StableSRをご紹介します:事前トレーニング済み拡散モデルの力を活用した新たなAIスーパーレゾリューション手法
StableSRは、事前トレーニング済みの拡散モデルを活用した新しいAIスーパーレゾリューション手法です


コンピュータビジョンの分野では、様々な画像合成タスクのための拡散モデルの開発において、重要な進展が見られています。以前の研究は、Stable Diffusionなどの合成モデルに拡散先行モデルを統合することが、画像や動画の編集などの幅広い下流コンテンツ作成タスクに対して適用可能であることを示しています。
本記事では、コンテンツ作成を超えて、拡散先行モデルを超解像タスクに適用することの潜在的な利点を探求します。超解像は低レベルのビジョンタスクであり、高い画像の忠実度を要求するため、拡散モデルの固有の確率的な性質とは対照的な追加の課題をもたらします。
この課題への一般的な解決策は、スクラッチから超解像モデルをトレーニングすることです。これらの手法では、低解像度(LR)画像を追加の入力として組み込むことで、出力空間を制約し、忠実度を保持することを目指しています。これらのアプローチは優れた結果を達成していますが、拡散モデルのトレーニングにはかなりの計算リソースが必要です。また、ネットワークのトレーニングをゼロから開始することは、合成モデルで捉えられた生成先行モデルを損なう可能性があり、ネットワークのパフォーマンスが最適でない結果になる可能性があります。
- 「11/9から17/9までの週のトップ重要なコンピュータビジョンの論文」
- 無料でGoogle Colab上でQLoraを使用してLLAMAv2を微調整する
- 「ビデオセグメンテーションはよりコスト効果的になることができるのか?アノテーションを節約し、タスク間で一般化するための分離型ビデオセグメンテーションアプローチDEVAに会いましょう」
これらの制限に対応するために、別のアプローチが検討されています。この代替アプローチでは、事前にトレーニングされた合成モデルの逆拡散プロセスに制約を導入することが含まれます。このパラダイムにより、モデルのトレーニングを繰り返す必要がなくなり、拡散先行モデルの利点を活用することができます。ただし、これらの制約を設計するには、通常は画像の劣化に関する事前知識が必要であり、複雑なものでもあります。そのため、このような手法は一般化が制限されることが示されています。
上記の制限に対処するため、研究者たちはStableSRを導入しました。StableSRは、画像の劣化について明示的な仮定を必要とせずに、事前にトレーニングされた拡散先行モデルを保持するように設計された手法です。以下に、提示された手法の概要が示されています。
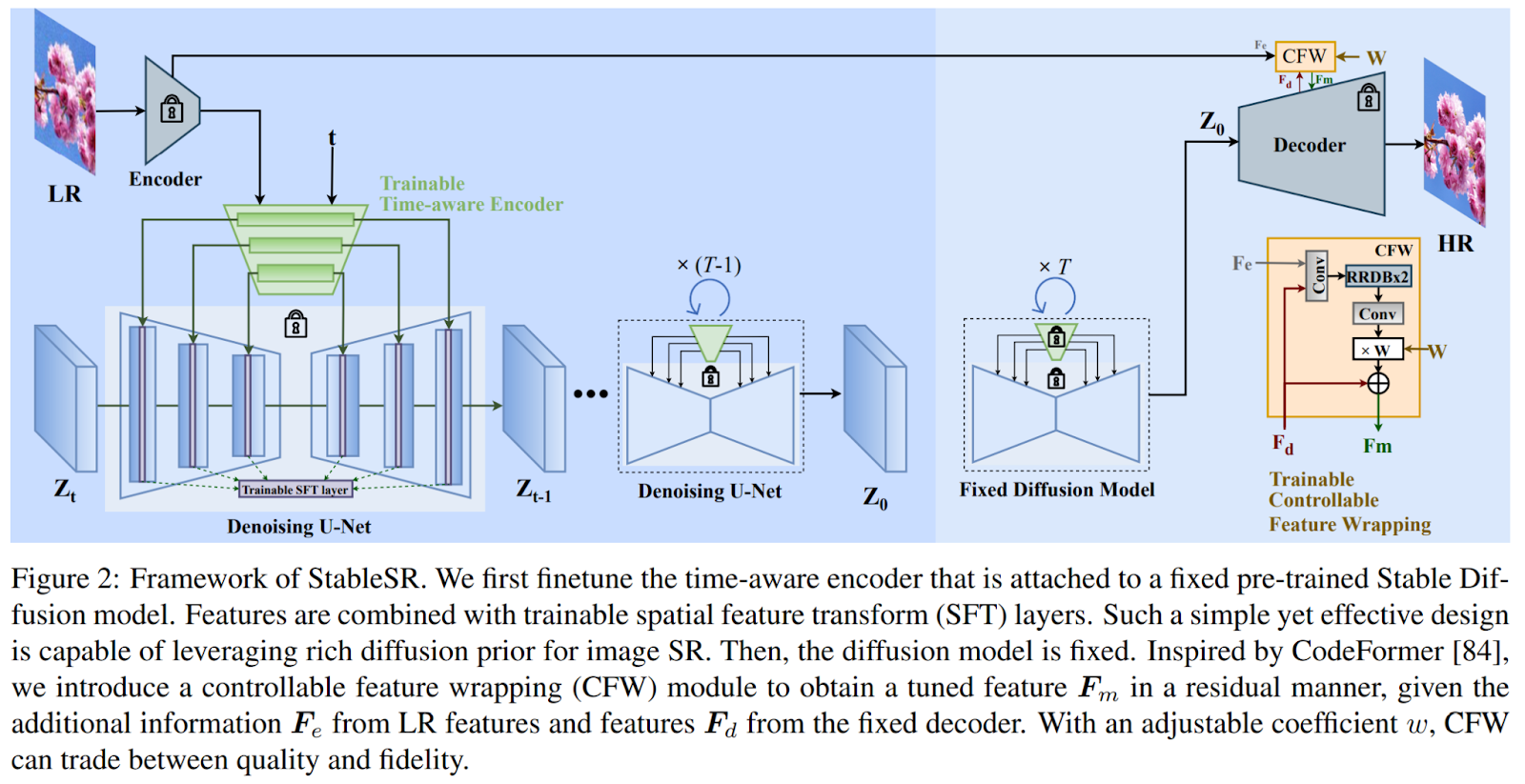
従来のアプローチでは、低解像度(LR)画像を中間出力に連結することが必要であり、スクラッチから拡散モデルをトレーニングする必要がありました。一方、StableSRでは、超解像(SR)タスクに特化した軽量のタイムアウェアエンコーダといくつかのフィーチャモジュレーション層の微調整が行われます。
