「教師付き学習の実践:線形回帰」
Supervised Learning Linear Regression

基本的な概要
線形回帰は、入力特徴量に基づいて連続的な目標変数を予測するための基本的な教師あり機械学習アルゴリズムです。その名前が示すように、従属変数と独立変数の関係が線形であることを仮定しています。したがって、従属変数Yを独立変数Xに対してプロットしようとすると、直線が得られます。この直線の方程式は次のように表されます:
- 「トランスフォーマーとサポートベクターマシンの関係は何ですか? トランスフォーマーアーキテクチャにおける暗黙のバイアスと最適化ジオメトリを明らかにする」
- 富士通とLinux Foundationは、富士通の自動機械学習とAIの公平性技術を発表:透明性、倫理、アクセシビリティの先駆者
- 「言語モデルは放射線科を革新することができるのか?Radiology-Llama2に会ってみてください:指示調整というプロセスを通じて特化した大規模な言語モデル」
ここで、
- Y 予測された出力。
- X = 複数の線形回帰の入力特徴量または特徴量行列
- b0 = 切片(直線がY軸と交差する点)。
- b1 = 直線の傾きまたは係数。
線形回帰の中心的なアイデアは、データポイントに対して最適な適合直線を見つけることであり、実際の値と予測値の間の誤差を最小限にすることです。これは、b0とb1の値を推定することによって行います。その後、この直線を予測に利用します。
Scikit-Learnを使用した実装
線形回帰の理論を理解したので、さらに理解を深めるために、Pythonの人気のある機械学習ライブラリであるScikit-Learnを使用してシンプルな線形回帰モデルを構築しましょう。理解を深めるために、以下を参考にしてください。
1. 必要なライブラリのインポート
まず、必要なライブラリをインポートする必要があります。
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
2. データセットの分析
データセットはこちらにあります。トレーニングとテスト用に別々のCSVファイルが用意されています。進む前に、データセットを表示して分析しましょう。
# CSVファイルからトレーニングデータセットとテストデータセットを読み込む
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
# トレーニングデータセットの最初の数行を表示して構造を理解する
print(train.head())
出力: 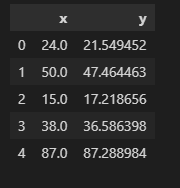
データセットには2つの変数が含まれており、xの値に基づいてyを予測したいとします。
# データ型や欠損値など、トレーニングデータセットとテストデータセットに関する情報をチェックする
print(train.info())
print(test.info())
出力:
RangeIndex: 700 entries, 0 to 699
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 x 700 non-null float64
1 y 699 non-null float64
dtypes: float64(2)
memory usage: 11.1 KB
RangeIndex: 300 entries, 0 to 299
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 x 300 non-null int64
1 y 300 non-null float64
dtypes: float64(1), int64(1)
memory usage: 4.8 KB
上記の出力から、トレーニングデータセットに欠損値が1つあることがわかります。次のコマンドで欠損値を削除できます:
train = train.dropna()
また、データセットに重複があるかどうかをチェックし、モデルに入力する前に重複を削除してください。
duplicates_exist = train.duplicated().any()
print(duplicates_exist)
出力:
False
2. データセットの前処理
次に、以下のコードを使用して、トレーニングデータとテストデータ、および対象データを準備します。
# トレーニングデータおよびテストデータの x と y 列を抽出
X_train = train['x']
y_train = train['y']
X_test = test['x']
