TensorRT-LLMとは、NVIDIA Tensor Core GPU上の最新のLLMにおいて推論パフォーマンスを高速化し最適化するためのオープンソースライブラリです
TensorRT-LLMは、Tensor Core GPU上で推論パフォーマンスを高速化し最適化するためのオープンソースライブラリです


人工知能(AI)の大規模言語モデル(LLM)は、テキストを生成したり、言語を翻訳したり、さまざまな形式の創造的な素材を書いたり、質問に役立つ回答を提供したりすることができます。ただし、LLMにはいくつかの問題があります。例えば、バイアスが含まれる可能性のある大規模なテキストやコードのデータセットで訓練されていることです。LLMが生成する結果には、これらの偏見が反映され、否定的なステレオタイプを強化し、誤った情報を広める可能性があります。時には、LLMは現実に基づかない文章を生成することもあります。これらの体験を幻覚と呼びます。幻覚的なテキストを読むことで、誤解や誤った推論が生じる可能性があります。LLMの内部の動作原理を理解するには、作業が必要です。そのため、医療や金融など、オープンさと責任が重要な文脈で問題が生じる可能性があります。LLMのトレーニングと展開には、大量の計算能力が必要です。これにより、多くの中小企業や非営利団体にはアクセスできなくなる可能性があります。スパム、フィッシングメール、フェイクニュースなど、悪情報がLLMを使用して生成されることがあります。これによってユーザーや企業が危険にさらされる可能性があります。
NVIDIAの研究者は、Meta、Anyscale、Cohere、Deci、Grammarly、Mistral AI、MosaicML(現在はDatabricksの一部)、OctoML、Tabnine、Together AIなどの業界のリーダーと協力し、LLMの推論の高速化とパーフェクト化に取り組んでいます。これらの改善は、近日公開予定のオープンソースNVIDIA TensorRT-LLMソフトウェアバージョンに含まれます。TensorRT-LLMは、NVIDIAのGPUを利用して最適化されたカーネル、前処理および後処理フェーズ、およびマルチGPU/マルチノード通信プリミティブを提供するディープラーニングコンパイラです。開発者は、C++やNVIDIA CUDAの詳しい知識を必要とせずに、新しいLLMを試行することができ、優れたパフォーマンスと迅速なカスタマイズオプションを提供します。オープンソースのモジュラーなPython APIを備えたTensorRT-LLMは、LLMの開発において新しいアーキテクチャや改良を定義、最適化、実行することを容易にします。
NVIDIAの最新のデータセンターGPUを活用することで、TensorRT-LLMはLLMのスループットを大幅に向上させながら、経費を削減することを目指しています。プロダクションにおける推論のためのLLMの作成、最適化、実行には、TensorRT Deep Learning Compiler、FasterTransformerからの最適化されたカーネル、前処理および後処理、マルチGPU/マルチノード通信をカプセル化した、わかりやすいオープンソースのPython APIが提供されます。
- Stability AIが初の日本語ビジョン言語モデルをリリース
