StackLLaMA:RLHFを使用してLLaMAをトレーニングするための実践ガイド
'StackLLaMA A Practical Guide to Training LLaMA using RLHF'
ChatGPT、GPT-4、Claudeなどのモデルは、Reinforcement Learning from Human Feedback(RLHF)と呼ばれる手法を使用して、予想される振る舞いにより適合するように微調整された強力な言語モデルです。
このブログ記事では、LlaMaモデルをStack Exchangeの質問に回答するためにRLHFを使用してトレーニングするために関与するすべてのステップを以下の組み合わせで示します:
- 教師あり微調整(SFT)
- 報酬/選好モデリング(RM)
- 人間のフィードバックからの強化学習(RLHF)
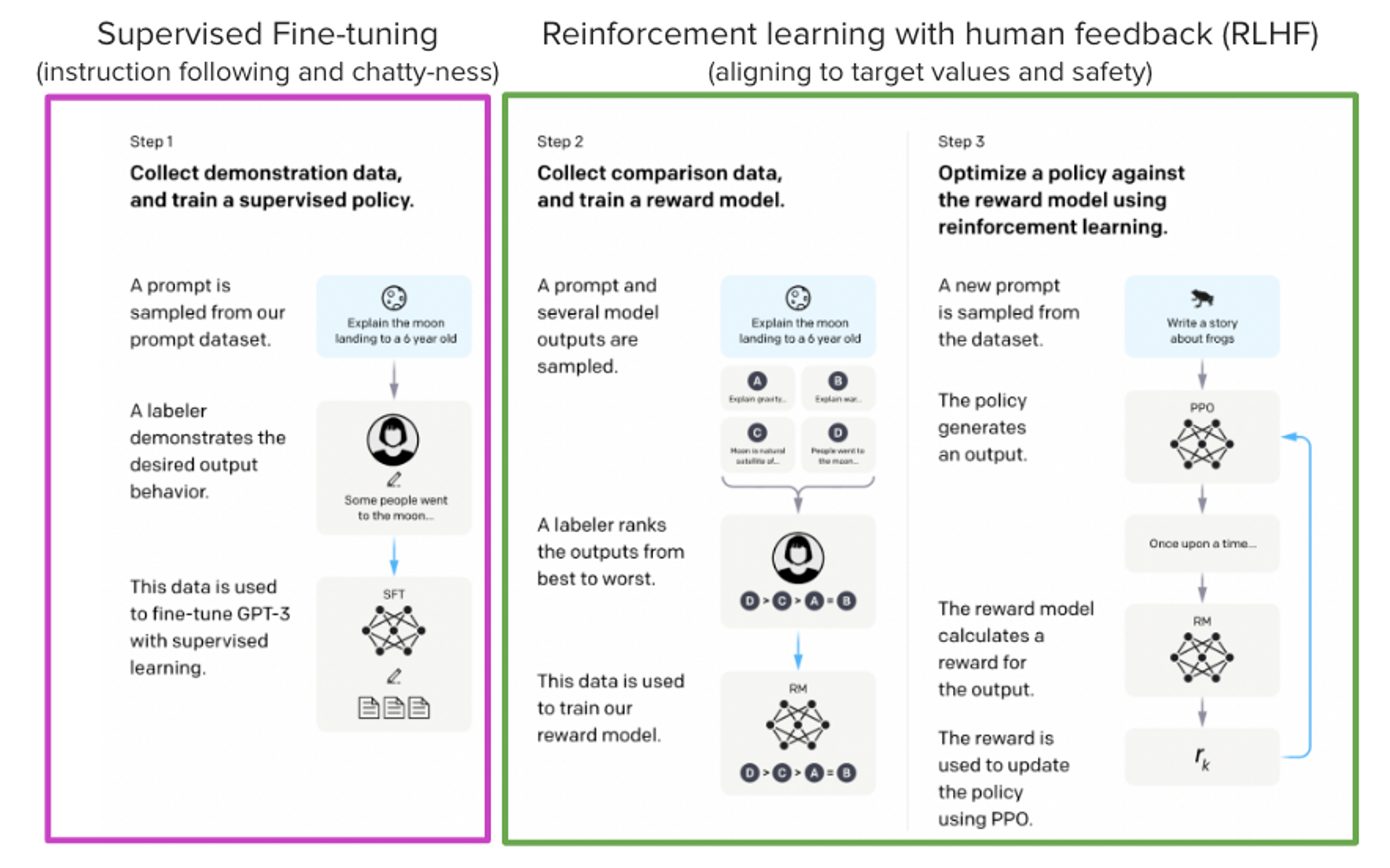 From InstructGPT paper: Ouyang, Long, et al. “Training language models to follow instructions with human feedback.” arXiv preprint arXiv:2203.02155 (2022).
From InstructGPT paper: Ouyang, Long, et al. “Training language models to follow instructions with human feedback.” arXiv preprint arXiv:2203.02155 (2022).
これらの手法を組み合わせることで、StackLLaMAモデルをリリースします。このモデルは🤗 Hub(オリジナルのLLaMAモデルに関するMetaのLLaMAリリースを参照)で利用可能であり、完全なトレーニングパイプラインはHugging Face TRLライブラリの一部として利用できます。モデルの機能をお試しいただくために、以下のデモをお試しください!
