ニューラルネットワークの簡単な歴史
「ニューラルネットワークの歴史をわかりやすく解説!」
ニューラルネットワークは、人工知能の基礎となる要素であり、情報処理の方法を革新し、技術の未来を垣間見るものです。これらの複雑な計算システムは、人間の脳の複雑さに触発されたもので、画像認識や自然言語理解、自動運転、医療診断などのタスクにおいて重要な役割を果たしています。ニューラルネットワークの歴史的な進化を探求することで、彼らがどのように進化し、AIの現代の景観を形作ったのかを明らかにしていきましょう。
それがすべて始まった方法
- 『ScaleCrafterを知る:事前学習済みの拡散モデルによる超高解像度画像合成の解放』
- 大規模言語モデルにおける推論力の向上:正確かつ転送可能なルールベース学習のための仮説から理論へ(HtT)フレームワークをご覧ください
- 「LlamaIndex vs LangChain 比較分析」
ニューラルネットワークは、ディープラーニングの基礎要素であり、概念的なルーツは人間の脳内の複雑な生物学的ネットワークにあります。この驚くべき概念は、生物学的なニューロンと計算ネットワークとの類似性に基づいています。
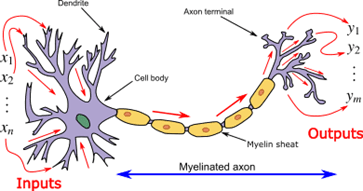
この比喩は、脳が約1000億個のニューロンから成り立っていることに焦点を当てています。各ニューロンは他のニューロンと約7000のシナプス接続を維持し、人間の認知プロセスや意思決定の基礎となる複雑な神経ネットワークを形成しています。
個々の生物学的ニューロンは、単純な電化学プロセスを通じて動作します。それは樹状突起を介して他のニューロンから信号を受け取ります。これらの入力信号があるレベル(あらかじめ決められた閾値)に達すると、ニューロンはスイッチがオンになり、その軸索沿いに電気化学信号を送ります。これにより、軸索端子に接続されたニューロンに影響を与えます。ここで重要なポイントは、ニューロンの応答がバイナリスイッチのようなものであることです。つまり、発火(アクティベート)するか、静かなままにするか、中間状態はありません。
印象的な人工ニューラルネットワークでも、人間の脳の驚くべき複雑さや深い複雑さには遠く及ばしています。それでもなお、これらのネットワークは、従来のコンピュータにとって困難であるが人間の認識には直感的に理解できる問題に対して、重要な能力を発揮しています。その例として、画像認識や過去のデータに基づく予測分析などがあります。
これで、生物学的ニューロンの動作原理とそれが人工ニューラルネットワークへのインスピレーションに如何に関わるかの基礎原則を探求してきました。次に、人工知能の風景を形作ったニューラルネットワークの進化をたどってみましょう。
FFNN – 順送り型ニューラルネットワーク
順送り型ニューラルネットワーク(FFNN)は、多層パーセプトロンとも呼ばれる基本的なタイプのニューラルネットワークであり、情報の流れ、相互接続の層、パラメータの最適化の原則に深く根ざしています。
FFNNのコアとなる特徴は、情報の一方向への旅であることです。まず、データが初めに摂取される入力層にはn個のニューロンがあります。この層はネットワークのエントリーポイントとして機能し、処理する必要がある入力特徴量の受信器として機能します。そして、データはネットワークの隠れ層を通って変形の旅を始めます。
FFNNの重要な側面の一つは、接続された構造です。つまり、層内の各ニューロンがその層内のすべてのニューロンと複雑に接続されているということです。この相互接続性により、ネットワークは計算を行い、データ内の関係を捉えることができます。これは、すべてのノードが情報処理において役割を果たす通信ネットワークのようです。
データが隠れ層を通過すると、一連の計算が行われます。隠れ層の各ニューロンは、前の層のすべてのニューロンから入力を受け取り、これらの入力に加重和を適用し、バイアス項を加え、結果を活性化関数(一般的にReLU、Sigmoid、またはtanH)を通じて出力します。これらの数学的な操作により、ネットワークは入力から関連するパターンを抽出し、データ内の複雑な非線形関係を捉えることができます。これがFFNNが他の浅い機械学習モデルと比較して真に優れている点です。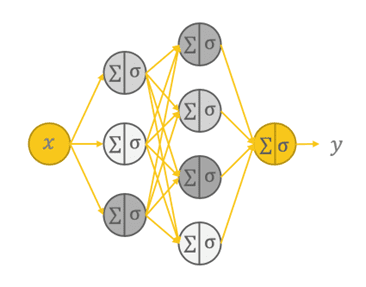
しかし、その能力にはまだまだ止まりません。FFNNの真の力は、適応能力にあります。トレーニング中にネットワークは重みを調整し、予測と実際の目標値との差を最小化します。この反復プロセスは、勾配降下法などの最適化アルゴリズムに基づくことがよくあり、バックプロパゲーションと呼ばれます。バックプロパゲーションにより、FFNNは実際にデータから学習し、予測や分類の正確性を向上させることができます。