エンコーダには、タイムエンベディングレイヤが組み込まれており、異なるイテレーションで拡散モデル内のフィーチャを適応的に変調するためのタイムアウェアフィーチャを生成します。これにより、トレーニング効率が向上し、生成先行モデルの整合性も維持されます。さらに、タイムアウェアエンコーダは、復元プロセス中に適応的なガイダンスを提供し、初期のイテレーションではより強力なガイダンスを、後のステージではより弱いガイダンスを行い、パフォーマンスの向上に大きく寄与します。
拡散モデルの固有のランダム性とオートエンコーダのエンコードプロセス中の情報損失を解決するために、StableSRでは制御可能なフィーチャラッピングモジュールを適用しています。このモジュールは、調整可能な係数を導入し、エンコーダのマルチスケール中間フィーチャを残差的な方法でデコードプロセス中の拡散モデルの出力を洗練します。調整可能な係数により、忠実度とリアリズムの間の連続的なトレードオフが可能となり、幅広い劣化レベルに対応します。
さらに、任意の解像度の超解像タスクに対して拡散モデルを適応させることは、過去に課題を提起してきました。これを克服するために、StableSRはプログレッシブな集約サンプリング戦略を導入しています。このアプローチでは、画像を重なり合うパッチに分割し、各拡散イテレーションでガウスカーネルを使用してそれらを融合します。その結果、境界部分でより滑らかな遷移が得られ、より一貫した出力が確保されます。
元の記事で提示されたStableSRの一部の出力サンプルと、最先端のアプローチとの比較結果は、以下の図に示されています。

まとめると、StableSRは、実世界の画像超解像の課題に対して生成ベースの事前知識を適応させるためのユニークな解決策を提供します。このアプローチは、劣化について明示的な仮定をすることなく、事前学習済みの拡散モデルを活用し、時間感知エンコーダ、制御可能な特徴ラッピングモジュール、および進行的な集約サンプリング戦略を組み込むことで、忠実度と任意の解像度の問題に対処します。StableSRは堅牢なベースラインとして機能し、拡散事前知識を復元タスクに応用する将来の研究をインスピレーションとして提供します。
興味があり、さらに詳しく知りたい場合は、以下に引用されたリンクを参照してください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「教科書で学ぶ教師なし学習:K-Meansクラスタリングの実践」
- オーディオSRにお会いください:信じられないほどの48kHzの音質にオーディオをアップサンプリングするためのプラグ&プレイであり、ワンフォーオールのAIソリューション
- LLMs(Language Model)と知識グラフ
- 「ベイチュアン2に会おう:7Bおよび13Bのパラメータを持つ大規模な多言語言語モデルのシリーズ、2.6Tトークンでゼロからトレーニングされました」
- 「機械学習が間違いを comitte たとき、それはどういう意味ですか?」
- 「LLM Fine-Tuningの理解:大規模言語モデルを独自の要件に合わせる方法」
- AWSにおける生成AIとマルチモーダルエージェント:金融市場における新たな価値を開拓するための鍵