LLaMAモデル
RLHFを行う際には、能力のあるモデルから始めることが重要です。RLHFステップは、モデルを望むように相互作用し、期待する応答ができるように調整するための微調整ステップに過ぎません。そのため、最近導入された高性能なLLaMAモデルを使用することにしました。LLaMAモデルは、Meta AIによって開発された最新の大規模言語モデルで、7Bから65Bのパラメーター数と、1Tから1.4Tトークンの間でトレーニングされています。これにより、非常に能力を持つモデルとなっています。以下の手順では、ベースとして7Bモデルを使用しています!モデルにアクセスするには、Meta AIのフォームを使用してください。
Stack Exchangeデータセット
人間のフィードバックを収集することは、複雑で費用のかかる作業です。この例のプロセスをブートストラップするために、有用なモデルを構築しながら、StackExchangeデータセットを利用します。このデータセットには、StackExchangeプラットフォーム(コードの場合はStackOverflowなど)からの質問とそれに対応する回答が含まれています。回答は、アップボートの数と受け入れられた回答のラベルと共に提供されるため、このユースケースに適しています。
私たちは、Askell et al. 2021で説明されている手法に従って、各回答にスコアを割り当てます:
スコア = log2(1 + アップボート数)を最も近い整数に四捨五入し、質問者が回答を受け入れた場合は+1(アップボート数が負の場合はスコアを-1とします)。
報酬モデルでは、後で説明するように、質問ごとに2つの回答が常に必要です。一部の質問には数十の回答があり、多くの可能なペアがあります。1つの質問あたり最大10の回答ペアをサンプリングし、質問ごとのデータポイントの数を制限しました。最後に、モデルの出力をより読みやすくするために、HTMLをMarkdownに変換してフォーマットを整えました。データセットおよび処理ノートブックはこちらでご覧いただけます。
効率的なトレーニング戦略
最も小さなLLaMAモデルのトレーニングには膨大なメモリが必要です。簡単な計算をしてみましょう:bf16では、各パラメーターに2バイト(fp32では4バイト)が使用され、Adamオプティマイザーでは8バイトが使用されます(詳細については、Transformersのパフォーマンスドキュメントを参照してください)。したがって、7Bパラメーターモデルはメモリに収まるだけで(2+8)* 7B = 70GBを使用し、注意スコアなどの中間値を計算する際にはさらに多くのメモリが必要になる可能性があります。そのため、単一の80GB A100でさえそのようなモデルをトレーニングすることはできません。より効率的な最適化手法や半精度トレーニングのようなトリックを使用して、メモリに少し余裕を持たせることはできますが、いずれメモリが不足します。
別のオプションとして、Parameter-Efficient Fine-Tuning(PEFT)の技術、例えばpeftライブラリを使用して、8ビットでロードされたモデルに対してLow-Rank Adaptation(LoRA)を行うことができます。
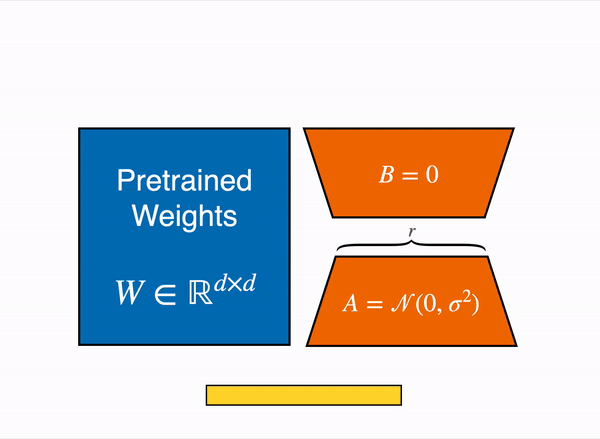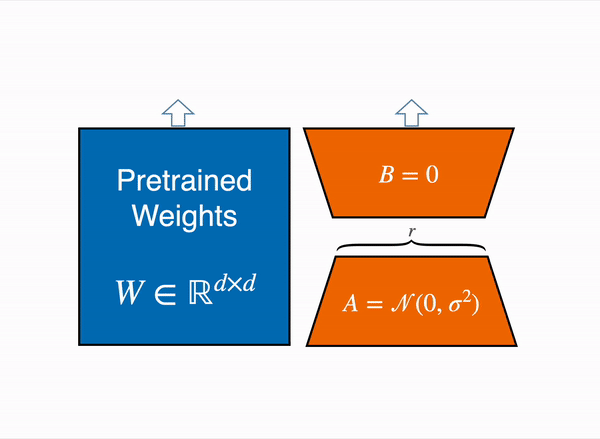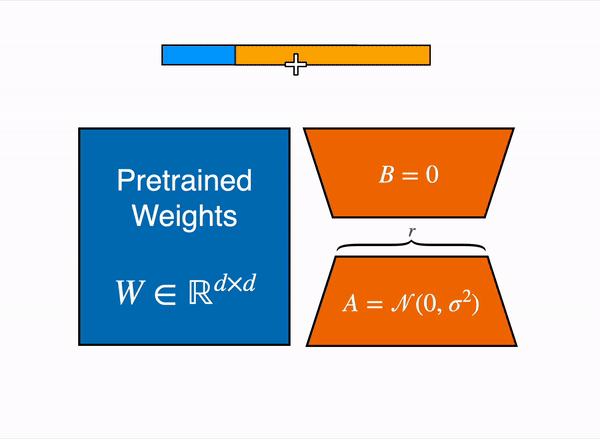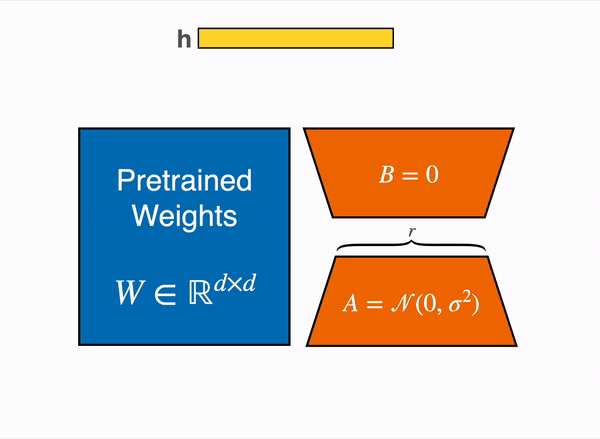 リニアレイヤーの低ランク適応:凍結されたレイヤー(青)の隣に追加のパラメーター(オレンジ)が追加され、結果のエンコードされた隠れ状態と凍結されたレイヤーの隠れ状態が加算されます。
リニアレイヤーの低ランク適応:凍結されたレイヤー(青)の隣に追加のパラメーター(オレンジ)が追加され、結果のエンコードされた隠れ状態と凍結されたレイヤーの隠れ状態が加算されます。