強力で多様性に富んでいる一方、FFNNはいくつかの重要な制限を持っています。たとえば、データ内の連続性や時間的/構文的な依存関係を捉えることができず、言語処理や時系列分析のタスクにとって重要な要素となります。これらの制限を克服する必要性が新しいタイプのニューラルネットワークアーキテクチャの進化を促しました。この移行が進展し、Recurrent Neural Networks(RNN)が登場し、シーケンシャルデータをよりうまく処理するためのフィードバックループのコンセプトを導入しました。
RNNとLSTM – Recurrent Neural NetworkとLong Short-Term Memory
RNNは、FFNNといくつかの類似点を共有しています。それらもまた、予測や分類をするためのデータを処理する、相互に接続されたノードの層で構成されています。しかし、彼らの最大の違いは、シーケンシャルデータを扱い、時間的な依存関係を捉える能力にあります。
FFNNでは、情報は入力層から出力層まで単一の単方向のパスで流れます。これは、データの順序があまり重要でないタスクに適しています。しかし、時系列データ、言語、音声などのシーケンスを扱う場合、コンテキストを維持し、データの順序を理解することが重要です。ここでRNNが優れているのです。
RNNはフィードバックループのコンセプトを導入します。これは一種の「メモリ」として機能し、ネットワークが過去の入力に関する情報をキャプチャし、現在の入力と出力に影響を与えることができるようにします。従来のニューラルネットワークでは、入力と出力は互いに独立していると仮定されていますが、再帰的なニューラルネットワークの出力はシーケンス内の前の要素に依存しています。この再帰接続機構により、RNNは「過去の情報を覚える」ことによってシーケンスを処理するのに特に適しています。
再帰ネットワークのもう一つの特徴は、ネットワークの各層で同じ重みパラメータを共有し、これらの重みはシーケンスデータ専用のバックプロパゲーションスルータイム(BPTT)アルゴリズムを利用して調整されることです。
しかし、伝統的なRNNには制限があります。理論上は長期的な依存関係を捉えることができるはずですが、実際にはそれが効果的に行われず、勾配消失問題が起こることさえあります。勾配消失問題は、多くの時間ステップにわたる情報の学習と記憶の能力を阻害します。
ここでLong Short-Term Memory(LSTM)ユニットが登場します。これらは、Forgetゲート、Inputゲート、Outputゲートの3つのゲートを構造に組み込むことで、これらの問題を処理するように特に設計されています。
- Forgetゲート:このゲートは、どのタイムステップの情報を破棄または忘れるかを決定します。セルの状態と現在の入力を調べ、現在の予測には関係のない情報を判断します。
- Inputゲート:このゲートは、情報をセルの状態に組み込む責任があります。入力と前のセルの状態の両方を考慮して、新しい情報を追加して状態を向上させるべき情報を決定します。
- Outputゲート:このゲートは、LSTMユニットが生成する出力を結論づけます。現在の入力と更新されたセルの状態の両方を考慮して、予測に使用される出力またはタイムステップに渡される出力を生成します。
要約すると、RNN、特にLSTMユニットは、自然言語処理、音声認識、時系列予測などのタスクにとって重要な能力であるメモリの維持と時間的な依存関係の捉えを行うシーケンシャルデータに最適化されています。
RNNがシーケンシャルな依存関係を捉える中で、進化は異なるデータタイプと構造にわたってニューラルネットワークの応用範囲を反映し、Convolutional Neural Networks(CNN)に進展しています。RNNとは異なり、CNNは構造化されたグリッド状のデータから空間的な特徴抽出に優れており、画像とパターン認識のタスクに理想的です。
CNN – Convolutional Neural Network
CNNは、特に2Dイメージや3Dビデオデータなどの画像データを処理するのに非常に適したニューラルネットワークの一種です。そのアーキテクチャは、少なくとも1つの畳み込み層を持つ多層のフィードフォワードニューラルネットワークに基づいています。
何がCNNを際立たせるかは、ネットワークの接続性と特徴の抽出方法です。これにより、データ内の関連するパターンを自動的に特定することができます。次の層のすべてのニューロンが前の層のすべてのニューロンと接続する従来のFFNNとは異なり、CNNはカーネルまたはフィルタとしてのスライディングウィンドウを使用します。このスライディングウィンドウは、入力データ全体に対してスキャンされ、画像内のオブジェクトの識別やビデオ内の動きの追跡など、空間関係が重要なタスクに非常に強力です。カーネルがイメージ上を移動すると、カーネルとピクセル値との間で畳み込み演算(厳密には相互相関と呼ばれる)が行われ、通常はReLUと呼ばれる非線形活性化関数が適用されます。これにより、特徴が画像パッチ内にある場合は高い値が生成され、ない場合は小さい値が生成されます。
