テンセントAIラボの研究者たちは、テキスト対応の画像プロンプトアダプタ「IP-Adapter」を開発しました:テキストから画像への拡散モデルのためのアダプタです
Tencent AI Lab researchers developed the IP-Adapter, a text-to-image diffusion model adapter.


「リンゴ」と言えば、あなたの頭にすぐにリンゴのイメージが浮かびます。私たちの脳の働き方が魅力的であるように、生成AIも同じレベルの創造性とパワーをもたらし、機械が私たちがオリジナルコンテンツと呼ぶものを作り出すことができるようになりました。最近では、非常にリアルな画像を作成するテキストから画像へのモデルが登場しています。モデルに「リンゴ」とフィードすると、さまざまな種類のリンゴの画像を得ることができます。
しかし、これらのモデルがテキストのプロンプトだけで正確に私たちが望むものを生成することは非常に困難です。通常、適切なプロンプトの慎重な作成を必要とします。これを行う別の方法は、画像のプロンプトを利用することです。現在の既存のモデルから直接的にモデルを洗練するための技術は成功していますが、大量の計算能力を必要とし、異なる基礎モデル、テキストプロンプト、構造の調整との互換性が欠けています。
制御可能な画像生成の最近の進歩は、テキストから画像への拡散モデルのクロスアテンションモジュールに関する懸念を浮き彫りにしています。これらのモジュールは、事前学習済みの拡散モデルのクロスアテンションレイヤーでキーと値のデータを射影するために調整されたウェイトを使用し、主にテキストの特徴に最適化されています。そのため、このレイヤーで画像とテキストの特徴を統合すると、画像の特異な詳細が無視される可能性があり、参照画像を利用する際に生成中の広範な制御(たとえば、画像のスタイルの管理)につながることがあります。
- 「Appleの研究者が、ポーズされた画像から詳細な3D再構築を生成するエンドツーエンドネットワークを提案」
- マイクロソフトと香港浸会大学の研究者が、WizardCoder A Code Evol-Instruct Fine-Tuned Code LLMを紹介しました
- AIはロボットが全身を使ってオブジェクトを操作するのを支援します

上記の画像では、右側の例は画像のバリエーション、マルチモーダル生成、および画像プロンプトによる埋め込みの結果を示しており、左側の例は画像プロンプトと追加の構造条件による制御可能な生成の結果を示しています。
研究者たちは、現在の方法によって引き起こされる課題に対処するために、効果的な画像プロンプトアダプターであるIP-Adapterを導入しました。IP-Adapterは、テキストと画像の特徴を処理するための別個のアプローチを使用します。拡散モデルのUNetに、画像の特徴に特化した追加のクロスアテンションレイヤーを追加しました。トレーニング中、新しいクロスアテンションレイヤーの設定を調整し、元のUNetモデルを変更せずに残します。このアダプターは効率的でありながら強力です。たった2200万のパラメーターでも、IPアダプターはテキストから画像への拡散モデルから派生した完全に微調整された画像プロンプトモデルと同じくらい良い画像を生成することができます。
その研究結果は、IP-Adapterが再利用可能かつ柔軟であることを証明しています。ベースの拡散モデルでトレーニングされたIP-Adapterは、同じベースの拡散モデルから微調整された他のカスタムモデルに一般化することができます。さらに、IP-AdapterはControlNetなどの他の制御アダプターとも互換性があり、画像プロンプトと構造制御の容易な組み合わせが可能です。別個のクロスアテンション戦略のおかげで、画像プロンプトはテキストプロンプトと並行して動作し、マルチモーダルな画像を作成します。
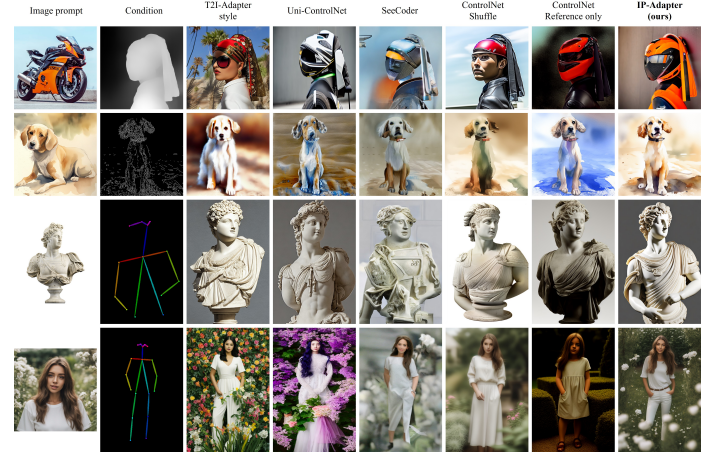
上記の画像は、IP-Adapterを他の方法と比較した場合の異なる構造条件を示しています。IP-Adapterの効果的な性能にもかかわらず、それはコンテンツとスタイルで参照画像に似た画像しか生成できません。言い換えれば、テキスト逆転やドリームブースなどの既存の方法のように、与えられた画像の主題と非常に一致した画像を合成することはできません。将来的には、研究者は一貫性を高めるために、より強力な画像プロンプトアダプターを開発することを目指しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 東京大学の研究者たちは、静的バンディット問題からより困難な動的環境に向けた拡張フォトニック強化学習手法を開発しました
- 「SMARTは、AI、自動化、そして働き方の未来を進めるための研究グループを立ち上げました」
- スマートフォンにおける通話セキュリティリスクを明らかにするための研究ハック
- 「研究者が深層学習と物理学を組み合わせてMRIスキャンを修正する」
- 光を基にした機械学習システムは、より強力で効率的な大規模言語モデルを生み出す可能性がある
- 「研究者がロボットに自己学習で食器洗い機やドアを開ける手助けをしています」
- 「MITの研究者が深層学習と物理学を使用して、動きによって損傷を受けたMRIスキャンを修正する」