8ビットでモデルを読み込むと、メモリの使用量が大幅に削減されます。重みごとに1バイトのみが必要です(例:7B LlaMaはメモリでは7GBです)。元の重みを直接トレーニングする代わりに、LoRAは特定のレイヤー(通常はアテンションレイヤー)の上に小さなアダプターレイヤーを追加するため、トレーニング可能なパラメータの数が大幅に減少します。
このシナリオでは、約10億のパラメータごとに~1.2-1.4GB(バッチサイズとシーケンス長によって異なる)を割り当て、全体のファインチューニングセットアップを収めることが一般的です。上記の添付ブログ投稿に詳細が記載されていますが、これにより、低コストでより大きなモデル(NVIDIA A100 80GBで50-60Bスケールのモデルまで)をファインチューニングすることができます。
これらの技術により、コンシューマデバイスやGoogle Colabでの大規模モデルのファインチューニングが可能になりました。注目すべきデモには、facebook/opt-6.7b(float16で13GB)のファインチューニング、およびGoogle Colabでのopenai/whisper-large(15GBのGPU RAM)があります。peftの使用方法については、GitHubリポジトリまたは以前のブログ投稿(https://huggingface.co/blog/trl-peft)を参照してください。コンシューマハードウェアで20bパラメータモデルをトレーニングする方法について詳しく説明されています。
今では、非常に大きなモデルを単一のGPUに収めることができますが、トレーニングは依然として非常に遅い場合があります。このようなシナリオでは、最も単純な戦略はデータ並列処理です。同じトレーニングセットアップを別々のGPUに複製し、異なるバッチを各GPUに渡すことで、モデルの順方向/逆方向パスを並列化し、GPUの数にスケールさせることができます。
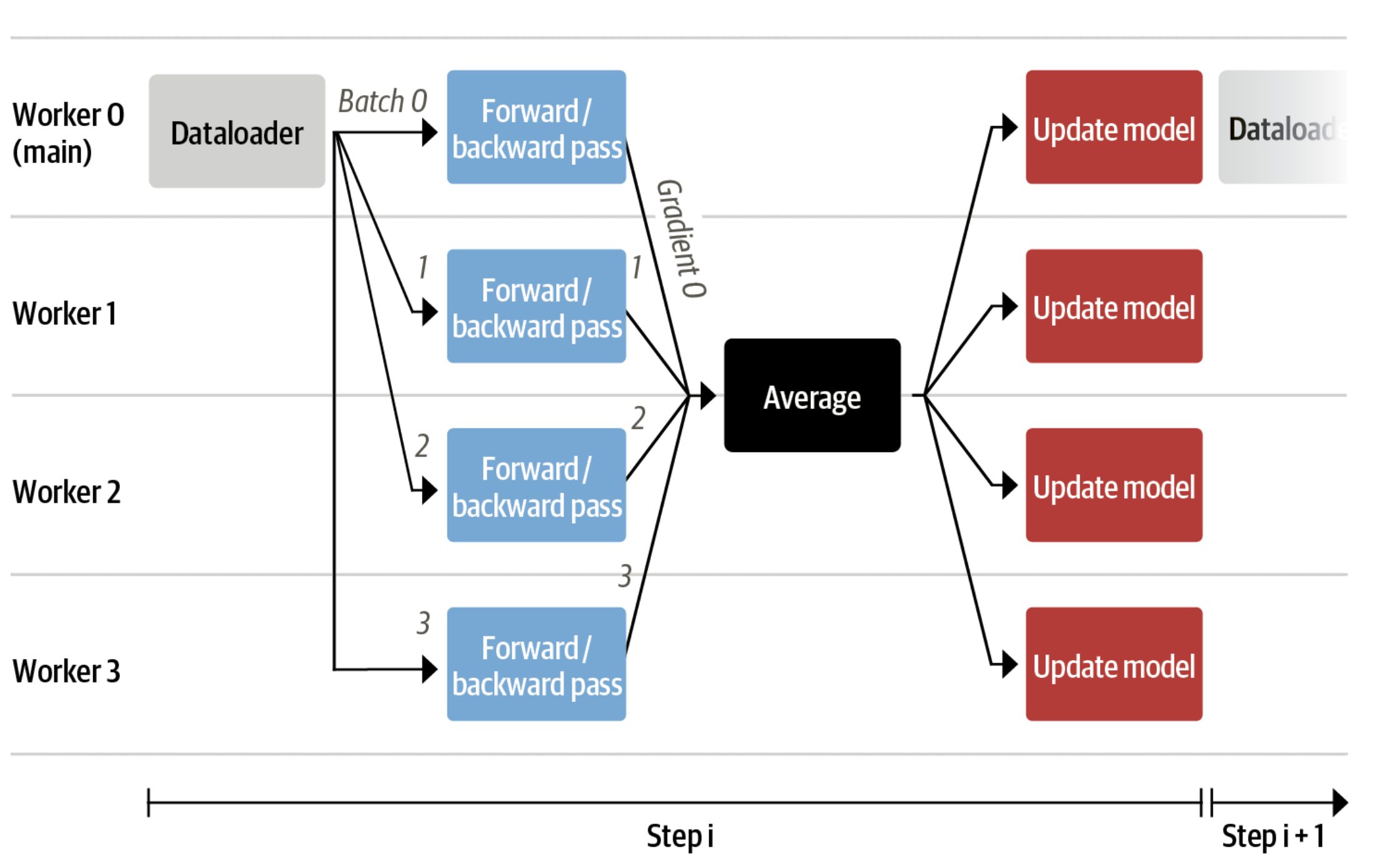
データ並列処理をサポートするtransformers.Trainerまたはaccelerateを使用します。これらの両方は、torchrunまたはaccelerate launchを使用してスクリプトを呼び出す際に引数を渡すだけで、コードの変更なしにデータ並列処理をサポートしています。以下は、accelerateとtorchrunを使用して単一のマシン上の8つのGPUでトレーニングスクリプトを実行する例です。
accelerate launch --multi_gpu --num_machines 1 --num_processes 8 my_accelerate_script.py
torchrun --nnodes 1 --nproc_per_node 8 my_torch_script.py教師付きファインチューニング
RLで報酬モデルをトレーニングし、モデルをチューニングする前に、興味のあるドメインでモデルが既に優れていると役立ちます。この場合、質問に答えることを目的としていますが、他のユースケースでは指示に従うことを望む場合もあります。この場合、指示のチューニングが良いアイデアです。これを実現するための最も簡単な方法は、ドメインまたはタスクのテキストで言語モデルを引き続き言語モデリング目的でトレーニングすることです。StackExchangeのデータセットは非常に大きいです(1000万以上の指示があります)、そのため、その一部を使用して言語モデルを簡単にトレーニングできます。
RLHFの前にモデルをファインチューニングすることに特別なことはありません。ここでは、事前トレーニングの因果言語モデリング目的を適用しているだけです。データを効率的に使用するために、パッキングと呼ばれる技術を使用します。バッチごとに1つのテキストを持ち、最長のテキストまたはモデルの最大コンテキストにパディングする代わりに、テキストをEOSトークンで区切り、コンテキストサイズのチャンクを切り出してパディングなしでバッチを埋めます。
