オープンソースのAmazon SageMaker Distributionで始めましょう
Start with Amazon SageMaker Distribution, which is open source.
データサイエンティストは、機械学習(ML)およびデータサイエンスのワークロードのための一貫した再現可能な環境が必要であり、依存関係を管理しセキュリティーを確保できるようにする必要があります。AWS Deep Learning Containersは、TensorFlow、PyTorch、MXNetなどの一般的なフレームワークでモデルのトレーニングとサービングのためのプレビルドDockerイメージを提供しています。この体験を改善するために、我々は2023 JupyterConでSageMakerオープンソースディストリビューションのパブリックベータ版を発表しました。これにより、様々なレベルのML開発者に対して統一されたエンドツーエンドのML体験が提供されます。開発者は、実験のために異なるフレームワークコンテナを切り替えたり、ローカルのJupyterLab環境やSageMakerノートブックからSageMaker上のプロダクションジョブに移行する必要がありません。オープンソースのSageMakerディストリビューションは、TensorFlow、PyTorch、Scikit-learn、Pandas、Matplotlibなどのデータサイエンス、ML、および可視化のための最も一般的なパッケージとライブラリをサポートしています。Amazon ECR Public Galleryからコンテナを使用することができます。
本記事では、SageMakerオープンソースディストリビューションを使用して、ローカル環境で迅速に実験を行い、SageMaker上のジョブに簡単に昇格できる方法を紹介します。
ソリューションの概要
この例では、PyTorchを使用して画像分類モデルのトレーニングを行います。公開されているPyTorchのKMNISTデータセットを使用して、ニューラルネットワークモデルのトレーニングを行い、モデルのパフォーマンスをテストし、最後にトレーニングおよびテストロスを出力します。この例の完全なノートブックは、SageMaker Studio Lab examples repositoryで入手できます。ローカルラップトップ上でオープンソースディストリビューションを使用して実験を開始し、より大きなインスタンスを使用するためにAmazon SageMaker Studioに移動し、最後にノートブックジョブとしてスケジュールします。
前提条件
以下が必要です:
- Amazon SageMakerでTritonを使用してMLモデルをホストする:ONNXモデル
- Amazon SageMakerのHugging Face推定器とモデルパラレルライブラリを使用してGPT-Jを微調整する
- Amazon SageMakerを使用してOpenChatkitモデルを利用したカスタムチャットボットアプリケーションを構築する
- Dockerがインストールされていること
- 管理者権限を持つ有効なAWSアカウント
- AWS Command Line Interface(AWS CLI)およびDockerがインストールされた環境
- 既存のSageMakerドメイン。ドメインを作成するには、Onboard to Amazon SageMaker Domainを参照してください。
ローカル環境のセットアップ
ローカルラップトップ上でオープンソースディストリビューションを直接使用できます。JupyterLabを開始するには、ターミナルで以下のコマンドを実行してください:
export ECR_IMAGE_ID='public.ecr.aws/sagemaker/sagemaker-distribution:latest-cpu'
docker run -it \
-p 8888:8888 \
--user `id -u`:`id -g` \
-v `pwd`/sample-notebooks:/home/sagemaker-user/sample-notebooks \
$ECR_IMAGE_ID jupyter-lab --no-browser --ip=0.0.0.0ECR_IMAGE_IDをAmazon ECR Public Galleryの利用可能なイメージタグのいずれかに置き換えるか、GPUをサポートするマシンを使用している場合はlatest-gpuタグを選択できます。
このコマンドを実行すると、JupyterLabが開始され、ターミナルにURLが提供されます。たとえば、http://127.0.0.1:8888/lab?token= <token>のようなものです。リンクをコピーして、お好みのブラウザに入力してJupyterLabを開始してください。
Studioのセットアップ
Studioは、開発者やデータサイエンティストがMLモデルをビルド、トレーニング、デプロイ、監視することができるエンドツーエンドの統合開発環境(IDE)です。Studioには、Data Science、TensorFlow、PyTorch、Sparkなどの一般的なフレームワークやパッケージを備えた最初のパーティーのイメージのリストが用意されており、データサイエンティストは、単にフレームワークとコンピュータの種類を選択すればMLを開始できます。
今すぐ、Studioのbring your own image機能を使用してSageMakerオープンソースディストリビューションをStudioで使用できます。SageMakerドメインにオープンソースディストリビューションを追加するには、以下の手順を完了してください:
-
ターミナルで以下のコマンドを実行して、オープンソースディストリビューションをアカウントのAmazon Elastic Container Registry(Amazon ECR)リポジトリに追加します:
# 要件に応じてlatest-cpuまたはlatest-gpuタグを使用する export ECR_GALLERY_IMAGE_ID='sagemaker-distribution:latest-cpu' export SAGEMAKER_IMAGE_NAME='sagemaker-distribution' export SAGEMAKER_STUDIO_DOMAIN_ID='d-xxxx' export SAGEMAKER_STUDIO_IAM_ROLE_ARN='<studio-default-execution-role-arn>' docker pull public.ecr.aws/sagemaker/$ECR_GALLERY_IMAGE_ID export ECR_PRIVATE_REPOSITORY_NAME='sm-distribution' export ECR_IMAGE_TAG='sagemaker-distribution-cpu' export AWS_ACCOUNT_ID='0123456789' export AWS_ECR_REPOSITORY_REGION='us-east-1' # リポジトリを作成する aws --region ${AWS_ECR_REPOSITORY_REGION} ecr create-repository --repository-name $ECR_PRIVATE_REPOSITORY_NAME aws --region ${AWS_ECR_REPOSITORY_REGION} ecr get-login-password | docker login --username AWS --password-stdin ${AWS_ACCOUNT_ID}.dkr.ecr.${AWS_ECR_REPOSITORY_REGION}.amazonaws.com export ECR_IMAGE_URI=$AWS_ACCOUNT_ID.dkr.ecr.$AWS_ECR_REPOSITORY_REGION.amazonaws.com/$ECR_PRIVATE_REPOSITORY_NAME:$ECR_IMAGE_TAG # タグ docker tag public.ecr.aws/sagemaker/$ECR_GALLERY_IMAGE_ID $ECR_IMAGE_URI # イメージをプライベートリポジトリにプッシュする docker push $ECR_IMAGE_URI -
SageMakerイメージを作成し、Studioドメインにイメージを添付します:
# SageMakerイメージを作成する aws sagemaker create-image \ --image-name $SAGEMAKER_IMAGE_NAME \ --role-arn $SAGEMAKER_STUDIO_IAM_ROLE_ARN # SageMakerイメージバージョンを作成します。 aws sagemaker create-image-version \ --image-name $SAGEMAKER_IMAGE_NAME \ --base-image $ECR_IMAGE_URI # オプションで、イメージバージョンを説明して作成が成功したことを確認する aws sagemaker describe-image-version \ --image-name $SAGEMAKER_IMAGE_NAME \ --
ノートブックのダウンロード
GitHubリポジトリからサンプルノートブックをローカルにダウンロードします。
ノートブックを選択したIDEで開き、ノートブックの最初に
torchsummaryをインストールするセルを追加してください。torchsummaryパッケージは配布の一部ではないため、ノートブックにこれをインストールすることで、ノートブックがエンドツーエンドで実行されることが保証されます。 環境と依存関係を管理するには、condaまたはmicromambaを使用することをお勧めします。 ノートブックに次のセルを追加して、ノートブックを保存します。%pip install torchsummaryローカルノートブックでの実験
次に、アップロードアイコンを選択して起動したJupyterLab UIにノートブックをアップロードします。
アップロードが完了したら、
cv-kmnist.ipynbノートブックを起動してください。torch、matplotlib、ipywidgetsなどの依存関係をインストールする必要はなく、すぐにセルを実行できます。前の手順に従った場合、配布をローカルからラップトップで使用できることがわかります。 次のステップでは、Studioで同じ配布を使用して、Studioの機能を活用します。
実験をStudioに移行する(オプション)
オプションで、実験をStudioに移行しましょう。 Studioの利点の1つは、基礎となるコンピューティングリソースが完全に弾力的であるため、利用可能なリソースを簡単にアップまたはダウンでき、変更は自動的にバックグラウンドで行われ、作業が中断されることなく行われることです。 以前に実行した同じノートブックを、より大きなデータセットとコンピュートインスタンスで実行したい場合は、Studioに移行できます。
アップロードアイコンを選択して、以前に起動したStudio UIに移動して、ノートブックをアップロードしてください。
ノートブックを起動すると、イメージとインスタンスタイプを選択するように促されます。 カーネルランチャーで、
sagemaker-distributionをイメージとして、ml.t3.mediumインスタンスを選択し、選択してください。
これで、ローカル開発環境のノートブックからStudioノートブックに変更する必要はなく、ノートブックをエンドツーエンドで実行できます!