カーネルとともに、ストライド(つまり、カーネルをスライドさせるピクセル数)やダイレーション率(つまり、各カーネルセルの間のスペース)などのハイパーパラメータの追加と微調整により、ネットワークは特定の特徴に焦点を当て、一度に全入力を考慮せずに特定の領域のパターンと詳細を認識することができます。
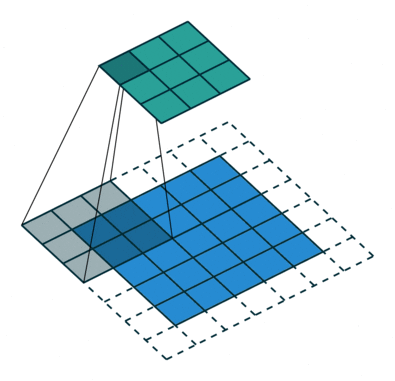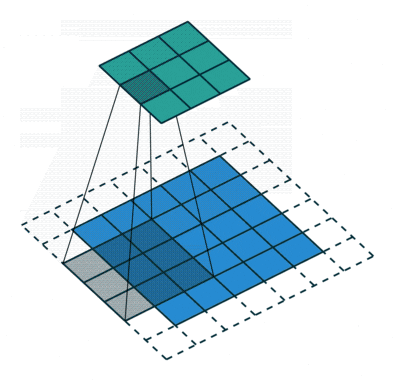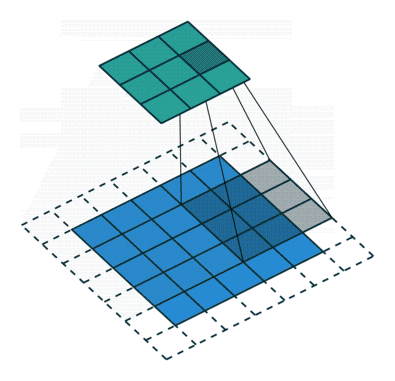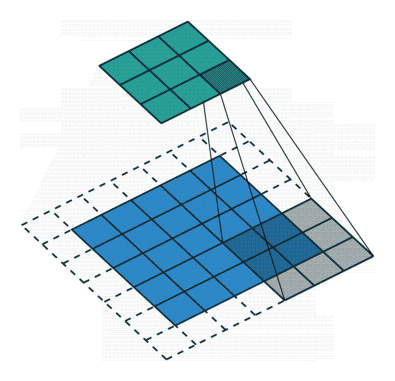 ストライド長が2の畳み込み演算(Sumit SahaによるGIF)。
ストライド長が2の畳み込み演算(Sumit SahaによるGIF)。
一部のカーネルはエッジやコーナーを検出することに特化している場合もありますが、他のカーネルは猫や犬、道路標識などのより複雑なオブジェクトを認識するように調整されている場合もあります。複数の畳み込み層とプーリング層を重ねることで、CNNは入力の階層的な表現を構築し、低レベルから高レベルまで特徴を抽象化していきます。まるで私たちの脳が視覚情報を処理するように。
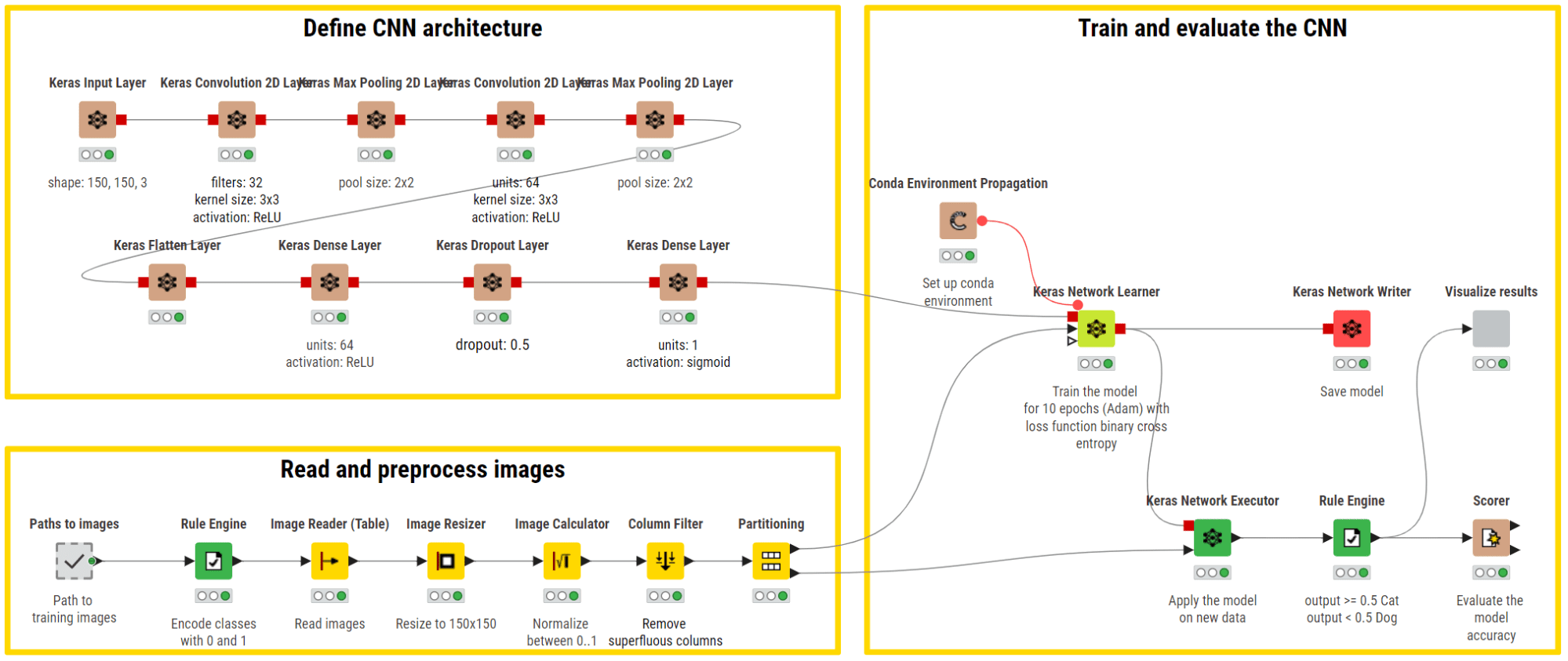 バイナリイメージ分類(猫対犬)のためのCNNのKNIMEワークフローの例。上部の枝は、画像からの自動的な特徴抽出のための畳み込み層と最大プーリング層の連続を使用してネットワークアーキテクチャを定義します。フラット化層は、抽出された特徴をFFNNの一次元入力として準備し、バイナリ分類を実行します。
バイナリイメージ分類(猫対犬)のためのCNNのKNIMEワークフローの例。上部の枝は、画像からの自動的な特徴抽出のための畳み込み層と最大プーリング層の連続を使用してネットワークアーキテクチャを定義します。フラット化層は、抽出された特徴をFFNNの一次元入力として準備し、バイナリ分類を実行します。
CNNは特徴抽出に優れており、コンピュータビジョンのタスクを革新していますが、彼らは受動的な観察者として機能し、新しいデータやコンテンツを生成することは設計されていません。これはネットワークそのものの固有の制限ではありませんが、強力なエンジンでも燃料がないと速い車は無駄です。実際、本物で意味のある画像やビデオデータは、収集が困難で高価であり、著作権やデータプライバシーの制限に直面する傾向があります。この制約から、CNNを基盤とした画像分類から創造的な合成への新しいパラダイムが開発されました:敵対的生成ネットワーク(GAN)。
GAN – 敵対的生成ネットワーク
GANは、主ながら唯一の目的ではない、与えられた実データセットに非常に似た合成データを生成する特定のニューラルネットワークの一種です。GANの発明的なアーキテクチャデザインは、2つのコアモデルから成り立っています:
- ジェネレータモデル:このニューラルネットワークデュエットの最初の役割は、ジェネレータモデルです。このコンポーネントの使命は、ランダムノイズや入力ベクトルを与えられた場合、できるだけ実データに似た人工のサンプルを作成することです。これは、マスターピースと区別がつかない絵画を制作しようとする偽造者のようなものです。
- ディスクリミネータモデル:対抗役としての役割を果たすのは、ディスクリミネータモデルです。このモデルの役割は、ジェネレータによって生成されたサンプルとオリジナルデータセットからの本物のサンプルとを区別することです。これは、本物の美術作品の中から贋作を見つけ出そうとする美術鑑定士のようなものです。
ここで魔法が起こります:GANは継続的な対立するダンスに参加します。ジェネレータは自分の芸術性を向上させることを目指し、継続的に作品を調整してより説得力を持たせます。一方、ディスクリミネータはより鋭い探偵となり、本物と偽物を見分ける能力を磨きます。
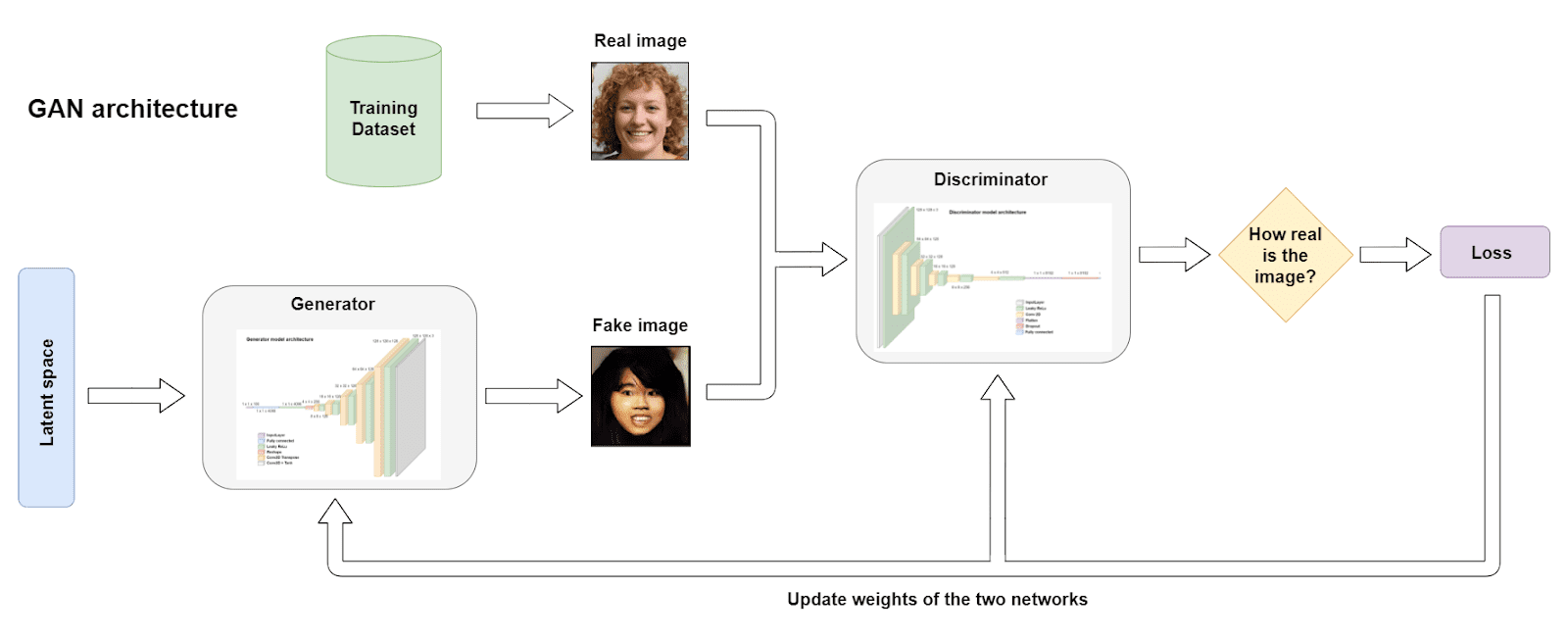 GANアーキテクチャ(著者による画像)。
GANアーキテクチャ(著者による画像)。
トレーニングが進むにつれて、ジェネレータとディスクリミネータのこのダイナミックな相互作用により、魅力的な結果が生まれます。ジェネレータは、ディスクリミネータでも真偽を見破ることができないほどリアルなサンプルを生成しようとします。この競争が、両コンポーネントが能力を継続的に改善する要因となります。
その結果?画像、音楽、テキストなど、信憑性のあるデータを生成することに驚くほど熟練しているジェネレーターです。この能力は、画像合成、データ拡張、画像から画像への変換、画像編集など、さまざまな分野で優れた応用が生まれました。