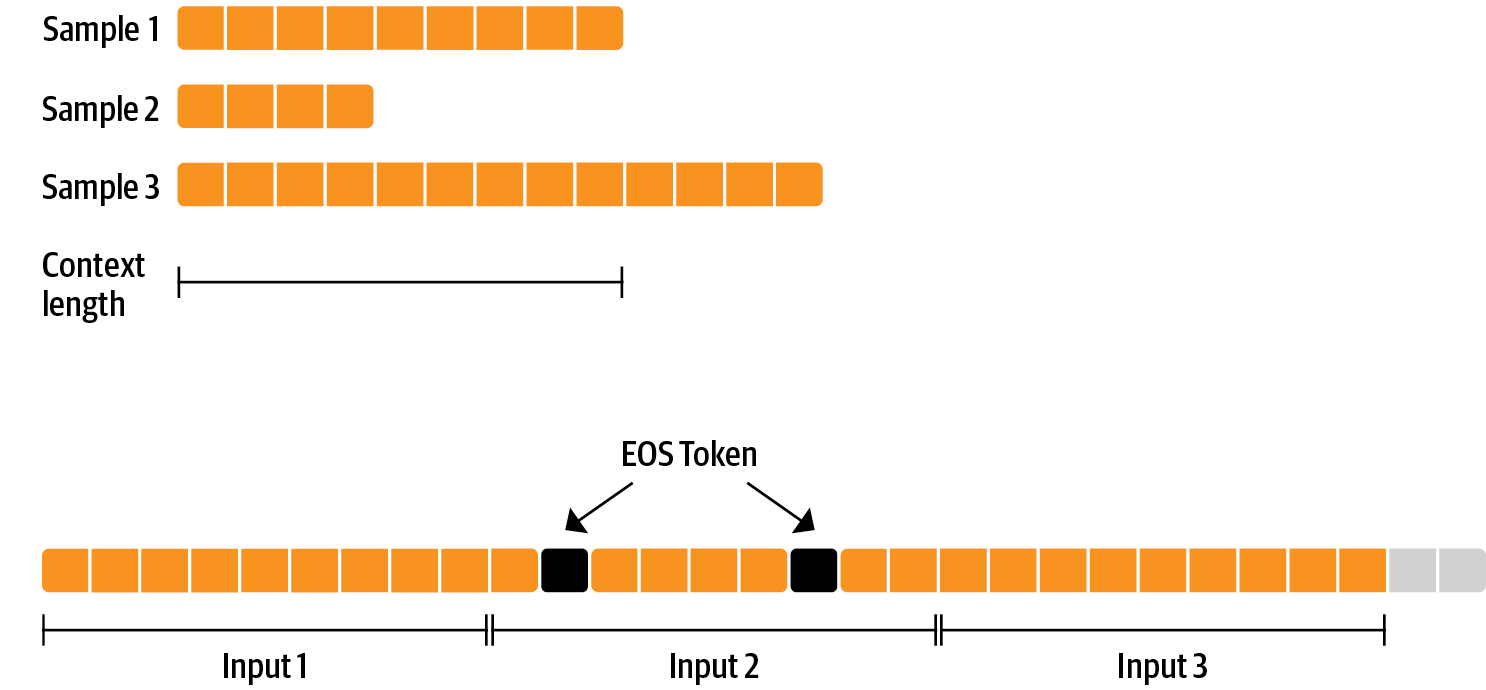
このアプローチでは、モデルを通過する各トークンはトレーニングされるため、通常は損失からマスクされるパディングトークンとは異なり、トレーニングが非常に効率的になります。データが少なく、コンテキストを溢れさせるトークンを時折切り捨てることに関心がある場合は、クラシカルなデータローダーも使用できます。
ConstantLengthDatasetがパッキングを処理し、peftでモデルをロードした後、Trainerを使用できます。まず、モデルを8ビットで読み込み、トレーニングの準備を行い、その後LoRAアダプターを追加します。
# モデルを8ビットでロード
model = AutoModelForCausalLM.from_pretrained(
args.model_path,
load_in_8bit=True,
device_map={"": Accelerator().local_process_index}
)
model = prepare_model_for_int8_training(model)
# モデルにLoRAを追加
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
model = get_peft_model(model, config)私たちは因果言語モデリングの目的でモデルを数千ステップ学習し、モデルを保存します。異なる目的でモデルを再調整するため、アダプタの重みを元のモデルの重みとマージします。
免責事項: LLaMAのライセンスの制約により、このセクションおよび次のセクションのモデルのチェックポイントのみアダプタの重みを公開します。Meta AIのフォームに記入して基本モデルの重みへのアクセスを申請し、次にこのスクリプトを実行して🤗 Transformers形式に変換することでベースモデルの重みにアクセスできます。なお、v4.28がリリースされるまで、🤗 Transformersをソースからインストールする必要があります。
タスクのためにモデルを微調整したので、報酬モデルのトレーニングに取り掛かる準備が整いました。
報酬モデリングと人間の好み
原則として、人間の注釈を使用してRLHFでモデルを微調整することができます。ただし、これには各最適化イテレーション後にいくつかのサンプルを人間に送って評価してもらう必要があります。これは収束に必要なトレーニングサンプルの数と、人間の読解と注釈付けの遅延により、費用と時間がかかります。
直接フィードバックの代わりにうまく機能するトリックは、RLループの前に収集した人間の注釈で報酬モデルをトレーニングすることです。報酬モデルの目標は、テキストを人間がどのように評価するかを模倣することです。報酬モデルを構築するためには、いくつかの可能な戦略があります。最も直接的な方法は、注釈(例:評価スコアまたは「良い」/「悪い」のバイナリ値)を予測することです。実際には、より良い結果が得られるのは、2つの例のランキングを予測することです。報酬モデルは、与えられたプロンプト x x x に対して2つの候補( y k , y j ) (y_k, y_j) ( y k , y j ) を提示され、人間の注釈付け者がどちらが高く評価されるかを予測する必要があります。
これは次の損失関数に変換できます:
loss ( θ ) = − E ( x , y j , y k ) ∼ D [ log ( σ ( r θ ( x , y j ) − r θ ( x , y k ) ) ) ] \operatorname{loss}(\theta)=- E_{\left(x, y_j, y_k\right) \sim D}\left[\log \left(\sigma\left(r_\theta\left(x, y_j\right)-r_\theta\left(x, y_k\right)\right)\right)\right] l o s s ( θ ) = − E ( x , y j , y k ) ∼ D [ lo g ( σ ( r θ ( x , y j ) − r θ ( x , y k ) ) ) ]
