このAI研究では、全身ポーズ推定のための新しい2段階ポーズ蒸留を紹介しています
This AI research introduces a new two-stage pose distillation for whole-body pose estimation.


多くの人間中心の知覚、理解、創造のタスクは、3D全身メッシュ復元、人間とオブジェクトの相互作用、姿勢に基づいた人間の画像と動作生成を含む、全身姿勢推定に依存しています。また、OpenPoseやMediaPipeなどのユーザーフレンドリーなアルゴリズムを使用して、仮想コンテンツの開発やVR/ARのための人間の姿勢の記録が大幅に増加しています。しかし、これらのツールは便利ですが、その性能はまだ改善が必要であり、その可能性を制限しています。したがって、ユーザー主導のコンテンツ制作の可能性を実現するために、人間の姿勢評価技術のさらなる開発が不可欠です。
比較的に、全身姿勢推定は、以下の要因により、体のみのキーポイント検出と比較して困難を伴います。
- 細かいキーポイントの位置特定のための人間の体の階層構造。
- 手と顔の小さな解像度。
- 画像内の複数の人物に複雑な体の部位が一致すること、特に遮蔽や難しい手のポーズの場合。
- 特に全身画像の多様な手のポーズと頭のポーズに対するデータの制約。
さらに、展開する前にモデルを薄くする必要があります。蒸留、トリミング、量子化が基本的な圧縮技術を構成します。
- このAI研究は、質問応答の実行能力において、指示に従うモデルの正確さと忠実さを評価します
- ソルボンヌ大学の研究者は、画像、ビデオ、音声、言語のタスクに対する統合AIモデル「UnIVAL」を紹介しました
- 「医療分野における生成型AI」
知識蒸留(KD)は、推論プロセスに不要なコストを追加せずに、コンパクトなモデルの効果を向上させることができます。この方法は、分類、検出、セグメンテーションなどのさまざまなタスクで広範に使用され、生徒がより経験豊富な教師から知識を取得することを可能にします。本研究では、全身姿勢推定のためのKDの調査を通じて、パフォーマンスと効率の良いリアルタイムのポーズ推定器のセットが開発されました。清華深圳国際研究院と国際デジタル経済アカデミーの研究者は、DWPoseという革新的な二段階ポーズ蒸留アーキテクチャを提案しています。図1に示すように、このアーキテクチャは最先端のパフォーマンスを提供します。彼らは、基本モデルとしてCOCO-WholeBodyで訓練された最新のポーズ推定器であるRTMPoseを使用します。
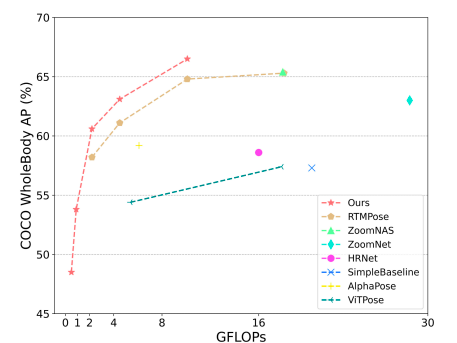
彼らは、第一段階の蒸留では、教師(例:RTMPose-x)の中間層と最終的なロジットをネイティブに使用して、生徒モデル(例:RTMPose-l)を誘導します。前のポーズトレーニングでは、キーポイントはその可視性によって区別され、監視には可視のキーポイントのみが使用されます。一方、彼らは教師のすべての出力、つまり可視および不可視のキーポイントを含む最終的なロジットを使用します。これにより、正確で綿密な値が生徒の学習プロセスに役立ちます。また、効果を高めるために、トレーニングセッションの進行に従ってデバイスの重みを徐々に下げる重み減衰アプローチも使用しています。第二段階の蒸留では、ヘッドを増強するためにヘッドに対する自己KDが提案されています。ヘッドがより優れていると、より正確な位置特定ができるためです。
彼らは、2つの同一のモデルを構築し、一方をアップデートする生徒、もう一方をインストラクターとして選択します。生徒のヘッドのみがロジットに基づいた蒸留によって更新され、残りの体は凍結されます。特に、このプラグアンドプレイの戦略は、密な予測ヘッドと共に動作し、蒸留を使用するかしないかにかかわらず、トレーニング時間を20%短縮して生徒がより良い結果を得ることができます。さまざまな人体部位の異なるサイズを対象とするデータのボリュームとバラエティは、モデルのパフォーマンスに影響を与えます。従って、包括的な注釈付きキーポイントの必要性から、既存の推定器は、細かい指や顔の特徴点を正確に特定するのに役立ちます。
そのため、彼らはさらに、さまざまな実生活の設定で撮影された多数の顔と手のキーポイントを含む追加のUBodyデータセットを組み込んでデータ効果を調査しています。したがって、彼らの貢献について次のことが言えます:
• 全身データの制約を克服するために、彼らは多様で表現豊かな手のジェスチャーや表情に特に焦点を当てた包括的なトレーニングデータを探索し、実生活のアプリケーションに適用可能にしました。
• 効率的かつ正確な全身姿勢推定を追求するために、2段階の姿勢知識蒸留法を導入しています。
• 提案された蒸留およびデータのテクニックは、最新のRTMPoseを基本モデルとして使用し、RTMPose-lのAPを64.8%から66.5%に大幅に向上させることができます。さらに、彼らはDWPoseの作業生成における強力な効果と効率性を確認しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「スタンフォード研究者は、直接の監督なしでメタ強化学習エージェントにおける単純な言語スキルの出現を探求する:カスタマイズされたマルチタスク環境におけるブレイクスルーを解明する」
- 『CMUからの新しいAI研究は、適切な言語モデルに対して物議を醸す行動を生成させるための、簡単で効果的な攻撃手法を提案しています』
- 「拡散モデルの助けを借りて、画像間の補間を組み込むためのAI研究」についてのAI研究
- 自動化された欺瞞検出:東京大学の研究者が機械学習を通じて表情と脈拍を利用して欺瞞を暴く
- MITの研究者が新しいAIツール「PhotoGuard」を導入し、不正な画像の操作を防止すると発表しました
- 「AIIMSデリーが医療のためのロボット技術、AI、およびドローンの研究を開始」
- 「MITのインドの学生が声を必要としない会話デバイスを開発」