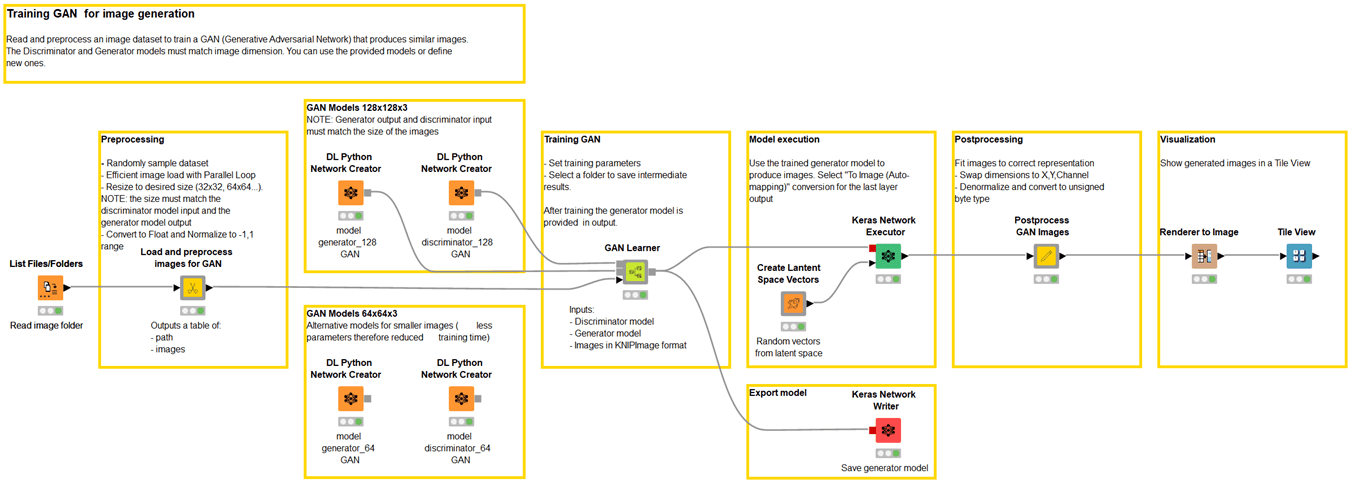 シンセティックな画像(つまり、動物、人間の顔、シンプソンのキャラクターなど)を生成するための GAN の KNIME ワークフローの例。
シンセティックな画像(つまり、動物、人間の顔、シンプソンのキャラクターなど)を生成するための GAN の KNIME ワークフローの例。
GAN は、生成器と判別器を対立させることで、リアルな画像や動画の生成を先駆けました。画像からシーケンシャルデータへのクリエイティビティと高度な操作の必要性を拡張し、より洗練された自然言語理解、機械翻訳、テキスト生成のモデルが導入されました。これにより、長距離の言語依存性や意味的な文脈を効果的に捉えることができると同時に、最新の AI ベースのアプリケーションの確固たる基盤となりました。
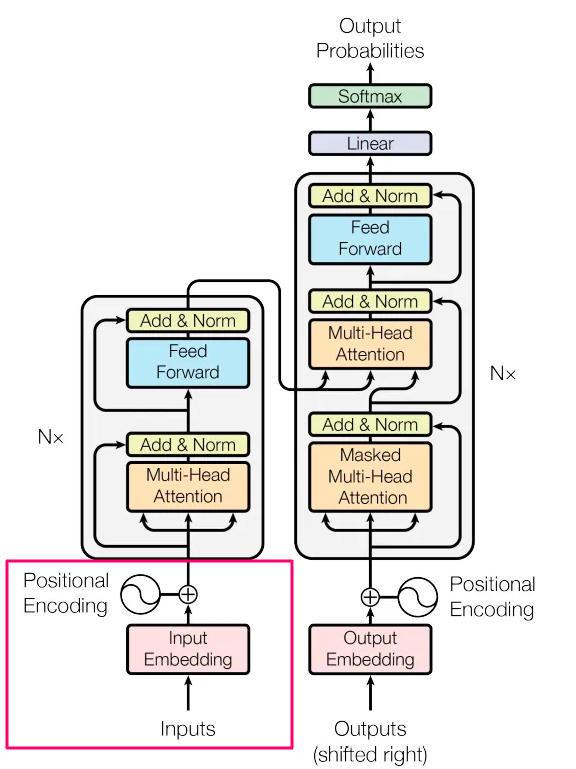
Transformers
2017 年に開発された Transformers は、伝統的な再帰レイヤーを置き換えるユニークな機能を持っています。それは、単語間の複雑な関係をモデル化するセルフアテンションメカニズムで、単語の位置に関係なくドキュメント内のすべての単語との関係をモデル化することができます。これにより、Transformers は自然言語の長距離の依存関係の課題に優れた対処能力を持っています。Transformer のアーキテクチャは、主に2つのメインのブロックで構成されています。
- エンコーダー。 ここでは、入力シーケンスはベクトルに埋め込まれ、その後セルフアテンションメカニズムに露出されます。セルフアテンションメカニズムは、各トークンについての注意スコアを計算し、他のトークンとの関連性を決定します。これらのスコアは重み付き和を作成するために使用され、それぞれのトークンの文脈認識表現を生成するために FFNN に供給されます。複数のエンコーダーレイヤーがこのプロセスを繰り返し、モデルの階層的および文脈情報をキャプチャする能力を向上させます。
- デコーダー。 このブロックは、出力シーケンスを生成する責任を持ち、エンコーダーの出力と自身の過去のトークンに焦点を当てるための類似のプロセスを進めます。このようにして、入力コンテキストと以前に生成された出力の両方を考慮に入れることで、正確な生成を保証します。
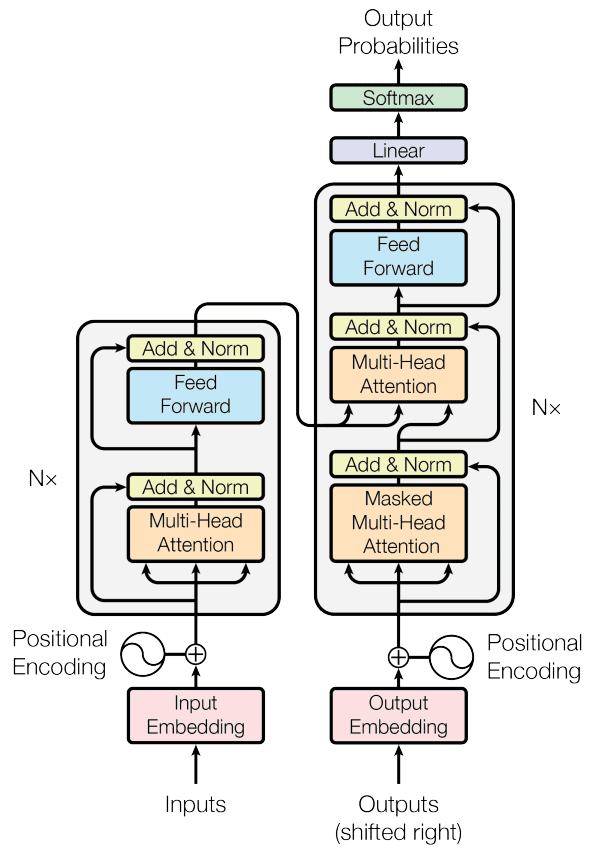 Transformer モデルのアーキテクチャ(Vaswani et al., 2017、画像)。
Transformer モデルのアーキテクチャ(Vaswani et al., 2017、画像)。
次の文を考えてみましょう。「私は川を渡った後に銀行に到着しました」。ここでの「銀行」という言葉は、金融機関または川のほとりの意味を持つことがあります。ここでトランスフォーマーが輝くのです。彼らは「銀行」と他のすべての言葉を比較し、注意スコアを割り当てることで、「銀行」の意味をはっきりさせるために素早く「川」に焦点を当てることができます。これらのスコアにより、次の「銀行」の表現に対する各単語の影響が決定されます。この場合、「川」はより高いスコアを得て、意図された意味を明確にします。
これにより、Transformers は数百万ものトレーニング可能なパラメーターを必要とし、大量のテキストデータと高度なトレーニング戦略が必要です。Transformers で使用されるトレーニングアプローチの1つはマスク言語モデル(MLM)です。トレーニング中、入力シーケンス内の特定のトークンがランダムにマスクされ、モデルの目標はこれらのマスクされたトークンを正確に予測することです。この戦略により、モデルは正確な予測をするために周囲の単語に依存する必要があるため、単語間の文脈的な関係を把握することが求められます。この手法は、BERT モデルによって普及し、さまざまな NLP タスクで最先端の結果を達成するのに重要な役割を果たしました。
Transformers における MLM の代替手法は、自己回帰モデリングです。この方法では、モデルは前に生成された単語を条件としながら、一度に1つの単語を生成するようにトレーニングされます。GPT(Generative Pre-trained Transformer)のような自己回帰モデルは、自由なテキスト生成、質問応答、テキスト補完など、次に最も適切な単語を予測することが目標とされるタスクで優れた結果を出しています。
さらに、大量のテキストリソースの必要性を補うために、Transformers は並列化に優れており、従来の順次アプローチ(RNN や LSTM ユニットなど)よりもトレーニング中にデータを高速に処理することができます。この効率的な計算により、トレーニング時間が短縮され、自然言語処理、機械翻訳などの画期的なアプリケーションが実現されました。