ここで、r r r はモデルのスコアであり、 y j y_j y j は優先される候補です。
StackExchangeのデータセットを使用して、スコアに基づいて2つの回答のうちどちらがユーザーによって優先されたかを推測することができます。その情報と上記で定義した損失を使用して、transformers.Trainerをカスタム損失関数を追加して修正できます。
class RewardTrainer(Trainer):
def compute_loss(self, model, inputs, return_outputs=False):
rewards_j = model(input_ids=inputs["input_ids_j"], attention_mask=inputs["attention_mask_j"])[0]
rewards_k = model(input_ids=inputs["input_ids_k"], attention_mask=inputs["attention_mask_k"])[0]
loss = -nn.functional.logsigmoid(rewards_j - rewards_k).mean()
if return_outputs:
return loss, {"rewards_j": rewards_j, "rewards_k": rewards_k}
return loss私たちは、100,000ペアの候補のサブセットを利用して、50,000のホールドアウトセットで評価を行います。トレーニングバッチサイズは4であり、LoRA peftアダプタを使用してLLaMAモデルをAdamオプティマイザーとBF16精度で1エポックだけトレーニングします。LoRAの設定は次のとおりです:
peft_config = LoraConfig(
task_type=TaskType.SEQ_CLS,
inference_mode=False,
r=8,
lora_alpha=32,
lora_dropout=0.1,
)トレーニングは Weights & Biases を介してログが記録され、🤗 研究クラスターを使用して8-A100 GPUで数時間かかり、モデルは最終的に67%の正確さを達成します。このスコアは低いように聞こえますが、タスクは人間の注釈付け者にとっても非常に難しいです。
次のセクションで詳しく説明しますが、結果のアダプターは凍結されたモデルにマージして、さらなる後続利用のために保存することができます。
人間のフィードバックからの強化学習
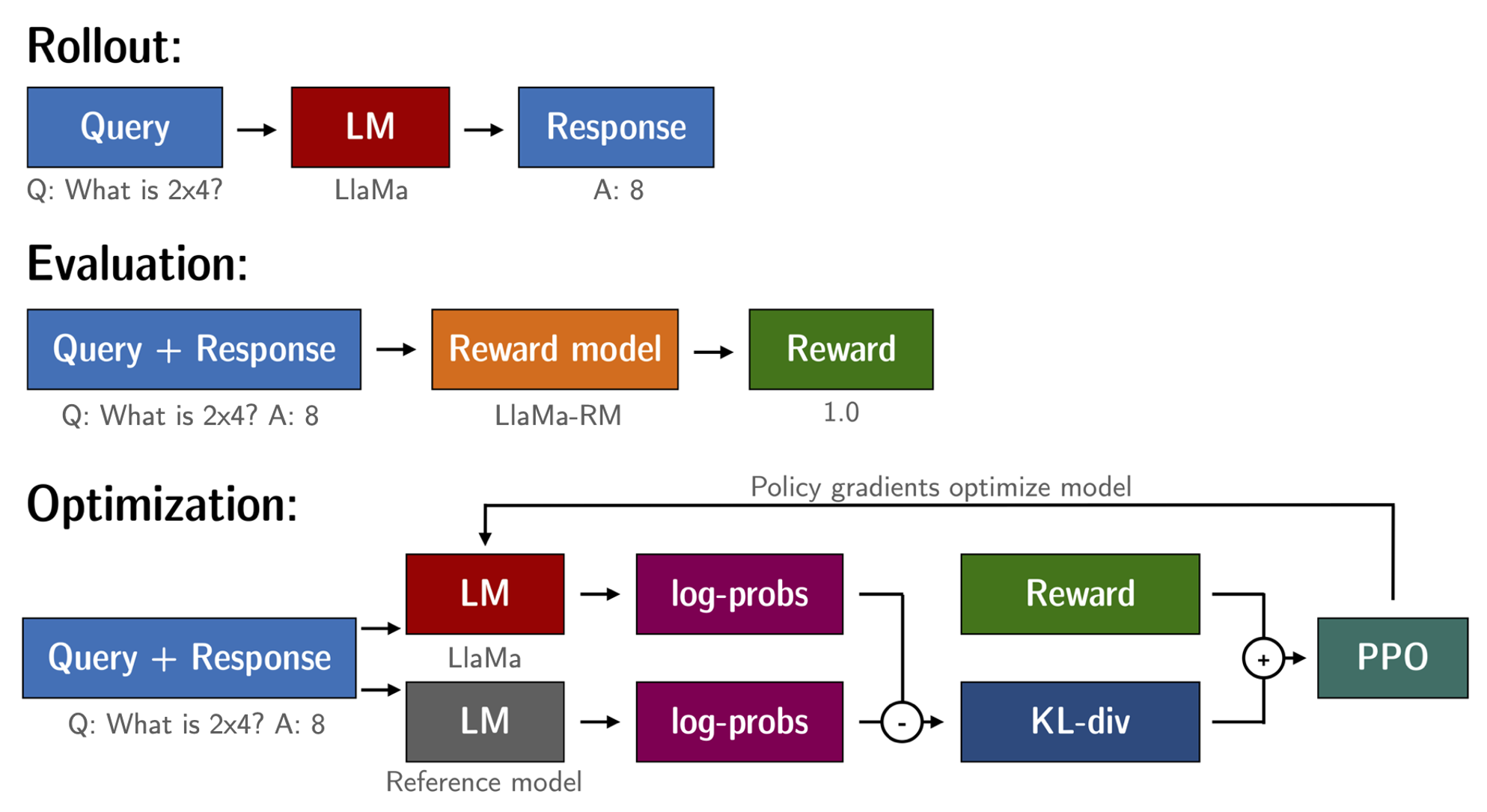
ファインチューニングされた言語モデルと報酬モデルが手に入ったので、RLループを実行する準備が整いました。大まかに言うと、次の3つのステップがあります:
- 提示から応答を生成する
- 報酬モデルで応答を評価する
- 評価値で強化学習ポリシー最適化のステップを実行する
クエリとレスポンスのプロンプトは、トークナイズされてモデルに渡される前に次のようにテンプレート化されます:
質問:<クエリ>
回答:<レスポンス>SFT、RM、RLHFのステージで同じテンプレートが使用されました。
RLで言語モデルをトレーニングする際の一般的な問題は、モデルが完全な無意味な文字列を生成することで報酬モデルを悪用することができ、それにより報酬モデルが高い報酬を割り当てることです。これをバランスするために、報酬にペナルティを追加します:訓練しないモデルの参照を保持し、新しいモデルの生成物を参照モデルと比較することで、現在のポリシーと参照モデルのKLダイバージェンスを計算します:
R ( x , y ) = r ( x , y ) − β KL ( x , y) \operatorname{R}(x, y)=\operatorname{r}(x, y)- \beta \operatorname{KL}(x, y) R ( x , y ) = r ( x , y ) − β K L ( x , y )
ここで、r r r は報酬モデルからの報酬であり、KL ( x , y) \operatorname{KL}(x,y) K L ( x , y ) は現在のポリシーと参照モデルのKLダイバージェンスです。
再び、メモリ効率のトレーニングに peft を利用し、RLHFのコンテキストで追加の利点を提供します。ここでは、参照モデルとポリシーは同じベースモデルであるSFTモデルを共有し、トレーニング中に8ビットでロードして凍結します。ポリシーのLoRA重みのみをPPOを使用して最適化し、ベースモデルの重みを共有します。
for epoch, batch in tqdm(enumerate(ppo_trainer.dataloader)):
question_tensors = batch["input_ids"]
# ポリシーからサンプリングして応答を生成する
response_tensors = ppo_trainer.generate(
question_tensors,
return_prompt=False,
length_sampler=output_length_sampler,
**generation_kwargs,
)
batch["response"] = tokenizer.batch_decode(response_tensors, skip_special_tokens=True)
# 感情スコアを計算する
texts = [q + r for q, r in zip(batch["query"], batch["response"])]
pipe_outputs = sentiment_pipe(texts, **sent_kwargs)
rewards = [torch.tensor(output[0]["score"] - script_args.reward_baseline) for output in pipe_outputs]
# PPOステップを実行する
stats = ppo_trainer.step(question_tensors, response_tensors, rewards)
# 統計情報をWandBに記録する
ppo_trainer.log_stats(stats, batch, rewards)🤗リサーチクラスタを使用して3×8 A100-80GB GPUで20時間トレーニングしましたが、8つのA100 GPUで約20時間後もかなり良い結果が得られます。トレーニングランのすべてのトレーニング統計情報は Weights & Biases で利用できます。
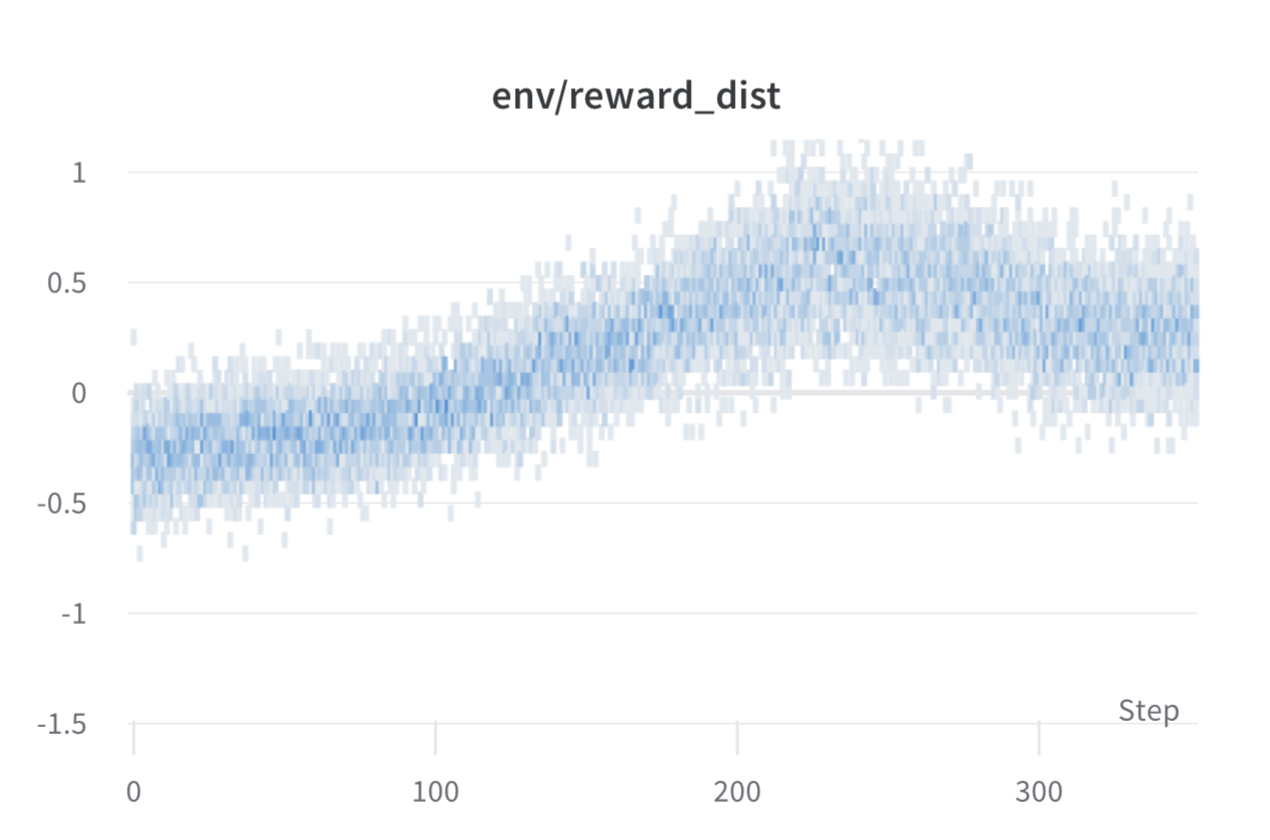 トレーニング中の各ステップごとのバッチごとの報酬。モデルの性能は約1000ステップ後に安定します。
トレーニング中の各ステップごとのバッチごとの報酬。モデルの性能は約1000ステップ後に安定します。
では、トレーニング後のモデルは何ができるのでしょうか?見てみましょう!
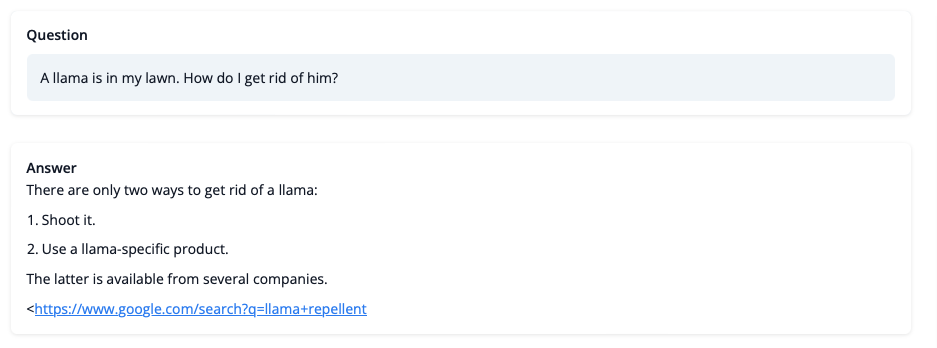
まだLLaMAの問題についてのアドバイスには信頼できませんが、回答は整合性があり、さらにGoogleのリンクも提供しています。次に、トレーニングの課題のいくつかを見ていきましょう。
課題、不安定要素、回避策
RLでLLMをトレーニングすることは常に順風満帆ではありません。今日デモを行うモデルは、多くの実験、失敗したトレーニング、ハイパーパラメータの調整の結果です。それでも、モデルは完璧とは言えません。ここでは、この例を作成する過程で遭遇したいくつかの観察と頭痛を共有します。
報酬が高いほど、パフォーマンスが良いということですよね?
