METAのHiera:複雑さを減らして精度を高める
Streamlining Complexity and Enhancing Accuracy with META's Hiera
| ARTIFICIAL INTELLIGENCE | COMPUTER VISION | VITs |
シンプリシティによって、AIは驚異的なパフォーマンスと驚くべき速度を発揮できる
畳み込みニューラルネットワークは、20年以上にわたってコンピュータビジョンの分野を支配してきました。トランスフォーマーの登場により、彼らは放棄されることになると信じられていました。 しかし、多くの実践者はプロジェクトで畳み込みベースのモデルを使用しています。なぜですか?
この記事では、次の質問に答えようとしています。
- ビジョン・トランスフォーマーとは何ですか?
- 彼らの限界は何ですか?
- それらを克服することができますか?
- META Hieraはなぜ成功するのでしょうか?
ビジョン・トランスフォーマー:画像の価値は何単語分?

ビジョン・トランスフォーマーは、最近のビジョンベンチマークで支配的であり、しかし、彼らは正確に何ですか?
数年前まで、畳み込みニューラルネットワークがビジョンタスクの標準でした。しかし、2017年にトランスフォーマーがリリースされ、NLP世界を覆いました。記事Attention is all you needでは、自己アテンションのみを使用して構築されたモデルが、RNNやLSTMよりも優れたパフォーマンスを発揮することを示しています。そこで、すぐに疑問に思うのは、画像にトランスフォーマーを適用することは可能なのでしょうか?
自己アテンションの統合が含まれたハイブリッドモデルは、2020年以前から試みられていました。いずれにせよ、これらのモデルはうまくスケーリングできませんでした。トランスフォーマーを画像とネイティブに使用する方法を見つけることが必要でした。
2020年、Googleの作者たちは、最善の方法は画像をさまざまなパッチに分割し、シーケンスの埋め込みを持つことであると判断しました。この方法で、画像はモデルのトークン(単語)のように扱われます。
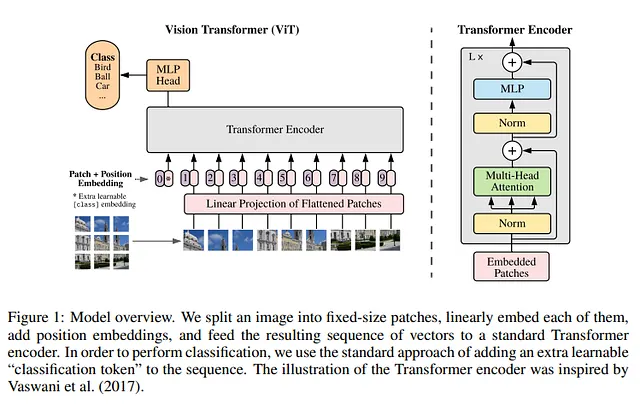
短時間で、畳み込みニューラルネットワークによるコンピュータビジョンの支配は徐々に崩れています。ビジョン・トランスフォーマーは、これまで畳み込みニューラルネットワークが支配していたImageNetなどのベンチマークで優れた性能を発揮しています。
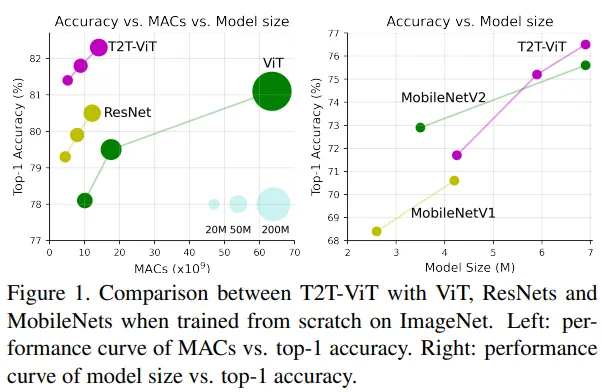
実際、十分なデータが提供されれば、ビジョン・トランスフォーマー(ViTs)はCNNよりも優れていることが示されています。また、いくつかの違いがあると同時に、いくつかの類似点もあります。
- ViTsとCNNの両方が、複雑で進歩的な表現を構築します。
- ただし、ViTsは背景に存在する情報をより活用でき、より堅牢であるようです。
ビジョン・トランスフォーマーが何を見るかの視覚的な旅
最大のモデルのいくつかは、世界をどう見ているのか?
