データサイエンスプロジェクトでのハードコーディングをやめましょう – 代わりに設定ファイルを使用しましょう
Stop hardcoding in data science projects - instead, use configuration files.
問題
データサイエンスプロジェクトでは、ファイル名、選択された特徴、トレインテスト分割比率、モデルのハイパーパラメータなど、特定の値が頻繁に変更される傾向があります。

仮説検証やデモ目的のアドホックなコードを書く場合はこれらの値をハードコードすることは問題ありません。しかし、コードベースやチームが拡大するにつれて、ハードコーディングを避けることが重要になります。なぜなら、ハードコーディングによってさまざまな問題が生じる可能性があるためです:
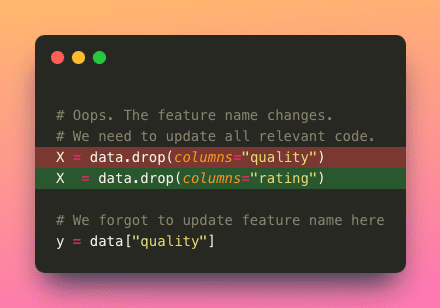
- 保守性:値がコードベース全体に散在している場合、一貫して更新することがより困難になります。これにより、値を更新する必要がある場合にエラーや不一致が生じる可能性があります。
- このAI論文は、自律走行車のデータセットを対象とし、コンピュータビジョンモデルのトレーニングの匿名化の影響を研究しています
- Btech卒業後に何をすべきですか?
- MetaのAIが参照メロディに基づいて音楽を生成する方法
- 再利用性:値をハードコードすると、コードを異なるシナリオに再利用することが制限されます。

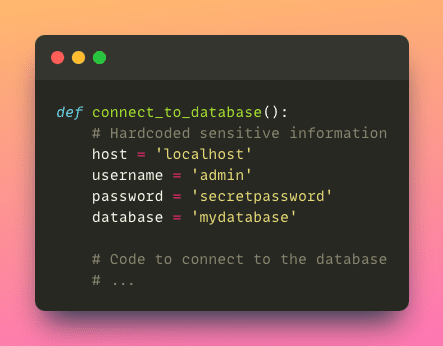
- セキュリティ上の懸念:パスワードやAPIキーなどの機密情報をコードに直接ハードコーディングすることはセキュリティ上のリスクとなります。コードが共有されたり公開された場合、不正アクセスやデータ漏洩につながる可能性があります。
- テストとデバッグ:ハードコーディングされた値は、テストとデバッグをより困難にする可能性があります。値がコードにハードコーディングされている場合、異なるシナリオをシミュレートしたり、効果的にエッジケースをテストすることが困難になります。

解決策 – 設定ファイル
設定ファイルによって、以下の利点が提供されるため、これらの問題を解決できます:
- コードからの設定の分離:設定ファイルにより、パラメータをコードから別個に保存できるため、コードの保守性と可読性が向上します。
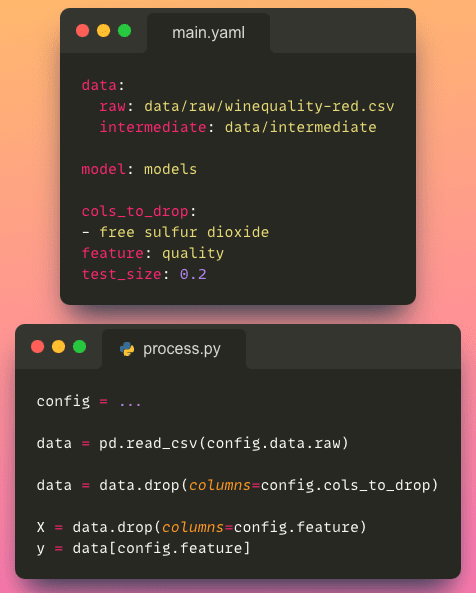
- 柔軟性と変更可能性:設定ファイルを使用すると、コード自体を変更せずにプロジェクトの構成を簡単に変更できます。この柔軟性により、素早い実験、パラメータの調整、プロジェクトの異なるシナリオや環境への適応が可能になります。
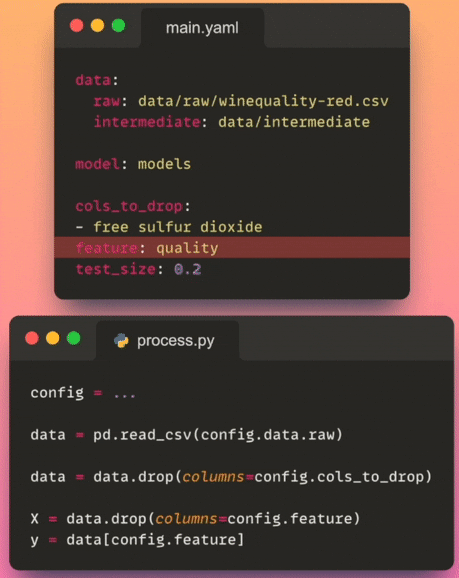
- バージョン管理:設定ファイルをバージョン管理に保存することで、時間の経過に伴う構成の変更を追跡できます。これにより、プロジェクトの構成の履歴記録を維持し、チームメンバー間の協力を促進できます。

