このAI研究は、ポイントクラウドを2D画像、言語、音声、およびビデオと一致させる3Dマルチモダリティモデルである「Point-Bind」を紹介します
This AI research introduces Point-Bind, a 3D multimodal model that aligns point clouds with 2D images, language, audio, and video.


現在の技術的な景観では、3Dビジョンが急速な成長と進化により注目を浴びています。この関心の高まりは、自動運転、強化されたナビゲーションシステム、高度な3Dシーン理解、およびロボティクスといった分野の急成長に大いに貢献しています。3Dポイントクラウドを他のモダリティのデータと組み合わせるためには、3D理解の向上、テキストからの3D生成、および3Dの質問に答えるための試みが数多く行われています。

研究者は、Point-Bindという革命的な3Dマルチモーダルモデルを紹介しました。このモデルは、2D画像、言語、音声、ビデオなどのさまざまなデータソースとのポイントクラウドのシームレスな統合を目指しています。ImageBindの原則に基づいてガイドされたこのモデルは、3Dデータとマルチモダリティの間のギャップを埋める統一された埋め込み空間を構築します。このブレークスルーにより、任意のモダリティに基づいた3D生成、3D埋め込み算術、包括的な3Dオープンワールド理解など、多くのエキサイティングなアプリケーションが可能になります。
上記の画像では、Point-Bindの全体的なパイプラインが表示されています。研究者はまず、対照的な学習のために3D-画像-音声-テキストデータのペアを収集し、ImageBindによって3Dモダリティを他のモダリティに調整します。共通の埋め込み空間を持つことで、Point-Bindは3Dクロスモーダル検索、任意のモダリティに基づいた3D生成、3Dゼロショット理解、および3D大規模言語モデルの開発(Point-LLM)に利用することができます。
- 「MITキャンパスでのAIパイロットプログラムは、エネルギー使用量と排出物を削減することを目指しています」
- 「このAI研究は、深層学習と進化アルゴリズムを用いて、シリコンMach-Zehnderモジュレータの設計を革新します」
- 「UCLAの研究者たちは、広帯域の回折光学ニューラルネットワークに基づいて設計されたマルチスペクトルQPIシステムを紹介する」
この研究のPoint-Bindの主な貢献は以下の通りです:
- ImageBindによる3Dの整列:共通の埋め込み空間内で、Point-Bindはまず3Dポイントクラウドを2D画像、ビデオ、言語、音声などのマルチモダリティと整列させます。
- 任意のモダリティに基づいた3D生成:既存のテキストから3Dへの生成モデルに基づいて、Point-Bindはテキスト/画像/音声/ポイントからメッシュの生成など、任意のモダリティに基づいた3D形状合成を可能にします。
- 3D埋め込み空間の算術:Point-Bindの3D特徴は、他のモダリティと組み合わせてその意味を取り込むために追加することができます。これにより、構成されたクロスモーダル検索が実現されます。
- 3Dゼロショット理解:Point-Bindは、3Dゼロショット分類の最先端の性能を達成します。また、テキストに加えて音声に基づいた3Dオープンワールド理解もサポートします。
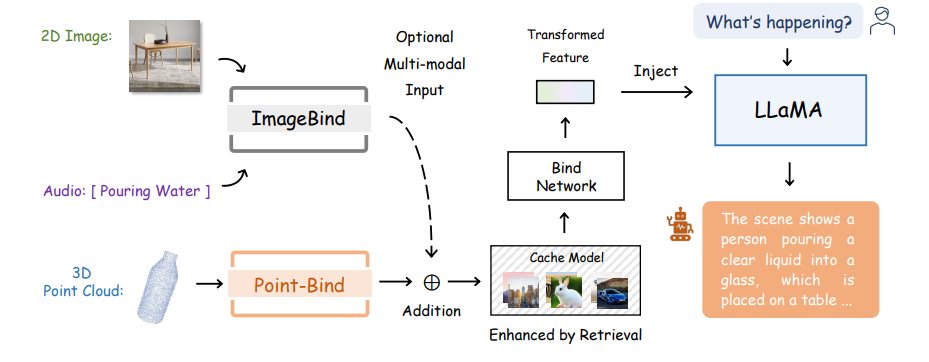
研究者はPoint-Bindを活用して、3D質問応答やマルチモーダルな推論を実現するためにLLaMAを最適化した3D大規模言語モデル(Point-LLM)を開発しています。Point-LLMの全体的なパイプラインは、上記の画像で確認することができます。
Point LLMの主な貢献は以下の通りです:
- 3D質問応答のためのPoint-LLM: PointBindを使用して、英語と中国語の両方をサポートする、3Dポイントクラウド条件で指示に応答する初の3D LLM、Point-LLMを紹介します。
- データとパラメータの効率: 3Dの指示データなしで、公共のビジョン言語データのみを調整に使用し、リソースを節約するためにパラメータ効率の高いファインチューニング技術を採用しています。
- 3Dおよびマルチモーダル推論: 共有埋め込み空間を介して、Point-LLMは3Dとマルチモーダルの入力の組み合わせを推論することにより、記述的な応答を生成することができます。例えば、画像/音声とポイントクラウドなどです。
将来の研究は、室内や屋外のシーンなど、より多様な3Dデータとマルチモダリティを統合することに焦点を当て、より広範な応用シナリオを可能にする予定です。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 『キャタリスト研究の変革:テキスト入力を使用したエネルギー予測のために設計された Transformer ベースの AI モデル、CatBERTaに出会ってください』
- 「産業界が音声AIを活用して消費者の期待に応えている方法」
- 「Google Researchが探求:AIのフィードバックは、大規模な言語モデルの効果的な強化学習において人間の入力を置き換えることができるのか?」
- UCLAとGoogleの研究者が、AVISという画像質問応答の自律情報検索のための画期的なAIフレームワークを提案しています
- 「強力な遺産:研究者の母が核融合への情熱をかきたてる」
- 「マイクロソフトリサーチがAIコンパイラを1つではなく、2つでもなく、4つも新たに紹介」
- この人工知能(AI)の研究では、SAMを医療用2D画像に適用するための最も包括的な研究である、SAM-Med2Dを提案しています