pub.towardsai.net
さらに、トランスフォーマーのスケーリング能力も追加の利点です。これは、ViTsの競争優位性であり、彼らを人気のある選択肢にしました。
実際、数百万のパラメータを持つCNNや数十億のパラメータに達するViTが見られるようになりました。 Googleは昨年、ViTを20Bパラメータにスケーリングアップする方法を示し、将来的にはさらに大きなモデルが登場する可能性があります。
なぜ大きな言語モデルと小さなビジョン変換器が必要なのか?
Google ViT-22が新しい大規模トランスフォーマーの道を開き、コンピュータービジョンを革新する
towardsdatascience.com
ビジョン変換器の限界
変換器をネイティブに適応させたとしても、コストがかかります。ViTはパラメータを効率的に使用していません。これは、同じ空間分解能と同じネットワーク内のチャネル数を使用していることに起因します。
CNNには、初期の成功を決定するための2つの側面がありました(ともに人間の皮質に着想を得ました):
- レイヤーの階層を上げるにつれて、空間分解能を低下させること。
- 異なる「チャネル」の数を増やし、それぞれのチャネルがますます特化するようにすること。
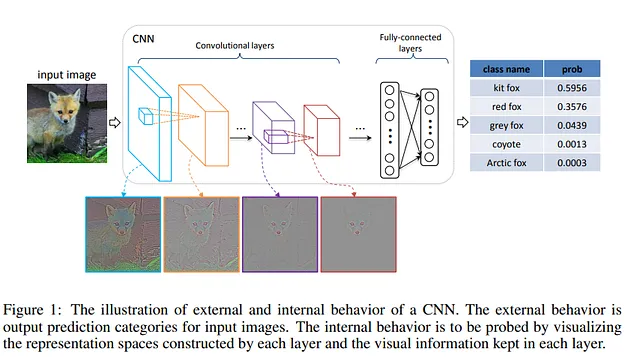
一方、変換器には、相互要素関係をモデル化するために使用されるアテンション操作と、要素間関係をモデル化するために使用される完全接続層の2つの主要な操作が発生するシーケンスがあります。これにより、汎化が可能になります。
- アテンション操作
- 完全接続層
これは実際には以前にも指摘されており、変換器は単語に適用されるように設計されており、画像には適用されていません。テキストと画像は異なる2つのモードです。その違いの1つは、単語はスケールが変化しないのに対して、画像は変化します。これは、オブジェクト検出でスケールが変化する要素に対してアテンションを与える必要がある場合に矛盾します。
また、画像のピクセル解像度は、テキストのパッセージ内の単語の解像度よりも高くなります。アテンションは二次コストを持つため、高解像度の画像を変換器で使用すると、高い計算コストがかかります。
以前の研究では、階層的な特徴マップを使用してこの問題を解決しようとしました。たとえば、Swin Transformerは、小さなパッチから始めて、さまざまな近隣パッチを徐々に統合することで、階層的な表現を構築します。
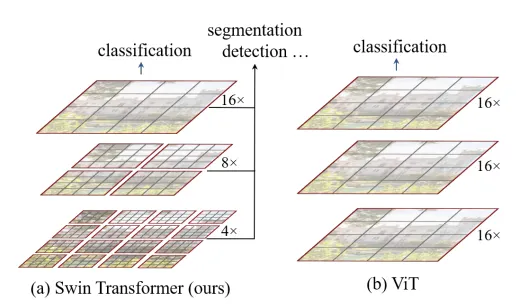
他の研究では、ViTでマルチチャネルを実装しようとしました。たとえば、MVITは、CNNのように、初期のチャネルを単純な低レベルの視覚情報に焦点を当て、より深いチャネルは複雑な高レベルの特徴に焦点を当てようとしました。

しかし、これらは問題を完全に解決しませんでした。時間の経過とともに、より複雑なモデルや専門的なモジュールが提案され、パフォーマンスがある程度改善されたものの、ViTはトレーニングが非常に遅くなってしまいました。
複雑な解決策なしに、これらのトランスフォーマーの制限を解決することはできるでしょうか?