y_test = test['y']
print(X_train.shape)
print(X_test.shape)
出力:
(699, )
(300, )
上記のコードでは、1次元の配列を取得しています。一部の機械学習モデルでは、1次元の配列を使用することができますが、一般的な方法ではありませんし、予期しない動作を引き起こす可能性があります。そのため、上記のコードを (699,1) および (300,1) に変形し、データポイントごとに1つのラベルがあることを明示的に指定します。
X_train = X_train.values.reshape(-1, 1)
X_test = X_test.values.reshape(-1,1)
特徴量が異なるスケールである場合、一部の特徴量がモデルの学習プロセスを支配し、正しくないまたは最適でない結果になることがあります。そのため、特徴量を標準化して、平均が0、標準偏差が1になるようにします。
変更前:
print(X_train.min(),X_train.max())
出力:
(0.0, 100.0)
標準化:
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
print((X_train.min(),X_train.max())
出力:
(-1.72857469859145, 1.7275858114641094)
これで、必要なデータの前処理手順は完了し、データはトレーニング用に準備ができました。
4. データセットの可視化
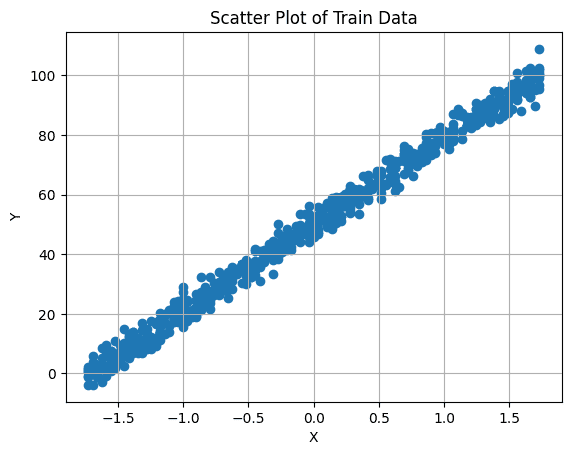
ターゲット変数と特徴量の関係を最初に可視化することは重要です。散布図を作成することで、これを行うことができます:
# 散布図を作成する
plt.scatter(X_train, y_train)
plt.xlabel('X')
plt.ylabel('Y')
plt.title('Train Data の散布図')
plt.grid(True) # グリッドを有効にする
plt.show()
5. モデルの作成とトレーニング
次に、Scikit Learn を使用して線形回帰モデルのインスタンスを作成し、トレーニングデータに適合させてみましょう。これにより、データに最も適合する直線の係数(傾き)が求められます。この直線を使用して予測が行われます。このステップのコードは次のようになります:
# 線形回帰モデルを作成する
model = LinearRegression()
# トレーニングデータにモデルを適合させる
model.fit(X_train, y_train)
# テストデータの目標値を予測するために訓練されたモデルを使用する
predictions = model.predict(X_test)
# モデルの性能を評価する評価指標として平均二乗誤差(MSE)を計算する
mse = mean_squared_error(y_test, predictions)
print(f'平均二乗誤差は:{mse:.4f}')
出力:
平均二乗誤差は:9.4329
6. 回帰直線の可視化
以下のコマンドを使用して回帰直線をプロットすることができます:
# 回帰直線をプロットする
plt.plot(X_test, predictions, color='red', linewidth=2, label='回帰直線')
plt.xlabel('X')
plt.ylabel('Y')
plt.title('線形回帰モデル')
plt.legend()
plt.grid(True)
plt.show()
出力: 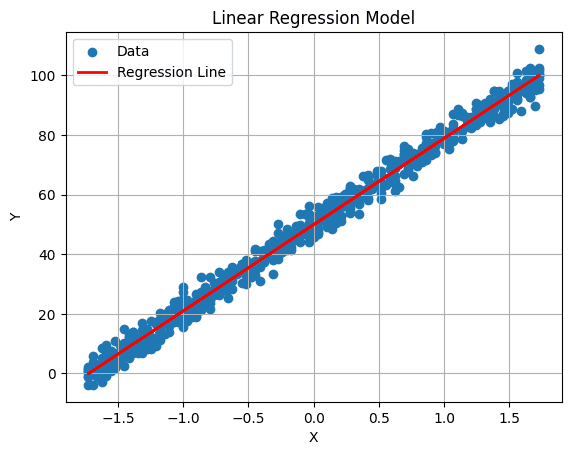
結論
以上です!Scikit-learnを使用して基本的な線形回帰モデルを正常に実装しました。ここで習得したスキルは、より多くの特徴を持つ複雑なデータセットに対処するために拡張することができます。これは、データ駆動型の問題解決とイノベーションのエキサイティングな世界への扉を開くために探求する価値のあるチャレンジです。 Kanwal Mehreenは、データサイエンスと医療の応用に興味を持つ、将来有望なソフトウェア開発者です。Kanwalは、APAC地域のGoogle Generation Scholar 2022に選ばれました。Kanwalは、トレンドトピックに関する記事を書くことで技術的な知識を共有することが大好きで、テック業界における女性の代表性向上に情熱を持っています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





