「教科書で学ぶ教師なし学習:K-Meansクラスタリングの実践」
Textbook Unsupervised Learning with K-Means Clustering
K-Meansクラスタリングは、データサイエンスで最もよく使用される教師なし学習アルゴリズムの一つです。データポイント間の類似性に基づいてデータセットをクラスタやグループに自動的に分割するために使用されます。
この短いチュートリアルでは、K-Meansクラスタリングアルゴリズムの動作方法を学び、scikit-learnを使用して実データに適用します。さらに、結果を視覚化してデータの分布を理解します。
- オーディオSRにお会いください:信じられないほどの48kHzの音質にオーディオをアップサンプリングするためのプラグ&プレイであり、ワンフォーオールのAIソリューション
- LLMs(Language Model)と知識グラフ
- 「ベイチュアン2に会おう:7Bおよび13Bのパラメータを持つ大規模な多言語言語モデルのシリーズ、2.6Tトークンでゼロからトレーニングされました」
K-Meansクラスタリングとは?
K-Meansクラスタリングは、クラスタリング問題を解決するために使用される教師なし機械学習アルゴリズムです。このアルゴリズムの目標は、変数Kによって表されるクラスタの数を見つけることです。
K-Meansアルゴリズムの動作方法は以下の通りです:
- データをグループ化するためにデータをグループ化したいクラスタ数Kを指定します。
- K個のクラスタセンターまたは重心をランダムに初期化します。これは、初期セントロイドとしてK個のデータポイントをランダムに選択することで行われます。
- ユークリッド距離に基づいて、各データポイントを最も近いクラスタ重心に割り当てます。与えられた重心に最も近いデータポイントは、そのクラスタの一部と見なされます。
- 各クラスタに割り当てられたすべてのデータポイントの平均を取ることで、クラスタの重心を再計算します。
- セントロイドが動かなくなるか、反復回数が指定された制限に達するまで、ステップ3と4を繰り返します。これはアルゴリズムが収束したときに行われます。

K-Meansの目的は、データポイントとそれらに割り当てられたクラスタ重心との二乗距離の合計を最小化することです。これは、データポイントを最も近い重心に反復的に再割り当てし、クラスタの中心に重心を移動することによって実現され、よりコンパクトで分離されたクラスタが得られます。
K-Meansクラスタリングの実例
これらの例では、Kaggleからのモール顧客セグメンテーションデータを使用し、K-Meansアルゴリズムを適用します。また、エルボー法を使用して最適なK(クラスタ数)を見つけ、クラスタを視覚化します。
データの読み込み
pandasを使用してCSVファイルを読み込み、”CustomerID”をインデックスとします。
import pandas as pd
df_mall = pd.read_csv("Mall_Customers.csv",index_col="CustomerID")
df_mall.head(3)
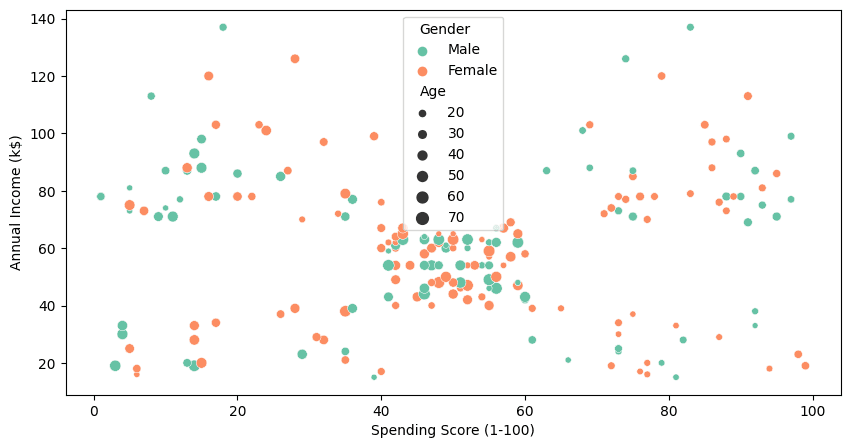
データセットには4つの列があり、私たちは年齢、年間収入、および顧客の支出スコアの3つに興味があります。

視覚化
すべての4つの列を視覚化するために、seabornの`scatterplot`を使用します。
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(1 , figsize = (10 , 5) )