空間関係を学ぶ方法

ViTはコンピュータビジョンのモデルとして登場しましたが、適応するためにますます複雑な修正が必要となっています。
複雑なソリューションなしに、これらのトランスフォーマの制限を解決できるでしょうか?
近年、モデルの合理化と速度向上のための努力がなされています。よく使われる方法の1つは、スパース化の導入です。コンピュータビジョンの場合、非常に成功したモデルの1つは、マスクされたオートエンコーダー(MAE)です。
その場合、パッチに分割した後、いくつかのパッチをマスクします。その後、デコーダーはマスクされたパッチから再構築する必要があります。その後、ViTエンコーダーはパッチの25%のみで動作します。これにより、計算とメモリの一部で広いエンコーダーをトレーニングすることができます。
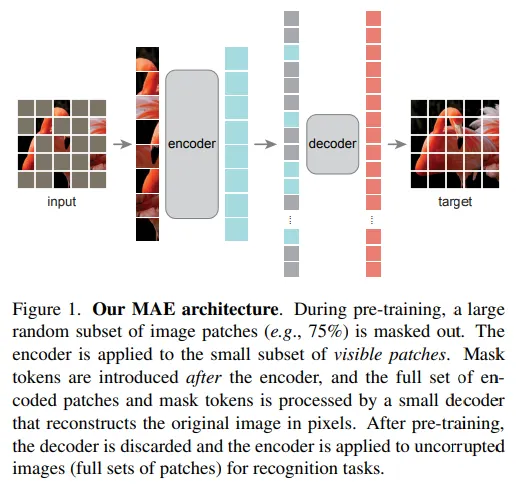
この方法は、空間的な推論を教えることができ、SwinやMvitと同等またはそれ以上の結果を達成することができることが示されています(ただし、計算量ははるかに複雑です)。
一方、スパース性のレジームがトレーニング効率を得られるということが真実であるとすれば、CNNの大きな利点の1つは階層的アプローチです。しかし、スパース性と矛盾します。
実際、以前にテストされたことがありますが、あまり成功していませんでした。
- 得られたモデルは遅すぎました(MaskFeatまたはSimMIM)。
- 変更により、モデルが不必要に複雑になり、精度が向上しなかった(UM-MAEまたはMCMAE)。
スパースで階層的で効率的なモデルを設計することは可能でしょうか?
METAによる新しい研究は、MAEトレーニングや他のトリックから出発して、過去に使用されてきた複雑な構造のすべてを必要とせずに、効率的かつ正確なViTを構築する方法を提供しています。
Hiera:鈴や笛なしの階層ビジョントランスフォーマー
現代の階層型ビジョントランスフォーマーは、監視された追求のためにいくつかのビジョン固有のコンポーネントが追加されています…
arxiv.org
Hiera:階層化、スパース、効率的なViT
モデル
基本的なアイデアは、視覚的なタスクで高い精度で階層的なViTをトレーニングするために、それを遅く、複雑にする要素の一連を使用する必要はないということです。著者によると、空間的なバイアスは、マスクオートエンコーダートレーニングを使用してモデルから学習することができます。
MAEでは、パッチが削除されるため、階層型モデルでは2Dグリッド(および空間関係)を再構築する問題があります。著者らは、カーネルがマスクユニット間で重ならないようにすることで解決します(プーリング中にマスクされたユニットとオーバーラップしないようにします)。

著者らは、MAEトレーニングを使用して既存の階層型ViTモデル、MViTv2から出発し、それを再利用することにしました。モデルはいくつかのViTブロックで構築されていますが、構造にはサイズの縮小があるため、プーリングアテンションを使用して達成されます。
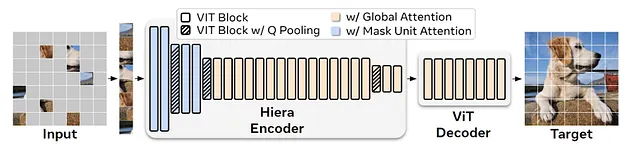
プーリングアテンション中、特徴はローカルに3×3畳み込みを使用して集約され、その後、自己アテンションが計算されます(これにより、KとVのサイズが縮小され、計算量が減少します)。このメカニズムは、ビデオを使用する場合に負荷がかかる可能性があります。そのため、著者らはそれをマスクユニットアテンションで置き換えました。