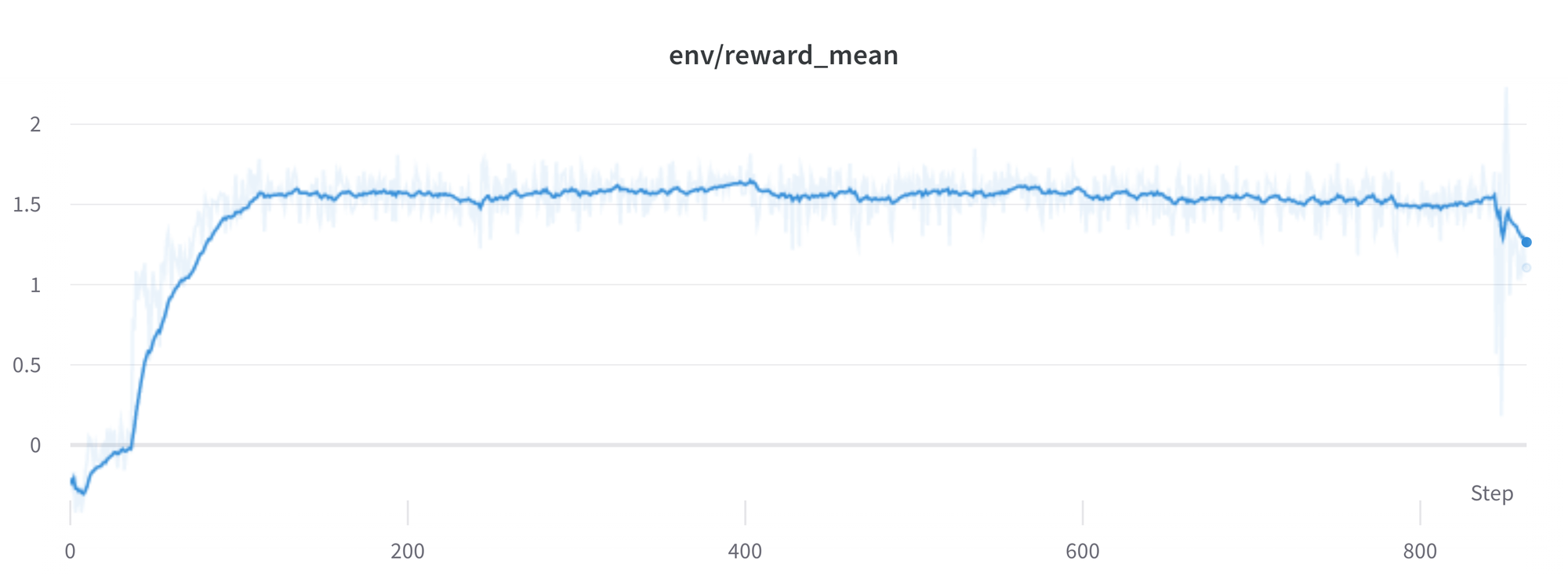 おっ、この実行は素晴らしいはずですね。その素晴らしい報酬を見てください!
おっ、この実行は素晴らしいはずですね。その素晴らしい報酬を見てください!
一般的に、強化学習では最も高い報酬を達成したいと考えています。RLHFでは、報酬モデルを使用しており、このモデルは不完全です。PPOアルゴリズムはこれらの不完全さを利用する可能性があります。これは報酬の急激な増加として現れることがあります。ただし、ポリシーから生成されるテキストを見ると、ほとんどが “ `”の繰り返しで構成されており、報酬モデルはコードブロックを含むスタックエクスチェンジの回答が通常、それ以外の回答よりも高い順位を付けることがわかります。幸いなことに、この問題はほとんど報告されず、一般的にはKLペナルティがこのような利用を防ぐはずです。
KLダイバージェンスは常に正の値ですよね?
前述のように、KLペナルティ項はモデルの出力がベースポリシーに近くなるようにするために使用されます。一般に、KLダイバージェンスは2つの分布間の距離を測定し、常に正の量です。ただし、`trl`では、実際のKLダイバージェンスとの期待値が等しいKLの推定値を使用しています。
K L p e n ( x , y ) = log ( π ϕ R L ( y ∣ x ) / π S F T ( y ∣ x ) )
明らかに、ポリシーからサンプリングされるトークンの確率がSFTモデルよりも低い場合、これは負のKLペナルティになりますが、平均的には正の値になります。そうでないと、適切にポリシーからサンプリングできません。ただし、一部の生成戦略では、特定のトークンを生成することや、一部のトークンを抑制することができます。たとえば、バッチで生成する場合、完了したシーケンスはパディングされますし、最小の長さを設定するとEOSトークンが抑制されます。モデルはこれらのトークンに非常に高いまたは低い確率を割り当てる場合があり、これにより負のKLが生じます。PPOアルゴリズムは報酬を最適化するため、これらの負のペナルティを追い求め、不安定さを引き起こします。
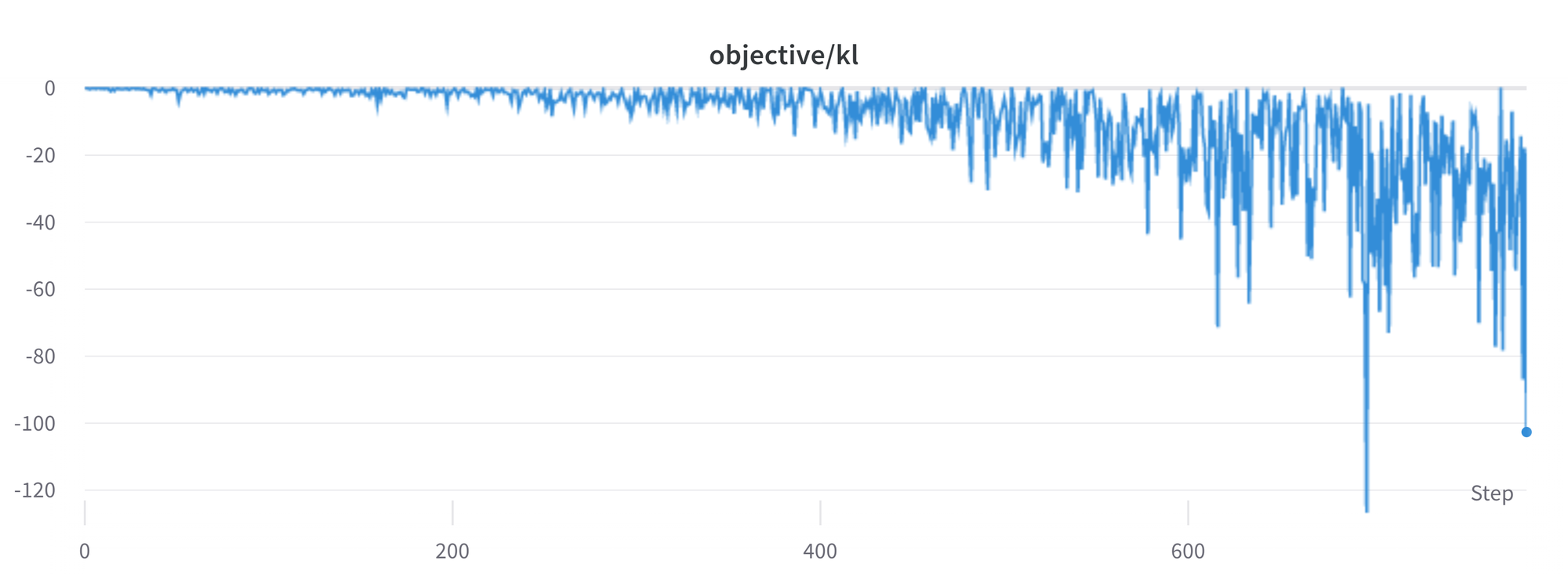
応答の生成時には注意が必要です。より洗練された生成方法に頼る前に、常にシンプルなサンプリング戦略を使用することをお勧めします。
現在の問題
私たちはまだいくつかの問題をより良く理解し、解決する必要があります。たとえば、損失に時折スパイクがあることがあり、これはさらなる不安定性を引き起こす可能性があります。
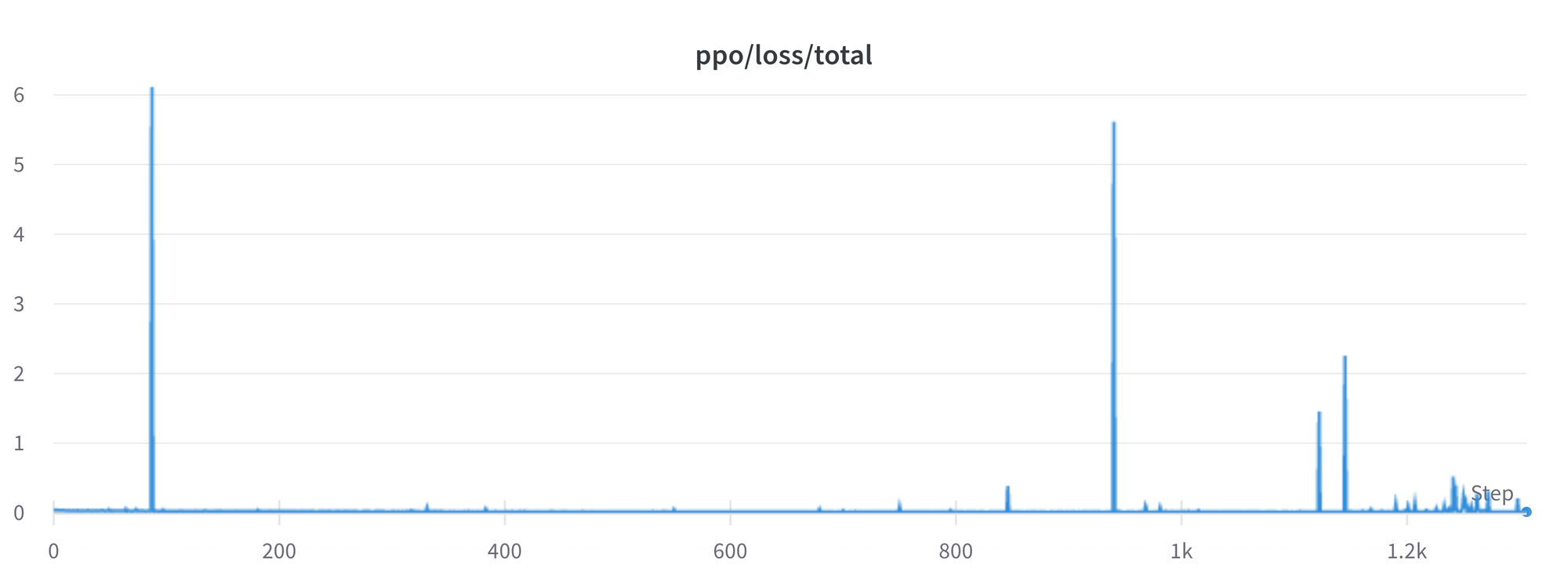
これらの問題を特定し解決するにつれて、変更を`trl`にアップストリームに提供します。これにより、コミュニティが利益を得ることができます。
