像から姿勢を直接推定するエンドツーエンドのニューラルネットワークモデルを作成するために使用することができます。これは、特徴のない領域、動的な照明、モーションブラーなどの厳しい条件を扱う際に特に有益です。
- 深層学習は、SLAMの関連付け問題を解決するために使用されます。画像を地図に接続し、ピクセルに意味を付け、以前の訪問時の関連シーンを認識することで、再配置、意味マッピング、ループクロージャ検出を支援します。
- 深層学習は、興味のあるタスクに関連する特徴を自動的に発見するために活用されます。例えば、幾何学的制約などの先行知識を利用することで、SLAMのための自己学習フレームワークが構築され、入力画像に基づいてパラメータを自動的に更新することができます。
深層学習技術は、意味のあるパターンを抽出するために大規模かつ正確にラベル付けされたデータセットに依存しますが、不慣れな環境に対して一般化することが困難な場合があります。これらのモデルは解釈可能性に欠けており、しばしばブラックボックスとして機能します。また、位置推定と地図作成システムは計算量が多く、高度に並列化可能ですが、モデルの圧縮技術が適用されていない限り、計算負荷が高くなる場合があります。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「NTUシンガポールの研究者たちは、テキストから3D生成のための新しいプラグアンドプレイなリファインメントAIメソッドであるIT3Dを提案しています」
- バージニア工科大学とマイクロソフトの研究者がアイデアの探求と推論の能力を高めるAIアプローチ、アルゴリズムオブソウツを紹介
- 「The Research Agent 大規模なテキストコーパスに基づいた質問に答える課題への取り組み」
- 「ニューヨーク大学の研究者が、人の見かけの年齢を画像内で変える新しい人工知能技術を開発しましたが、その人の独自の識別特徴を維持します」
- Googleの研究者たちは、AIによって生成された画像を透かしを入れたり識別するためのデジタルツールである「𝗦𝘆𝗻𝘁𝗵𝗜𝗗」を紹介しました
- 「GoogleはDeepfakeへの対策として、AIによって生成された画像にウォーターマークを付けます」
- このAI研究は、深層学習システムが継続的な学習環境で使用される際の「可塑性の喪失」という問題に取り組んでいます