言い換えると、Hieraではプーリング中にカーネルがシフトして、マスクされた部分がプーリングされないようにします。つまり、トークンのグループごとに(マスクサイズの)ローカルな注意力が働くということです。

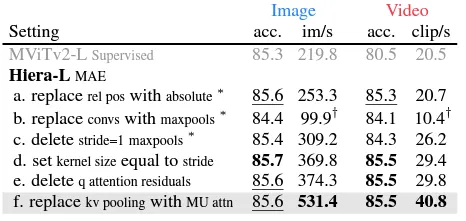
その後、MViTv2は複雑さを増す装備品を導入しましたが、著者らはそれらを非必須とみなして削除しました:
- 相対位置エンベディング。各ブロックの注意に位置エンベディングが加えられます。
- 最大プーリング層は、Hieraで使用するにはパディングが必要でした。
- 注意残差。Q(クエリ)と出力の間に残差接続があり、プーリング注意をより良く学習するためのものです。著者らはレイヤー数を減らしたため、これはもはや必要ではありません。
これらの変更の影響を示す著者らによると、単独で改善された性能をもたらし、正確性(acc.)と速度(秒間画像数)の両方で向上しています。
一般的に、モデルを単純化することで、HieraはMViTv2に比べて(画像とビデオの両方で)2.4倍速く、MAEのために実際により正確になり、他のモデルよりも正確です。
「Hieraは、開始時のMViTv2より画像で2.4倍、ビデオで5.1倍速く、MAEのために実際により正確です。」
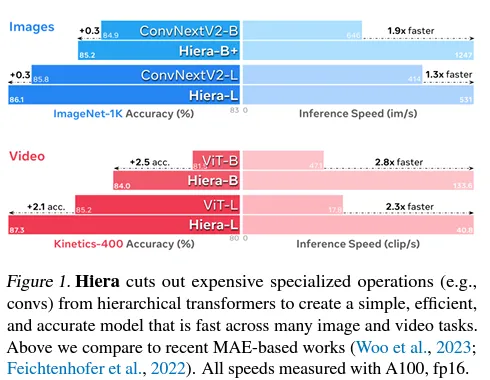
著者らは、このモデルが推論でだけでなく、トレーニングでもはるかに速くなることを指摘しています。

結果
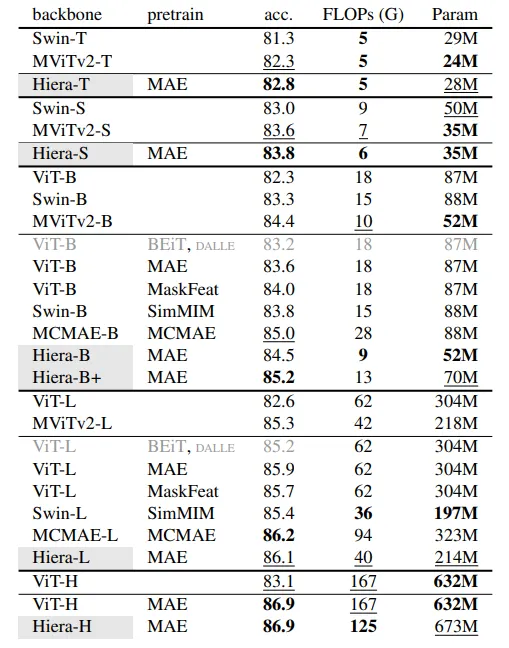
著者らは、実際には、パラメータの数が限られた基本モデルでも、Imagenet 1K(最も重要な画像分類データセットの1つ)で良い結果を出すことができることを示しています。
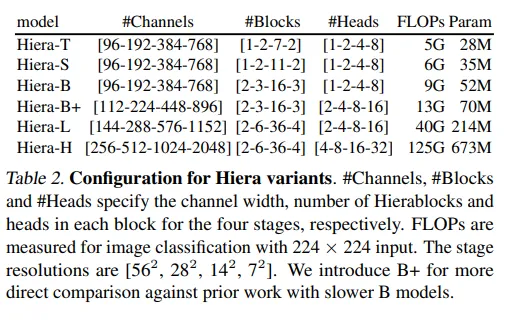
通常、低いパラメータレジメでは畳み込みベースのモデルが優勢でしたが、ここでは小さなモデルでも非常に良い結果が得られました。著者らにとって、これは空間バイアスがトレーニング中に学習でき、ViTsが小さなモデルでも畳み込みネットワークと競合できることを確認するものです。
大きなCNNモデルの運命は、転移学習に使用することでした。ResNetやVGGベースのモデルはImagenetでトレーニングされ、その後コミュニティによって多くのタスクに適応されました。したがって、著者らは、2つのデータセット(iNaturalistsとPlaces)を使用して、Hieraの転移学習能力をテストしました。
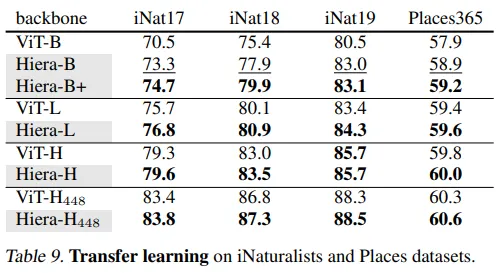
著者らは、2つのデータセットでモデルを微調整し、以前のViTsよりも優れたモデルであることを示しました。これは、彼らのモデルが他のデータセットでも使用できる可能性があることを示しています。
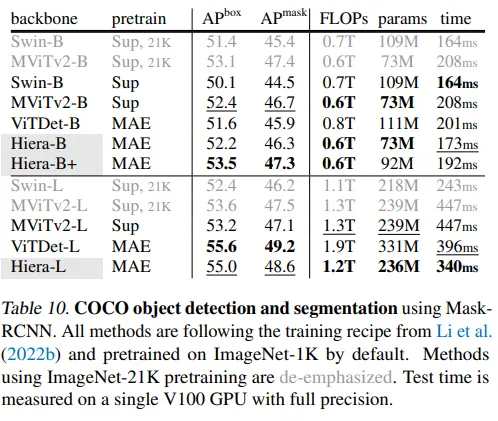
さらに、著者らは別の人気のあるデータセットCOCOを使用しています。iNaturalistsとPlacesは画像分類のためのデータセットでしたが、COCOはコンピューターサイエンスのもう2つの人気のあるタスク、画像セグメンテーションとオブジェクト検出のための最も広く使用されているデータセットの1つです。再度、モデルは強力なスケーリング挙動を示し(パラメータが増加するにつれて性能が向上する)、トレーニング中と推論中の両方でより高速です。