sns.scatterplot(
data=df_mall,
x="Spending Score (1-100)",
y="Annual Income (k$)",
hue="Gender",
size="Age",
palette="Set2"
);
K-Meansクラスタリングなしでも、明らかに40-60の支出スコアと40kから70kの年間収入の間にクラスタが見えます。さらにクラスタを見つけるために、次のパートでクラスタリングアルゴリズムを使用します。
正規化
クラスタリングアルゴリズムを適用する前に、データを正規化して外れ値や異常値を排除することが重要です。ここでは、”Gender”と”Age”の列を削除し、残りの列を使用してクラスタを見つけます。
from sklearn import preprocessing
X = df_mall.drop(["Gender","Age"],axis=1)
X_norm = preprocessing.normalize(X)
エルボーメソッド
K-MeansアルゴリズムにおけるKの最適な値は、エルボーメソッドを使用して見つけることができます。これには、1から10までのクラスタ数の各Kのイナーシャ値を求め、可視化する必要があります。
import numpy as np
from sklearn.cluster import KMeans
def elbow_plot(data,clusters):
inertia = []
for n in range(1, clusters):
algorithm = KMeans(
n_clusters=n,
init="k-means++",
random_state=125,
)
algorithm.fit(data)
inertia.append(algorithm.inertia_)
# プロット
plt.plot(np.arange(1 , clusters) , inertia , 'o')
plt.plot(np.arange(1 , clusters) , inertia , '-' , alpha = 0.5)
plt.xlabel('クラスタの数') , plt.ylabel('イナーシャ')
plt.show();
elbow_plot(X_norm,10)
最適な値は3です。 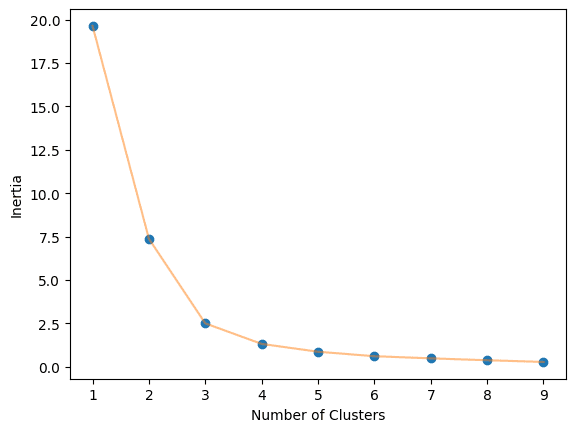
KMeansクラスタリング
scikit-learnからKMeansアルゴリズムを使用し、Kの値を指定します。その後、トレーニングデータセットに適合させ、クラスタラベルを取得します。
algorithm = KMeans(n_clusters=3, init="k-means++", random_state=125)
algorithm.fit(X_norm)
labels = algorithm.labels_
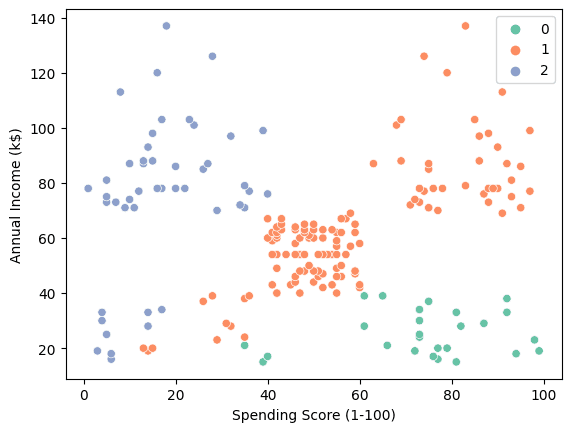
3つのクラスタを可視化するために、散布図を使用できます。
sns.scatterplot(data = X, x = 'Spending Score (1-100)', y = 'Annual Income (k$)', hue = labels, palette="Set2");
- “0”: 収入が低く、支出が高い人。
- “1”: 平均的な収入で高い支出を行う人。
- “2”: 収入が高く、支出が低い人。
 この情報を活用して、パーソナライズされた広告を作成し、顧客の忠誠心を高め、収益を増やすことができます。