Google によって2018年に開発され、大きな影響を与えた重要な Transformer モデルは BERT(Bidirectional Encoder Representations from Transformers)です。BERT は MLM トレーニングに基づき、単語のマスクされたトークンを予測する際に左右の文脈の両方を考慮するという双方向のコンテキストの概念を導入しました。この双方向のアプローチは、単語の意味や文脈のニュアンスの理解を大幅に向上させ、自然言語理解やさまざまな NLP タスクの新しいベンチマークを確立しました。
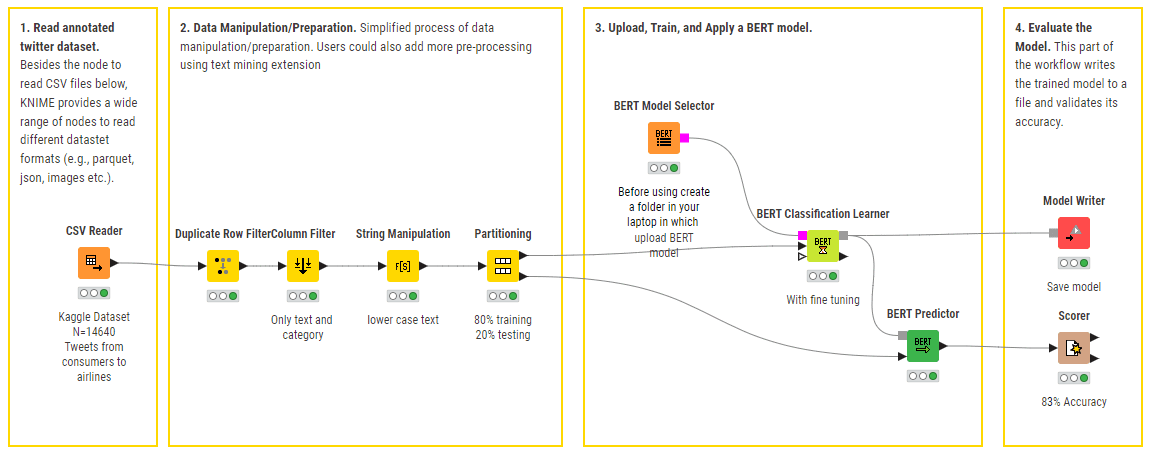 BERTによる多クラス感情予測(ポジティブ、ネガティブ、中立)のKNIMEワークフローの例。最小の前処理が行われ、事前学習済みBERTモデルが微調整されます。
BERTによる多クラス感情予測(ポジティブ、ネガティブ、中立)のKNIMEワークフローの例。最小の前処理が行われ、事前学習済みBERTモデルが微調整されます。
強力なセルフアテンションメカニズムを導入したTransformersの後に、アプリケーションの多様性と複雑な自然言語タスク(文書要約、テキスト編集、コード生成など)の実行が求められたため、大規模言語モデルの開発が必要とされました。これらのモデルは、数十億のパラメータを持つ深層ニューラルネットワークを使用し、このようなタスクで優れたパフォーマンスを発揮し、データ分析業界の変化する要求に対応します。
LLM – 大規模言語モデル
大規模言語モデル(LLM)は、最近注目を集めている革新的なマルチパーパスでマルチモーダル(画像、音声、テキストの入力を受け付ける)深層ニューラルネットワークのカテゴリです。形容詞「大規模」は、数十億の訓練可能なパラメータを含む彼らの巨大なサイズからきています。最もよく知られている例には、OpenAIのChatGPT、GoogleのBard、MetaのLLaMaなどがあります。
LLMの特徴は、人間のようなテキストの処理と生成能力です。それらはテキストの補完、翻訳、質問応答、コンテンツ要約など、自然言語の理解と生成のタスクで優れたパフォーマンスを発揮します。彼らの成功の鍵は、巨大なテキストコーパスでの広範なトレーニングにあり、言語の微妙なニュアンス、文脈、意味の豊かな理解を捉えることができます。
これらのモデルは、与えられた文脈内で異なる単語やフレーズの重要性を考慮するための複数レイヤのセルフアテンションメカニズムを使用しています。この動的な適応性により、さまざまなタイプの入力の処理、複雑な言語構造の理解、人間の提示に基づいた出力の生成に優れています。
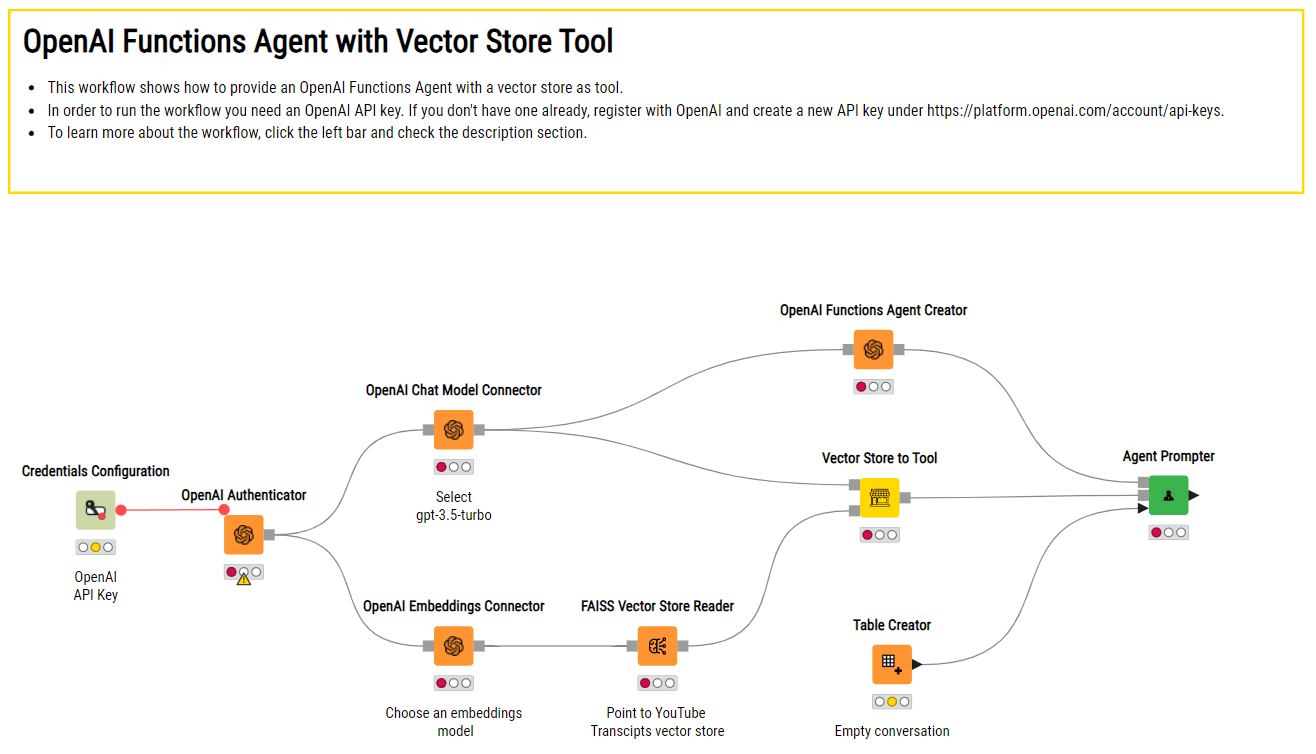 カスタムドキュメントを使用したOpenAIのChatGPTとベクトルストアに依存するAIアシスタントの作成のKNIMEワークフローの例。
カスタムドキュメントを使用したOpenAIのChatGPTとベクトルストアに依存するAIアシスタントの作成のKNIMEワークフローの例。
LLMは、医療、金融、エンターテイメント、カスタマーサービスなどさまざまな業界での多くの応用の道を開いています。それらは創造的な文章やストーリーテリングの新しいフロンティアさえも引き起こしました。
ただし、その巨大なサイズ、リソース集約型のトレーニングプロセス、生成されたコンテンツの潜在的な著作権侵害に関しては、倫理的な使用、環境への影響、アクセシビリティの懸念も引き起こしています。最後に、LLMはますます改良されていますが、「幻覚」を引き起こす不正確な事実、偏見、騙されやすさ、有毒なコンテンツの生成などの重大な欠陥を含む可能性があります。
終わりはあるのか?
神経ネットワークの進化は、ささやかな始まりから大規模な言語モデルの出現まで、深い哲学的な問いを提起します。「この旅はいつか終わるのでしょうか?」
技術の軌跡は常に無情な進展によって特徴付けられてきました。各マイルストーンは次のイノベーションへの礎石としての役割しか果たしません。人間の認知力と自然界の無限な複雑さを考慮すると、より知的で能力のある倫理的な神経ネットワークを開発するというクエストは終わりのない旅かもしれません。神経ネットワークの進化のウォークスルー(著者による画像)。
人工知能の基本的な構成要素である神経ネットワークは、情報処理の方法を革新し、技術の未来を示しています。人間の脳の複雑さに触発された、画像認識や自然言語理解から自動運転や医療診断までのタスクで重要な役割を果たしています。神経ネットワークの歴史的な進化を探究することで、AIの現代的な景観を形作るためにどのように進化してきたかを明らかにします。
始まりはどうだったのか?