- 「低コスト四足ロボットはパルクールをマスターできるのか? アジャイルなロボット運動のための革命的な学習システムを公開する」
- 「ジュラシックパークへの待ち時間は終わりましたか?このAIモデルは、イメージからイメージへの変換を使用して、古代の化石を生き返らせます」
TensorRT-LLMにより、より多様なLLMアプリケーションが可能になります。MetaのLlama 2やFalcon 180Bなどの700億パラメータのモデルが登場した現在、定型的なアプローチはもはや実用的ではありません。このようなモデルのリアルタイムパフォーマンスは、通常、マルチGPUの構成や複雑な調整に依存しています。TensorRT-LLMは、重み行列をデバイス間で分散させるテンソル並列処理を提供することで、このプロセスを効率化し、開発者が手動で断片化や再配置を行う必要をなくします。
また、LLMアプリケーションには非常に変動するワークロードが特徴であるため、フライト中のバッチ最適化は効果的に管理するための注目すべき機能です。この機能により、質問応答型チャットボットや文書要約などのタスクにおいて、動的な並列実行が可能となり、GPUの利用率を最大限に引き出すことができます。AIの実装の規模と範囲の拡大を考慮すると、企業は所有コストの削減を期待できます。
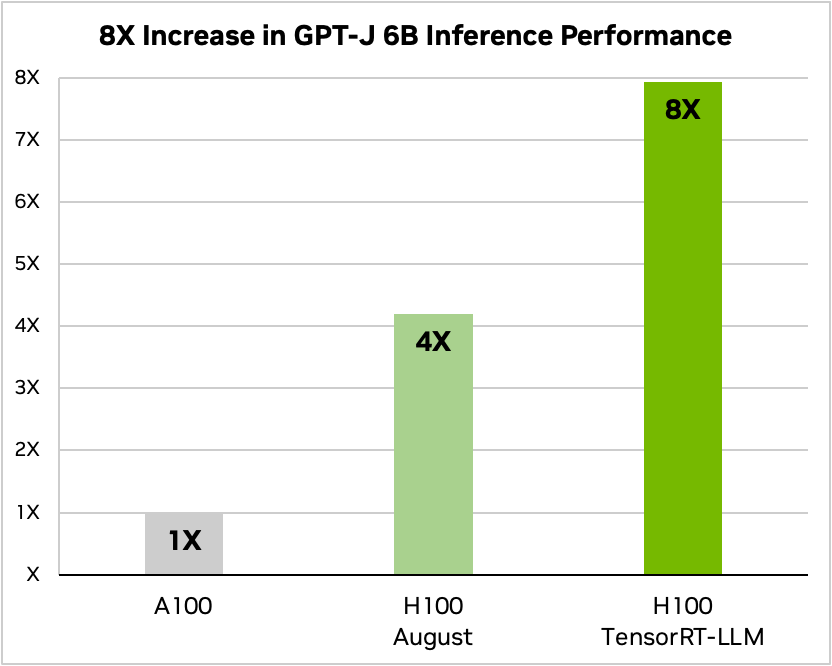
性能面でも驚異的な結果が出ています。TensorRT-LLMを使用した場合、TensorRT-LLMを使用しない場合やA100と比較した場合、NVIDIA H100を使用した場合の記事要約などのタスクで、8倍の性能向上が見られます。
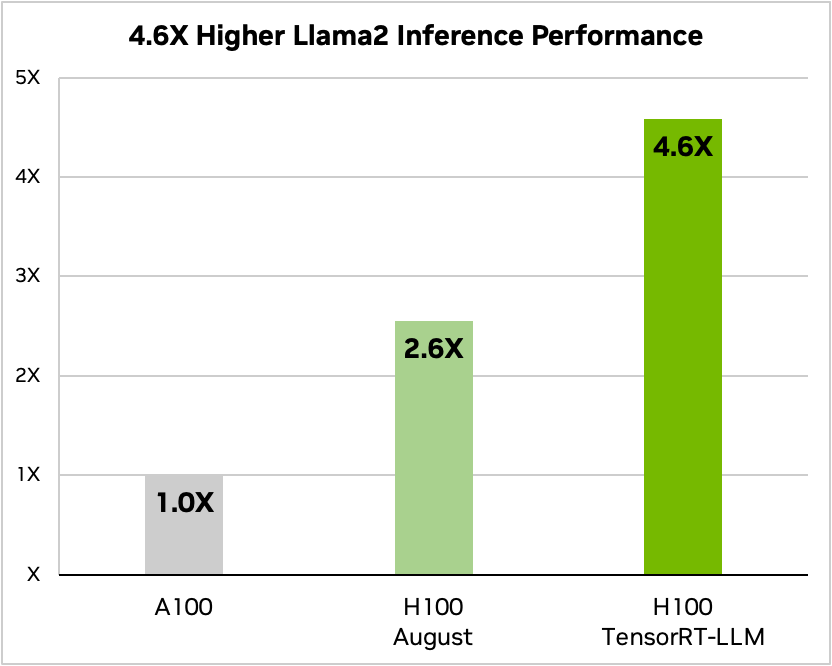
TensorRT-LLMは、最近Metaによってリリースされ、多くの企業が生成型AIを実装したいと望む広く使用されているLlama 2という言語モデルにおいて、A100 GPUと比較して推論性能を4.6倍向上させることができます。
要約すると、LLMは急速に発展しています。毎日、モデルデザインのエコシステムは拡大し続けています。その結果、より大きなモデルは新たな可能性とユースケースを開拓し、あらゆるセクターでの採用を促進しています。データセンターはLLMの推論によって進化しています。高い性能と高い精度により、ビジネスのTCOは改善されています。モデルの変更によって可能になるより良いクライアント体験は、売上と利益の増加につながります。最先端のLLMを最大限活用するためには、推論展開イニシアチブの計画時に考慮すべき追加の要素が数多くあります。最適化は滅多に自動的には行われません。ユーザーは並列処理、エンドツーエンドのパイプライン、洗練されたスケジューリング手法について考えながら微調整を行う必要があります。ユーザーは、精度が異なるデータを正確性を損なうことなく処理できるコンピュータシステムが必要です。TensorRT-LLMは、生成型AIの推論のためにLLMを作成、最適化、実行するためのシンプルでオープンソースのPython APIです。TensorRTのDeep Learning Compiler、最適化されたカーネル、前処理および後処理、およびマルチGPU/マルチノード通信を特徴としています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