- デプロイと製品化:データサイエンスプロジェクトをプロダクション環境に展開する場合、設定ファイルにより、コードの変更なしでプロダクション環境に固有の設定を簡単にカスタマイズできます。この設定のコードからの分離により、展開プロセスが簡素化されます。
Hydra の紹介
設定ファイルを作成するために使用できる数多くの Python ライブラリの中で、Hydra は私が好む設定管理ツールの1つです。その理由は、以下の印象的な機能を備えているためです:
- 便利なパラメータアクセス
- コマンドラインでの設定オーバーライド
- 複数のソースからの構成の合成
- 異なる構成で複数のジョブの実行
これらの機能について詳しく見ていきましょう。
この記事のソースコードを自由にプレイおよびフォークしてください:
GitHub で表示する
便利なパラメータアクセス
すべての設定ファイルが conf フォルダーに保存され、すべての Python スクリプトが src フォルダーに保存されているとします。
.
├── conf/
│ └── main.yaml
└── src/
├── __init__.py
├── process.py
└── train_model.pyそして、main.yamlファイルは以下のようになります:

Pythonスクリプト内で設定ファイルにアクセスするには、Python関数に単一のデコレータを適用するだけです。
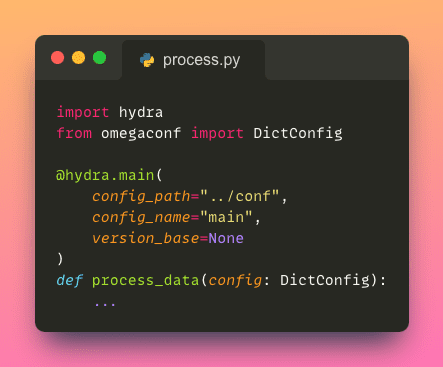
構成ファイルから特定のパラメータにアクセスするには、ドット表記(.e.g.、config.process.cols_to_drop)を使用することができます。これは、ブラケットを使用するよりもクリーンで直感的な方法です(e.g.、config['process']['cols_to_drop'])。
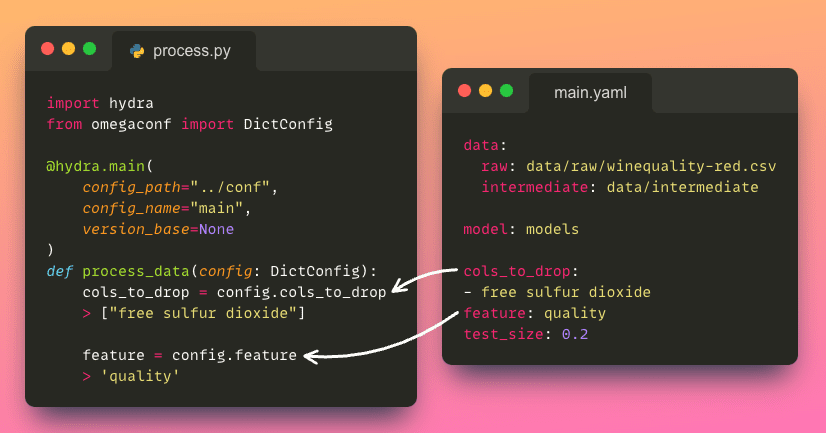
この直感的なアプローチにより、簡単に必要なパラメータを取得できます。
コマンドラインでの構成の上書き
異なるtest_sizeを試行錯誤しているとしましょう。何度も構成ファイルを開いてtest_size値を変更するのは時間がかかります。