さらに、このモデルはビデオでテストされました。具体的には、2つのビデオ分類データセットでテストされました。Hieraは、より少ないパラメータでより優れたパフォーマンスを発揮することを示しています。モデルは推論でも速くなっています。著者は、このタイプのタスクにおいて最先端の性能を発揮することを示しています。
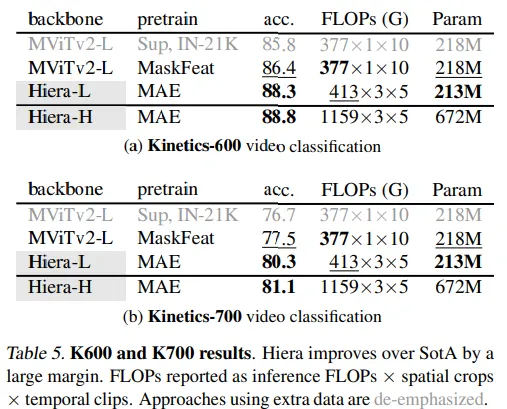
著者は、モデルがアクション検出などの他のビデオタスクにも使用できることを示しています。
最後に
この研究では、MAEの事前トレーニングを通じて空間バイアスをモデルに提供しながら、既存のモデルをすべて取り除くことでシンプルな階層ビジョン変換器を作成しました。(出典)
著者は、トランスフォーマーの性能を改善するために追加された多くの要素が実際には不必要であり、モデルの複雑さを増すことを示し、遅くすると述べています。
代わりに、MAEと階層構造を使用することで、画像やビデオの両方に対してより速く、より正確なViTが得られることを示しました。
この研究は、多くのタスクにおいて、コミュニティはまだ畳み込みベースのモデルを使用しているため重要です。ViTは非常に大きなモデルであり、高い計算コストがかかります。したがって、人々はしばしばResNetやVGGに基づくモデルを使用することを好む傾向があります。特に推論がより速くなり、より正確なViTは、ゲームチェンジャーになる可能性があります。
第二に、トレーニングの疎さを活用するというトレンドが見られます。これにより、パラメータが削減され、トレーニングと推論が加速される利点があります。一般的に、疎さのアイデアは、人工知能の他の分野でも見られ、活発な研究分野です。
もし興味を持たれた場合は:
私の他の記事を探すことができます。また、記事を公開するときに通知されるように購読することもできます。VoAGIメンバーになって、すべてのストーリーにアクセスすることもできます。また、LinkedInで私に連絡することもできます。
ここに私のGitHubリポジトリへのリンクがあります。そこでは、機械学習、人工知能、その他のリソースに関連するコードを収集する予定です。
GitHub — SalvatoreRa/tutorial: Tutorials on machine learning, artificial intelligence, data science…
Tutorials on machine learning, artificial intelligence, data science with math explanation and reusable code (in python…
github.com
また、以下の最近の記事に興味を持つかもしれません:
The imitation game: Taming the gap between open source and proprietary models
Can imitation models reach the performance of proprietary models like ChatGPT?
levelup.gitconnected.com
Scaling Isn’t Everything: How Bigger Models Fail Harder
Are Large Language Models really understanding programming languages?
salvatore-raieli.medium.com
META’S LIMA: Maria Kondo’s way for LLMs training
Less and tidy data to create a model capable to rival ChatGPT