神経ネットワーク、深層学習の基礎となる要素は、人間の脳内の神経細胞の複雑な生物学的ネットワークに概念的なルーツを持っています。この驚くべき概念は、生物学的なニューロンと計算ネットワークとの類似点に基づいています。
このアナロジーは、おおよそ1000億個のニューロンから構成される脳を中心にしています。各ニューロンはおよそ7,000個の他のニューロンとのシナプス接続を維持しており、人間の認知プロセスと意思決定の基盤となる複雑な神経ネットワークを作り出しています。
個々の生物学的なニューロンは、単純な電化学的プロセスを通じて動作します。樹状突起を通じて他のニューロンから信号を受け取ります。これらの入力信号があるレベル(あらかじめ定められた閾値)に達すると、ニューロンはオンに切り替わり、軸索を通じて電気化学的な信号を送ります。これにより、軸索端末に接続されたニューロンに影響を与えます。ここで重要な点は、ニューロンの応答がバイナリのスイッチのようなものであることです。つまり、発火(活性化)するか静かな状態になりますが、その間には中間状態はありません。
生物学的なニューロンは、人工ニューラルネットワークのインスピレーションとなりました(画像:ウィキペディア)。
人工ニューラルネットワークは、驚くべき複雑さや人間の脳の深い複雑さには及びませんが、従来のコンピュータには難しい問題を直感的に処理することで、重要な能力を示しています。一部の例としては、画像認識や歴史的データに基づく予測分析などがあります。
生物学的なニューロンがどのように機能し、人工ニューラルネットワークのインスピレーションとなってきた基本的な原理を探求したので、人工知能の領域を形作ってきたニューラルネットワークフレームワークの進化をたどってみましょう。
FFNN – フィードフォワードニューラルネットワーク
フィードフォワードニューラルネットワーク(FFNN)は、多層パーセプトロンとも呼ばれる基本的なタイプのニューラルネットワークであり、情報の流れ、相互接続された層、パラメータの最適化の原則に深く根ざしています。
FFNNの核となるのは、情報の一方向の旅です。すべてはn個のニューロンから成る入力層から始まります。ここには最初にデータが摂り込まれます。この層はネットワークの入り口として機能し、処理する必要がある入力特徴の受信器として働きます。そこから、データはネットワークの隠れた層を通じて変化の旅へと出発します。
FFNNの重要な要素の1つは、各層のニューロンが相互に複雑に接続されていることです。この相互接続性により、ネットワークはデータ内の計算を実行し、関係を捉えることができます。すべてのノードが情報の処理に役割を果たす通信ネットワークのようなものです。
データが隠れた層を通過するにつれ、一連の計算が行われます。隠れた層の各ニューロンは前の層のすべてのニューロンからの入力を受け取り、これらの入力に重み付けの合計を適用し、バイアス項を加え、結果を活性化関数(一般的にReLU、シグモイド、またはtanH)を通じて通過させます。これらの数学的操作により、ネットワークは入力から関連するパターンを抽出し、データ内の複雑で非線形な関係を捉えることができます。これが、より浅い機械学習モデルと比較してFFNNが真に優れている点です。
完全に接続されたフィードフォワードニューラルネットワークのアーキテクチャ(著者による画像)。
しかし、ここで終わりではありません。FFNNの真の力は、適応する能力にあります。トレーニング中、ネットワークは重みを調整して予測と実際の目標値の間の差を最小化します。この反復プロセスは、勾配降下法などの最適化アルゴリズムに基づくバックプロパゲーションと呼ばれます。バックプロパゲーションによって、FFNNはデータから学習し、予測や分類の正確さを向上させることができるのです。
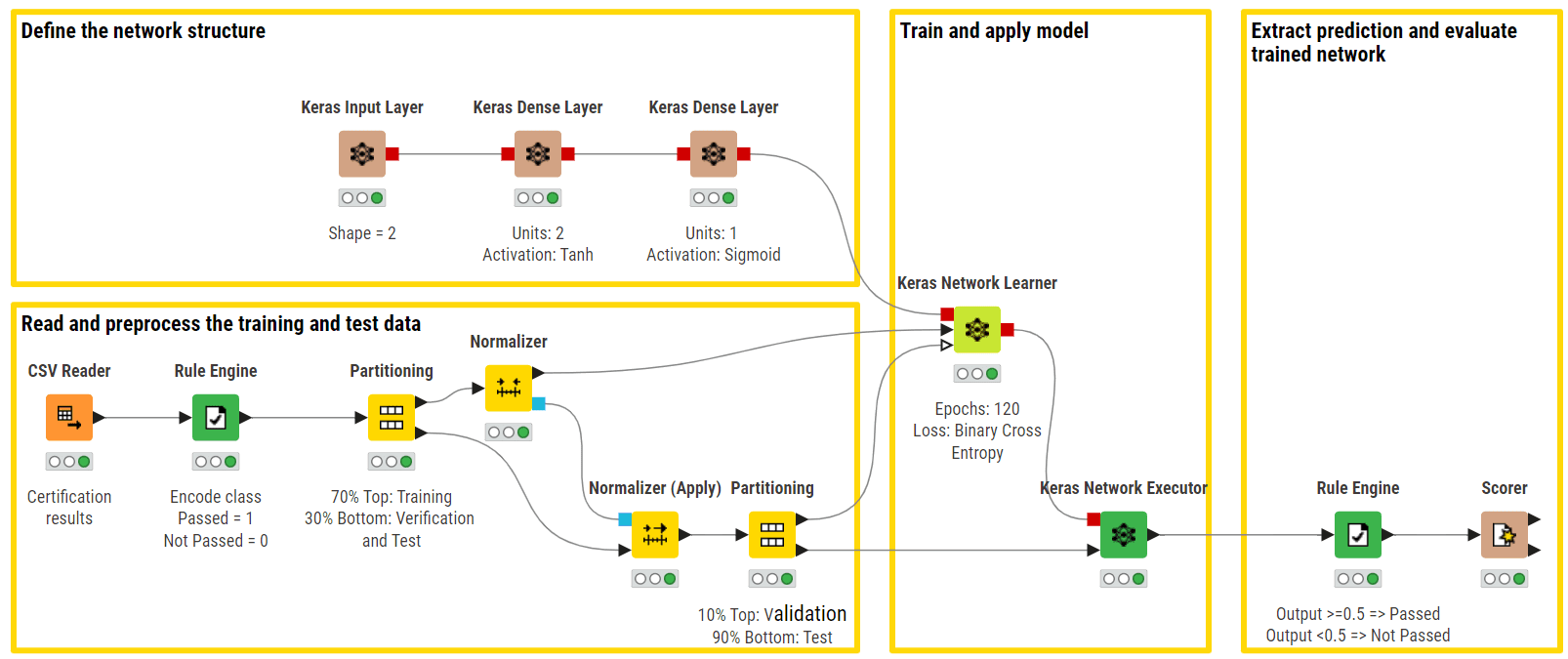
二値分類の認定試験(合格 vs 不合格)に使用されるFFNNのKNIMEワークフローの例。上部の枝にはネットワークのアーキテクチャが表示されており、入力層、完全に接続された隠れ層(tanH活性化関数)、およびSigmoid活性化関数を使用する出力層で構成されています(著者による画像)。
FFNNは強力で多機能ですが、いくつかの制限もあります。例えば、データの連続性や時間的/構文的な依存性を捉えることができません。これは、言語処理や時系列分析のタスクにおいて重要な要素です。これらの制限を克服する必要性から、新しいタイプのニューラルネットワークアーキテクチャの進化が促されました。この移行が、逐次データをよりよく処理するためのフィードバックループの概念を導入した再帰型ニューラルネットワーク(RNN)の道を切り開きました。
RNNおよびLSTM – 再帰型ニューラルネットワークおよび長期/短期記憶
RNNは、FFNNといくつかの類似点を共有しています。それらも層状の相互接続されたノードで構成され、予測や分類のためにデータを処理します。ただし、その主な違いは、逐次データを処理し、時間的な依存関係を捉える能力にあります。
FFNNでは、情報は入力層から出力層に一方向に流れます。これは、データの順序が重要ではないタスクに適しています。しかし、時系列データ、言語、音声などのシーケンスを扱う場合、コンテキストを維持し、データの順序を理解することが重要です。ここで、RNNが輝きます。
RNNはフィードバックループの概念を導入しています。これは一種の「メモリ」として機能し、ネットワークが前の入力に関する情報を捉え、現在の入力と出力に影響を与える隠れた状態を維持することができます。従来のニューラルネットワークは、入力と出力が互いに独立していると考えていますが、再帰型ニューラルネットワークの出力はシーケンス内の以前の要素に依存します。この再帰的な接続メカニズムによって、RNNは過去の情報を「覚えている」ことによってシーケンスを処理するのに特に適しています。
再帰ネットワークのもう一つの特徴は、ネットワークの各層ごとに同じ重みパラメータを共有し、これらの重みはバックプロパゲーションスルータイム(BPTT)アルゴリズムを活用して調整されます。BPTTアルゴリズムは、通常のバックプロパゲーションとは異なり、シーケンスデータに特化しています。
RNNのアンロール表示は、それぞれの入力が以前の入力からのコンテキスト情報で豊かになっています。色はコンテキスト情報の伝播を表しています(著者の画像)。
ただし、従来のRNNには制限があります。理論上は長期の依存関係を捉えることができるはずですが、実際にはその効果が制限されており、勾配消失の問題を引き起こす可能性もあります。勾配消失の問題は、多数の時間ステップにわたる情報の学習と記憶の能力を妨げます。
ここで、Long Short-Term Memory(LSTM)ユニットが登場します。LSTMユニットは、これらの問題を対処するために設計されており、その構造には3つのゲートが組み込まれています。それらはForgetゲート、Inputゲート、Outputゲートです。
- Forgetゲート:このゲートは、タイムステップからどの情報を破棄または忘れるかを決定します。セル状態と現在の入力を調べることで、現在の予測には関係のない情報を判断します。
- Inputゲート:このゲートはセル状態に情報を組み込む役割を担っています。入力と前のセル状態の両方を考慮し、状態を強化するためにどの新しい情報を追加するかを決定します。