幸い、Hydraを使えば、コマンドラインから直接構成を上書きすることができます。この柔軟性により、基礎となる構成ファイルを変更することなく、素早く調整や微調整ができます。

複数のソースからの構成の合成
データ処理方法とモデルハイパーパラメータのさまざまな組み合わせで実験したいとしましょう。新しい実験を実行するたびに構成ファイルを手動で編集することもできますが、これは時間がかかります。

Hydraは、構成グループを使用して複数のソースからの構成の合成を可能にします。データ処理のための構成グループを作成するには、各処理方法のファイルを保持するためにprocessというディレクトリを作成します:
.
└── conf/
├── process/
│ ├── process1.yaml
│ └── process2.yaml
└── main.yaml
デフォルトでprocess1.yamlファイルを使用する場合は、それをHydraのデフォルトリストに追加します。

トレーニングハイパーパラメータのための構成グループを作成するには、同じ手順に従います:
.
└── conf/
├── process/
│ ├── process1.yaml
│ └── process2.yaml
├── train/
│ ├── train1.yaml
│ └── train2.yaml
└── main.yaml
train1をデフォルトの構成ファイルに設定します:

これで、アプリケーションを実行すると、デフォルトでprocess1.yamlファイルとmodel1.yamlファイルのパラメータが使用されます:

この機能は、異なる構成ファイルをシームレスに組み合わせる必要がある場合に特に役立ちます。
マルチラン
複数の処理方法で実験を実施したい場合、各構成を1つずつ適用することは時間がかかる場合があります。

幸運にも、Hydraを使用すると、同じアプリケーションを異なる構成で同時に実行できます。
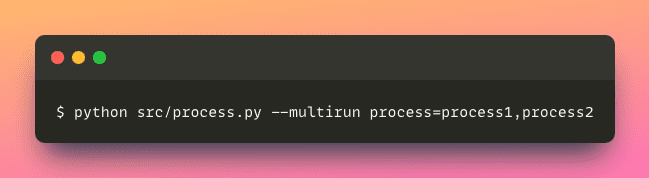
このアプローチにより、さまざまなパラメーターでアプリケーションを実行するプロセスが効率化され、貴重な時間と労力が節約されます。
結論
おめでとうございます!構成ファイルの使用の重要性と、Hydraを使用して構成ファイルを作成する方法について学びました。この記事が、自分自身の構成ファイルを作成するために必要な知識を提供できることを願っています。
Khuyen Tranは、多くのデータサイエンスの記事を書き、コードと記事の有用なコレクションを作成しています。Khuyneは2022年5月以降、ベイエリアでの機械学習エンジニアの役割、データサイエンティストの役割、またはデベロッパーアドボケイトの役割を探しており、彼女のスキルを持つ人を探している場合は、ぜひ連絡してください。
オリジナルの記事。許可を得て再掲載。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Voxel51 は、コンピュータビジョンデータセット分析のための Python コードを生成するために GPT-3.5 の能力を活用する AI アシスタントである VoxelGPT をオープンソース化しました
- Netflix株の時系列分析(Pandasによる)
- データサイエンティストとは具体的に何をする人なのでしょうか?
- PatchTST 時系列予測における画期的な技術革新
- レトロなデータサイエンス:YOLOの最初のバージョンのテスト
- SeabornとMatplotlibを使用して美しい年齢分布グラフを作成する方法(アニメーションを含む)
- MIT-Pillar AI Collectiveが初めてのシードグラント受賞者を発表