この情報を活用して、パーソナライズされた広告を作成し、顧客の忠誠心を高め、収益を増やすことができます。
異なる特徴の使用
次に、年齢と支出スコアをクラスタリングアルゴリズムの特徴として使用します。これにより、顧客の分布の完全なイメージが得られます。データの正規化のプロセスを繰り返します。
X = df_mall.drop(["Gender","Annual Income (k$)"],axis=1)
X_norm = preprocessing.normalize(X)
最適なクラスタ数を計算します。
elbow_plot(X_norm,10)
K=3のクラスタでK-Meansアルゴリズムをトレーニングします。 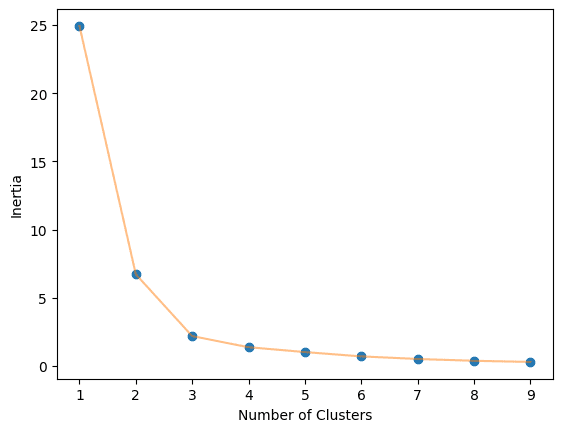
algorithm = KMeans(n_clusters=3, init="k-means++", random_state=125)
algorithm.fit(X_norm)
labels = algorithm.labels_
散布図を使用して、3つのクラスタを可視化します。
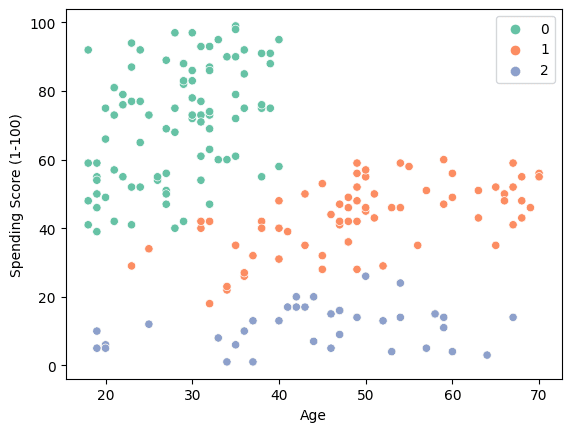
sns.scatterplot(data = X, x = 'Age', y = 'Spending Score (1-100)', hue = labels, palette="Set2");
- “0”: 若い支出が高い人。
- “1”: 中年から高齢までのVoAGI支出者。
- “2”: 支出が低い人。
この結果から、企業は20-40歳の所得のある個人をターゲットにすることで利益を増やすことができると示唆されています。
私たちは、支出スコアの箱ひげ図を視覚化することで、さらに深く掘り下げることができます。これにより、クラスタが支出の習慣に基づいて形成されていることが明確に示されます。
sns.boxplot(x = labels, y = X['Spending Score (1-100)']); 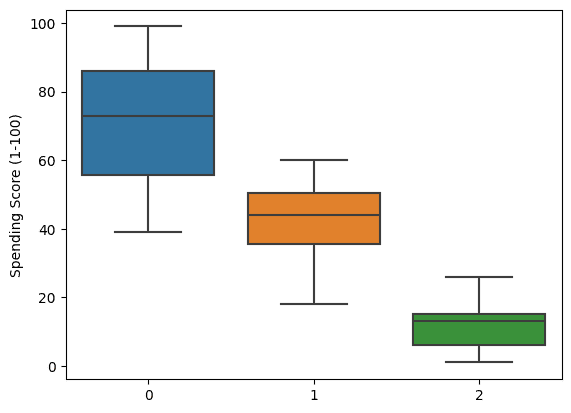
結論
このK-Meansクラスタリングチュートリアルでは、ターゲット広告を可能にするために、K-Meansアルゴリズムを顧客セグメンテーションに適用する方法を探索しました。K-Meansは完璧なクラスタリングアルゴリズムではありませんが、多くの実世界のユースケースに対してシンプルで効果的なアプローチを提供します。
K-Meansのワークフローを進行し、Pythonで実装することで、データを異なるクラスタに分割するアルゴリズムの動作に関する洞察を得ました。エルボー法による最適なクラスタ数の見つけ方や、クラスタ化されたデータの視覚化などの技術を学びました。
scikit-learnは他にも多くのクラスタリングアルゴリズムを提供していますが、K-Meansはその速度、スケーラビリティ、解釈の容易さで特に優れています。 Abid Ali Awan(@1abidaliawan)は、機械学習モデルの構築が大好きな認定データサイエンティストです。現在、彼はコンテンツ作成および機械学習およびデータサイエンス技術に関する技術ブログの執筆に焦点を当てています。Abidはテクノロジーマネジメントの修士号とテレコミュニケーションエンジニアリングの学士号を保持しています。彼のビジョンは、メンタルヘルスに苦しむ学生のためにグラフニューラルネットワークを使用したAI製品を構築することです。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