levelup.gitconnected.com
AIは面白いですか?多少、かもしれません
AIがまだユーモアに苦戦している理由と、なぜこれが重要なステップなのか
levelup.gitconnected.com
参考文献
この記事を書く際に参照した主要な文献のリストです。最初の記事のみが引用されています。
- Chaitanya Ryali et al, 2023, Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles, link
- Peng Gao et al, 2022, MCMAE: Masked Convolution Meets Masked Autoencoders, link
- Xiang Li et al, 2022, Uniform Masking: Enabling MAE Pre-training for Pyramid-based Vision Transformers with Locality, link
- Zhenda Xie et al, 2022, SimMIM: A Simple Framework for Masked Image Modeling, link
- Ze Liu et al, 2021, Swin Transformer: Hierarchical Vision Transformer using Shifted Windows, link
- Haoqi Fan et al, 2021, Multiscale Vision Transformers, link
- Kaiming He et al, 2021, Masked Autoencoders Are Scalable Vision Learners, link
- Chen Wei et al, 2021, Masked Feature Prediction for Self-Supervised Visual Pre-Training, link
- Alexey Dosovitskiy et al, 2020, An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale, link
- Ashish Vaswani et al, 2017, Attention Is All You Need. link
- Kaiming He et al, 2015, Deep Residual Learning for Image Recognition, link
- Wei Yu et al, 2014, Visualizing and Comparing Convolutional Neural Networks. link
- Karen Simonyan et al, 2014, Very Deep Convolutional Networks for Large-Scale Image Recognition, link
- Why Do We Have Huge Language Models and Small Vision Transformers?, TDS, link
- A Visual Journey in What Vision-Transformers See, TowardsAI, link
- Vision Transformer, paperswithcode, link
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