ノートブックをジョブとしてスケジュールする
実験が終了したら、SageMakerにはトレーニングジョブやSageMakerパイプラインなど、ノートブックをプロダクション化するための複数のオプションが用意されています。 そのようなオプションの1つは、SageMakerノートブックジョブを使用して、ノンインタラクティブでスケジュールされたノートブックジョブとして直接ノートブック自体を実行することです。 たとえば、定期的にモデルを再トレーニングしたり、定期的に受信したデータの推論を取得してステークホルダーが消費するレポートを生成したりする必要がある場合があります。
Studioから、ノートブックジョブアイコンを選択してノートブックジョブを起動してください。 ノートブックジョブの拡張機能をローカルでインストールしている場合は、ノートブックジョブを直接ラップトップからスケジュールすることもできます。 ノートブックジョブ拡張機能をローカルでセットアップするには、インストールガイドを参照してください。
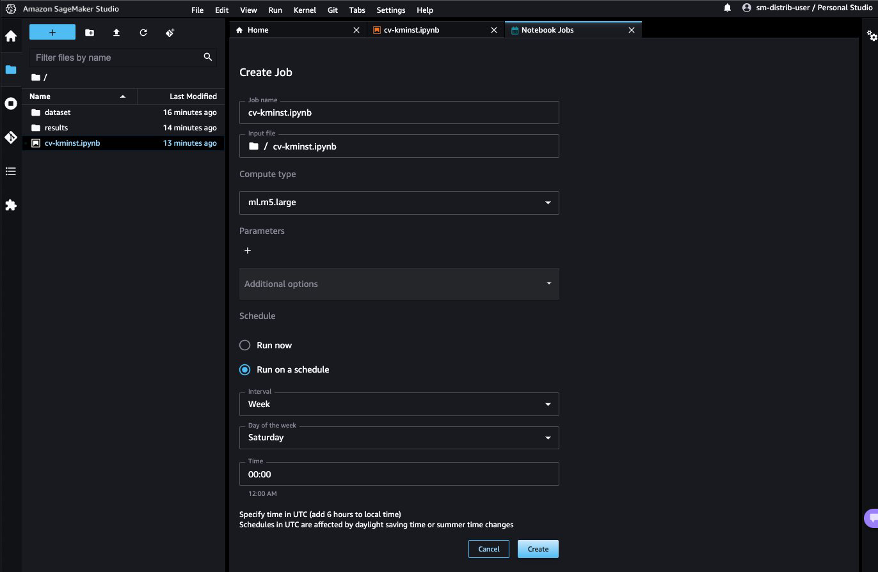
ノートブックジョブは、オープンソースの配布のECRイメージURIを自動的に使用するため、ノートブックジョブを直接スケジュールできます。

スケジュールで実行を選択し、スケジュールを選択して、例えば毎週土曜日を選択しCreateを選択します。すぐに結果を確認したい場合は、Run nowを選択することもできます。
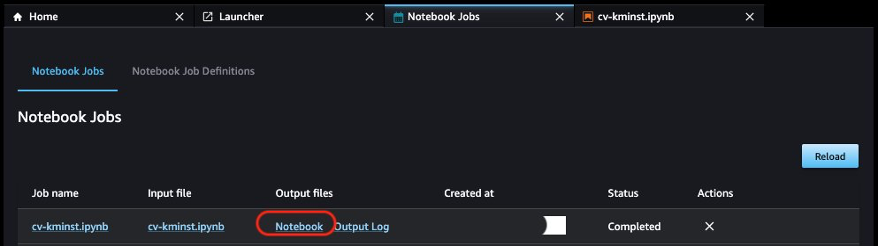
最初のノートブックジョブが完了したら、Output filesの下にあるNotebookを選択して、Studio UIからノートブックの出力を直接表示することができます。
その他の考慮事項
公開されているECRイメージを直接MLワークロードで使用することに加えて、オープンソースディストリビューションには次の利点があります。
- イメージをビルドするために使用されるDockerfileは、開発者が自分自身のイメージを探索およびビルドするために公開されています。また、このイメージをベースイメージとして継承し、カスタムライブラリをインストールして再現可能な環境を作成することもできます。
- Dockerに慣れていない場合は、JupyterLab環境でConda環境を使用することを好む場合は、公開されているバージョンごとに
env.outファイルが用意されています。ファイルの中にある指示に従って、同じ環境を模倣した自分自身のConda環境を作成することができます。例えば、CPU環境ファイルcpu.env.outを参照してください。 - GPUバージョンのイメージを使用すると、ディープラーニングや画像処理などのGPU互換のワークロードを実行できます。
クリーンアップ
リソースをクリーンアップするには、以下の手順を完了します。
- ノートブックをスケジュール実行に設定した場合は、Notebook Job Definitionsタブでスケジュールを一時停止または削除して、将来のジョブの料金を支払わないようにします。

- 使用しないコンピュート使用料金を支払わないように、すべてのStudioアプリをシャットダウンします。手順については、「Shut down and Update Studio Apps」を参照してください。
- オプションで、作成した場合はStudioドメインを削除します。
まとめ
MLライフサイクルのさまざまな段階で再現可能な環境を維持することは、データサイエンティストや開発者にとって最大の課題の1つです。 SageMakerオープンソースディストリビューションでは、最も一般的なMLフレームワークやパッケージの相互互換性のあるバージョンを提供するイメージを提供しています。ディストリビューションもオープンソースであり、パッケージとビルドプロセスに透明性があり、カスタマイズが容易になっています。
この記事では、ローカル環境、Studio、およびトレーニングジョブのコンテナとしてディストリビューションを使用する方法を紹介しました。この機能は現在パブリックベータ版です。お試しいただき、フィードバックや問題を公開GitHubリポジトリで共有することをお勧めします。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