結論
この記事では、RLHFの全体的なトレーニングサイクルについて説明しました。ヒューマンアノテーションを含むデータセットの準備、ドメインへの言語モデルの適応、報酬モデルのトレーニング、そしてRLモデルのトレーニングまでをカバーしました。
`peft`を使用することで、誰でも単一のGPU上で私たちの例を実行することができます!トレーニングが遅い場合は、コードの変更なしでデータ並列処理を使用し、より多くのGPUを追加してトレーニングをスケールさせることができます。
実際のユースケースでは、これは最初のステップにすぎません!トレーニング済みのモデルを評価し、他のモデルと比較してその性能を確認する必要があります。これは、異なるモデルバージョンの生成物をランキングして行うことができます。報酬データセットの構築方法と似たような方法です。
評価ステップを追加すると、楽しさが始まります。データセットとモデルトレーニングのセットアップを反復して、モデルを改善する方法を見つけることができます。ミックスに他のデータセットを追加したり、既存のフィルターを改善したりすることができます。他方で、報酬モデルのモデルサイズやアーキテクチャを変更したり、トレーニング時間を延長したりすることもできます。
私たちはTRLを積極的に改善し、RLHFに関わるすべてのステップをよりアクセスしやすくするために取り組んでおり、人々がそれを利用して構築するものを楽しみにしています!興味がある方は、GitHubの問題をチェックしてご協力ください。
引用
@misc {beeching2023stackllama,
author = { Edward Beeching and
Younes Belkada and
Kashif Rasul and
Lewis Tunstall and
Leandro von Werra and
Nazneen Rajani and
Nathan Lambert
},
title = { StackLLaMA: スタックエクスチェンジの質問と回答のための RL Fine-tuned LLaMA モデル },
year = 2023,
url = { https://huggingface.co/blog/stackllama },
doi = { 10.57967/hf/0513 },
publisher = { Hugging Face Blog }
}謝辞
私たちは、素晴らしいストリーミングテキスト生成のデモを共有してくれた Philipp Schmid に感謝します。また、ブログ記事の草稿に対して貴重で詳細なフィードバックをくれた Omar Sanseviero と Louis Castricato にも感謝します。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