- Outputゲート:このゲートはLSTMユニットによって生成される出力を結論付けます。現在の入力と更新されたセル状態の両方を考慮して、予測に利用するか時間ステップに渡すかを決定します。
Long-Short Term Memoryユニットの視覚的な表現(画像:Christopher Olah提供)。
複数のクラスの感情予測(ポジティブ、ネガティブ、ニュートラル)に使用されるLSTMユニットを備えたRNNのKNIMEワークフローの例(KNIMEワークフロー)。上部のブランチでは、異なる長さの文字列を処理するための入力層、埋め込み層、複数のユニットを備えたLSTM層、および予測値を返すための完全に接続された出力層によるネットワークアーキテクチャが定義されています。
まとめると、RNN、特にLSTMユニットは、自然言語処理、音声認識、時系列予測などのタスクにおいて、シーケンシャルデータに適したものであり、記憶を保持し、時間的な依存関係を捉える能力が重要です。
RNNがシーケンシャルな依存関係を捉えている間に、進化は異なるデータタイプや構造を持つ異なる応用にわたって畳み込みニューラルネットワーク(CNNs)に移行しています。
CNN – 畳み込みニューラルネットワーク
CNNは、2D画像や3Dビデオデータなどの画像データを処理するのに特に適したニューラルネットワークです。そのアーキテクチャは、少なくとも1つの畳み込み層を持つ多層フィードフォワードニューラルネットワークに基づいています。
CNNの特徴は、ネットワークの連結性と特徴抽出へのアプローチです。これにより、データの関連するパターンを自動的に識別することができます。従来のFFNNとは異なり、すべてのニューロンが前の層のすべてのニューロンに接続される従来の方法ではなく、CNNではカーネルまたはフィルタとして知られるスライディングウィンドウを使用します。このスライディングウィンドウは、入力データ上をスキャンし、特に空間的な関係が重要なタスク(画像内のオブジェクトの識別やビデオでの動きの追跡など)に強力です。カーネルが画像上を移動すると、カーネルとピクセル値の間で畳み込み演算が行われ(数学的にはクロス相関と呼ばれる)、非線形の活性化関数(通常はReLU)が適用されます。これにより、画像パッチ内に特徴が存在する場合は高い値、存在しない場合は小さい値が生成されます。
カーネルと一緒に、ストライド(つまり、カーネルをスライドさせるピクセル数)や膨張率(つまり、各カーネルセルの間隔)などのハイパーパラメータの追加と微調整により、ネットワークは特定の特徴に焦点を当て、一度に全入力を考慮せずに特定の領域でパターンと詳細を認識することができます。
ストライド長が2の畳み込み操作(Sumit Saha氏のGIFより)。
一部のカーネルは、エッジやコーナーの検出に特化しているかもしれません。他のカーネルは、猫、犬、または道路標識などのより複雑なオブジェクトの認識に調整されているかもしれません。畳み込みとプーリングのレイヤーを複数重ねることで、CNNは入力の階層的な表現を構築し、低レベルから高レベルの特徴を段階的に抽象化します。これは私たちの脳が視覚情報を処理する方法と同じです。
CNNによるバイナリ画像分類(猫対犬)のKNIMEワークフローの例。上部のブランチでは、畳み込み層と最大プーリング層を使用して画像から自動的に特徴を抽出するためのネットワークアーキテクチャが定義されています。抽出された特徴は、バイナリ分類を行うためのFFNNへの一次元入力として準備するためにフラット化レイヤーが使用されます。
CNNは特徴抽出に優れており、コンピュータビジョンの課題を革新していますが、彼らは新しいデータやコンテンツを生成するために設計されているわけではありません。これはネットワーク自体の固有の制限ではありませんが、強力なエンジンが燃料を持たないと、速い車は無意味です。実際、リアルで意味のある画像やビデオデータは収集が困難で高コストであり、著作権やデータプライバシーの制約もあります。この制約は、画像分類から創造的な合成への飛躍を示すCNNを基盤とした画期的なパラダイムの開発につながりました:生成的対抗ネットワーク(GAN)。
GAN – 生成的対抗ネットワーク
GANは、主ながら唯一の目的ではないが、与えられた実データセットに密接に似た合成データを生成することが主な目的となるニューラルネットワークの特定のファミリーです。GANの独創的なアーキテクチャ設計は、2つの中核モデルで構成されています:
- ジェネレータモデル:このニューラルネットワークのデュエットの最初のプレイヤーは、ジェネレータモデルです。このコンポーネントは、ランダムノイズまたは入力ベクトルが与えられた場合に、できるだけ実データに似る人工のサンプルを作成することを使命としています。まるで名作と区別できない絵画を作り出そうとする芸術贋作者と考えてください。
- 識別器モデル:対抗者の役割を果たすのは、識別器モデルです。この役割は、ジェネレータによって生成されたサンプルと元のデータセットから得られた本物のサンプルとを区別することです。本物の芸術作品の間に偽物を見つけようとする芸術鑑定家のようなものと考えてください。
ここで魔法が生じる:GANは、連続的な対立的なダンスに従事します。ジェネレータは、自らの芸術性を向上させ、その創造物をより説得力のあるものに継続的に微調整しようとします。一方、識別器は、真贋の違いを見極める能力を向上させるより鋭い探偵となります。
GANのアーキテクチャ(著者による画像)。
トレーニングが進むにつれて、ジェネレータと識別器のこの動的な相互作用は、興味深い結果をもたらします。ジェネレータは、識別器ですら本物と見分けがつかないほどリアリスティックなサンプルを生成しようと努力します。この競争は、両コンポーネントが能力を継続的に洗練させるように推進します。
その結果は何か?本物のように見えるデータ(画像、音楽、テキストなど)を驚くほど巧妙に生成するジェネレータです。これにより、画像合成、データ拡張、画像対画像変換、画像編集など、さまざまな分野で注目すべき応用が可能になりました。
GANによる合成画像の生成(動物、人の顔、シンプソンのキャラクターなど)のKNIMEワークフローの例。
GANは、ジェネレータと識別器を対決させることで現実的な画像やビデオのコンテンツ生成を先導しました。画像からシーケンシャルデータへの創造性と高度な操作のニーズを拡張し、より洗練された自然言語理解、機械翻訳、テキスト生成のモデルが導入されました。これにより、トランスフォーマーの開発が始まりました。トランスフォーマーは、長距離の言語依存性と意味的コンテキストを効果的にキャプチャすることで、以前のアーキテクチャを圧倒し、最新のAI駆動のアプリケーションの確固たる基盤となりました。
トランスフォーマー
2017年に開発されたTransformersは、伝統的な再発層を置き換えることができるユニークな機能を持っています:位置に関係なく、ドキュメント内のすべての単語間の複雑な関係をモデリングすることができる自己注意機構です。これにより、Transformersは自然言語の長距離依存性の課題に優れて取り組むことができます。Transformerアーキテクチャは、2つの主要な構成要素で構成されています:
- エンコーダ。ここでは、入力シーケンスがベクトルに埋め込まれ、その後自己注意機構に公開されます。後者は各トークンの注意スコアを計算し、他のトークンとの関係におけるその重要性を判断します。これらのスコアは、重み付きの合計を作成するために使用され、それが各トークンのコンテキストに応じた表現を生成するためのFFNNに供給されます。複数のエンコーダレイヤーはこのプロセスを繰り返し、階層的およびコンテキスト情報をキャプチャする能力を向上させます。
- デコーダ。このブロックは、出力シーケンスを生成し、エンコーダの出力と自身の過去のトークンを各ステップで適切にフォーカスし、正確な生成を実現します。入力コンテキストと以前に生成された出力の両方を考慮して、正確な生成を確保します。
Transformerモデルアーキテクチャ (画像 by: Vaswani et al., 2017)。
この文を考えてみましょう:”私は川を渡った後、銀行に着きました”。単語「銀行」には2つの意味があります-金融機関または川のほとりです。ここがTransformersの得意とするところです。彼らは「銀行」という言葉にスポットを当て、文の他の単語と比較し、注意スコアを割り当てることで、「銀行」の意図した意味を明確にします。これらのスコアによって、次の「銀行」の表現における各単語の影響が決定されます。この場合、「川」は高いスコアを得て、意味を明確にする役割を果たします。
このようにうまく機能するために、Transformersは数百万のトレーニング可能なパラメータに依存し、大量のテキストコーパスと洗練されたトレーニング戦略が必要です。Transformersで使用される注目すべきトレーニングアプローチの1つは、マスクされた言語モデリング(MLM)です。トレーニング中、入力シーケンス内の特定のトークンがランダムにマスクされ、モデルの目標はこれらのマスクされたトークンを正確に予測することです。この戦略により、モデルは単語間の文脈関係を把握する必要があるため、周囲の単語に頼らなければなりません。このアプローチはBERTモデルによって広まり、さまざまなNLPタスクで最先端の結果を達成するのに役立ちました。
TransformersにおけるMLMの代替手段は、自己回帰モデリングです。この方法では、モデルは一度に1つの単語を生成するようにトレーニングされますが、以前に生成された単語に基づいて条件付けられます。GPT(Generative Pre-trained Transformer)のような自己回帰モデルは、自由なテキスト生成、質問応答、テキスト補完など、次に最も適切な単語を単方向に予測することが目的のタスクで優れた性能を発揮します。
さらに、広範なテキストリソースの必要性を補うために、Transformersは並列処理において優れた性能を発揮しており、RNNやLSTMユニットのような従来の順次アプローチよりも高速にデータを処理することができます。この効率的な計算により、トレーニング時間が短縮され、自然言語処理、機械翻訳などの画期的な応用が可能となりました。
2018年にGoogleが開発したTransformerモデルの中でも大きな影響を与えたのがBERT(Bidirectional Encoder Representations from Transformers)です。BERTはMLMトレーニングを利用し、マスクトークンを予測する際に単語の左右の文脈を考慮するという双方向コンテキストの概念を導入しました。この双方向アプローチは、モデルが単語の意味と文脈の微妙なニュアンスを理解する能力を大幅に向上させ、自然言語理解やさまざまなNLPタスクの新たな基準を確立しました。
BERTを用いたマルチクラス感情予測(ポジティブ、ネガティブ、ニュートラル)のKNIMEワークフローの例。最小限の前処理が行われ、事前学習済みBERTモデルが微調整されて利用されています。
強力な自己注意機構を導入したTransformersに続いて、アプリケーションの多様性やドキュメントの要約、テキストの編集、コード生成など複雑な自然言語タスクの実行を求める需要の増加により、大規模な言語モデルの開発が必要とされました。これらのモデルは、数十億の訓練可能なパラメータを備えた深層ニューラルネットワークを使用して、このようなタスクで優れた性能を発揮し、データ分析業界の進化する要件に対応しています。
LLM – ラージランゲージモデル
ラージランゲージモデル(LLM)は、最近注目を集めている革新的なマルチパーパスでマルチモーダル(画像、音声、テキストの入力を受け付ける)の深層ニューラルネットワークのカテゴリです。ラージという形容詞は、訓練可能な数十億のパラメータを含む、その広範なサイズから来ています。最もよく知られている例には、OpenAIのChatGPT、GoogleのBard、MetaのLLaMaなどがあります。
LLMsの特徴は、人間らしいテキストの処理と生成能力における無類の能力と柔軟性にあります。彼らは、テキストの補完や翻訳、質問応答、内容の要約など、自然言語理解と生成のタスクで優れたパフォーマンスを発揮します。彼らの成功の鍵は、大規模なテキストコーパスでの継続的なトレーニングにあり、言語の微妙なニュアンス、文脈、意味を豊富に理解する能力を持っています。
これらのモデルは、複数のセルフアテンションメカニズムを持つ深層ニューラルアーキテクチャを採用しており、与えられた文脈で異なる単語やフレーズの重要性を評価することができます。このダイナミックな適応性により、さまざまな種類の入力の処理、複雑な言語構造の理解、人間が定義したプロンプトに基づいた出力の生成に特に優れています。
「KNIMEワークフロー」のKNIMEワークフローの例を使ったAIアシスタントの作成。これには、OpenAIのChatGPTとカスタムドキュメントのベクトルストアを利用して、ドメイン固有の質問に答える能力が備わっています。
LLMsは、医療や金融からエンターテイメントやカスタマーサービスまで、さまざまな産業で多くの応用可能性を提供しています。彼らは創造的な文章作成やストーリーテリングの新たな領域も切り拓いています。
しかしながら、彼らの巨大なサイズ、リソースを多く必要とするトレーニングプロセス、生成コンテンツにおける潜在的な著作権侵害などにより、倫理的な使用、環境への影響、アクセシビリティに関する懸念も引き起こされています。最後に、ますます改善されているものの、LLMsには「幻視」による誤った事実の創造、偏見、騙されやすさ、有害なコンテンツの生成など、重大な欠点も存在する可能性があります。
終わりはあるのか?
ニューラルネットワークの進化、その謙虚な始まりから大規模言語モデルの台頭まで、深遠な哲学的な問いを提起しています。この旅はいつか終わるのでしょうか?
技術の進歩は常に着実に進んできました。各マイルストーンは次のイノベーションへの礎となります。人間の認知と理解を模倣できる機械を作り出すために努力する中で、究極の目的地が存在するのか、頂点に達したと言える時点があるのか、ということに思いを巡らすのは魅力的です。
しかし、人間の好奇心の本質と自然界の無限の複雑さは、別の答えを示唆しています。私たちが宇宙に対する理解を深めるように、より知能が高く、能力がある、倫理的なニューラルネットワークの開発の追求は終わりのない旅かもしれません。
AnilはKNIMEのデータサイエンスエバンジェリストです。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles