「Pandasqlを使用したPandasでのSQL」
「PandasでのSQLを実行するためのPandasql活用術」

もしデータサイエンスのツールボックスに一つだけスキルを追加するとすれば、それは間違いなく最も重要なものであるSQLです。ただし、Pythonデータ分析エコシステムでは、pandasという強力で人気のあるライブラリがあります。
しかし、pandasに初心者の場合、グループ化、集計、結合などの操作を行うpandasの関数に慣れることは非常に困難です。そのため、SQLを使用してデータフレームをクエリする方がはるかに簡単です。そこで、pandasqlライブラリが活躍します!
では、pandasqlライブラリを使用してサンプルデータセット上のpandasデータフレームに対してSQLクエリを実行する方法を学びましょう。
- AGI(人工汎用知能)にどれくらい近づいているのでしょうか?
- 「コンテンツ戦略を開発するための最高のChatGPTプロンプト10選」
- 「ElaiのCEO&共同創業者、Vitalii Romanchenkoについてのインタビューシリーズ」
Pandasqlのはじめの一歩
さらに進む前に、作業環境を設定しましょう。
Pandasqlのインストール
Google Colabを使用している場合、次の`pip`コマンドを使用してpandasqlをインストールし、一緒にコードを実行できます:
pip install pandasql
ローカルマシンでPythonを使用している場合、このプロジェクト用の専用の仮想環境にpandasとSeabornがインストールされていることを確認してください。ビルトインのvenvパッケージを使用して、仮想環境を作成および管理できます。
私はUbuntu LTS 22.04上でPython 3.11を実行しています。したがって、次の手順はUbuntu向けです(Macでも動作するはずです)。Windowsマシンを使用している場合は、これらの手順に従って仮想環境を作成およびアクティブ化します。
プロジェクトディレクトリで仮想環境(ここではv1)を作成するには、次のコマンドを実行します:
python3 -m venv v1
次に、仮想環境をアクティブにします:
source v1/bin/activate
そして、pandas、seaborn、およびpandasqlをインストールします:
pip3 install pandas seaborn pandasql
注意: もしすでに`pip`がインストールされていない場合は、システムパッケージを更新し、次のコマンドでインストールできます: apt install python3-pip。
`sqldf`関数
pandasのデータフレームに対してSQLクエリを実行するために、次の構文でsqldfをインポートして使用することができます:
from pandasql import sqldfsqldf(query, globals())
ここで、
queryは、データフレーム上で実行したいSQLクエリを表します。有効なSQLクエリを含む文字列である必要があります。globals()は、クエリで使用されるデータフレームが定義されているグローバルなネームスペースを指定します。
Pandasqlを使用したPandasデータフレームのクエリ
まずは、必要なパッケージとsqldf関数をpandasqlからインポートしましょう:
import pandas as pdimport seaborn as snsfrom pandasql import sqldf
データフレームに対して複数のクエリを実行するため、クエリを引数として渡すことができるように、関数を定義します:
# Define a reusable function for running SQL queriesrun_query = lambda query: sqldf(query, globals())
以下の例すべてで、run_query関数(実際にはsqldf()を使用しています)を実行して、SQLクエリをtips_dfデータフレームに対して実行します。そして、返された結果を出力します。
データセットの読み込み
このチュートリアルでは、Seabornライブラリに組み込まれている「tips」というデータセットを使用します。「tips」データセットには、レストランのチップに関する情報が含まれており、合計金額、チップの金額、支払い者の性別、曜日などが含まれています。
「tip」データセットをデータフレーム tips_df に読み込みます:
# "tips" データセットを pandas のデータフレームに読み込むtips_df = sns.load_dataset("tips")
例1 – データの選択
ここでは最初のクエリとして、シンプルな SELECT 文を使用します:
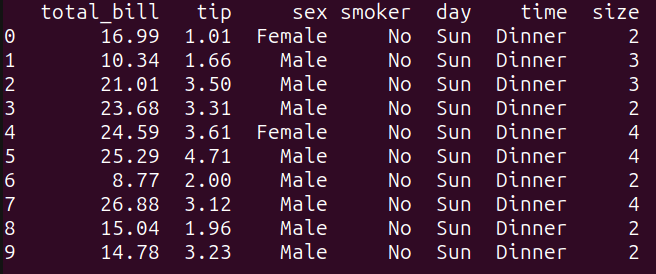
# シンプルな SELECT クエリquery_1 = """SELECT *FROM tips_dfLIMIT 10;"""result_1 = run_query(query_1)print(result_1)
このクエリでは、tips_dfデータフレームからすべての列を選択し、`LIMIT` キーワードを使用して出力を最初の10行に制限しています。これは pandas で tips_df.head(10) を実行するのと同じです:
例2 – 条件に基づくフィルタリング
次に、条件に基づいて結果をフィルタリングするクエリを作成しましょう:
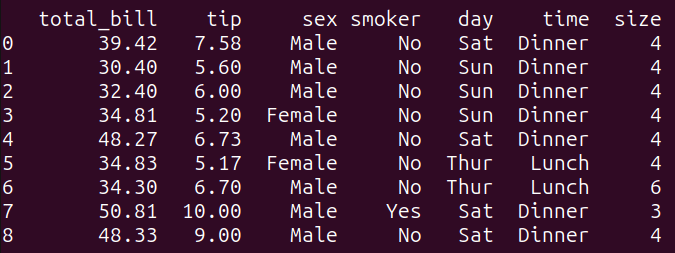
# 条件に基づいてフィルタリングするクエリquery_2 = """SELECT *FROM tips_dfWHERE total_bill > 30 AND tip > 5;"""result_2 = run_query(query_2)print(result_2)
このクエリでは、WHERE 句で指定された条件に基づいて、tips_dfデータフレームをフィルタリングしています。ここでは、’total_bill’が30より大きく、’tip’が5より大きい場合に、tips_dfデータフレームのすべての列を選択しています。
query_2 を実行すると、以下の結果が得られます:
例3 – グループ化と集計
次のクエリを実行して、日別の平均支払い金額を取得しましょう:
# グループ化と集計クエリquery_3 = """SELECT day, AVG(total_bill) as avg_billFROM tips_dfGROUP BY day;"""result_3 = run_query(query_3)print(result_3)
以下が出力です:
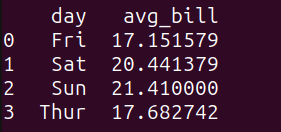
週末の平均支払い金額がわずかに高いことがわかります。
グループ化と集計の別の例を見てみましょう。以下のクエリを考えてみてください:
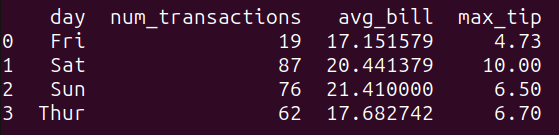
query_4 = """SELECT day, COUNT(*) as num_transactions, AVG(total_bill) as avg_bill, MAX(tip) as max_tipFROM tips_dfGROUP BY day;"""result_4 = run_query(query_4)print(result_4)
クエリ query_4 は、tips_df データフレームのデータを ‘day’ 列でグループ化し、各グループに対して次の集計関数を計算します:
num_transactions: 取引数のカウント、avg_bill: ‘total_bill’ 列の平均、max_tip: ‘tip’ 列の最大値。
上述の量が日別にグループ化されていることがわかります:
例4 – サブクエリ
サブクエリを使用した例クエリを追加しましょう:
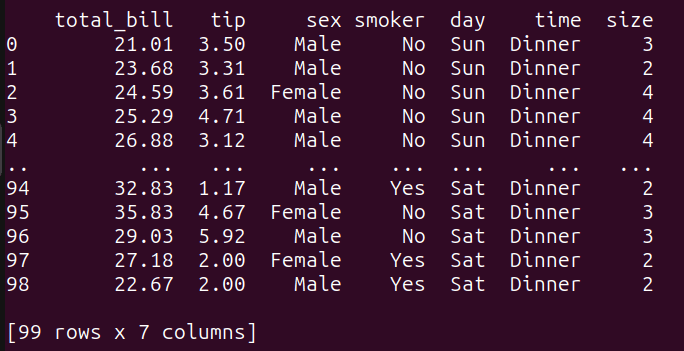
# サブクエリquery_5 = """tips_dfからSELECT *WHERE total_bill > (tips_dfからAVG(total_bill)を選択);"""result_5 = run_query(query_5)print(result_5)
ここでは,
- 内部のサブクエリは、
tips_dfデータフレームの「total_bill」列の平均値を計算します。 - 外部のクエリは、計算された平均値よりも「total_bill」が大きい
tips_dfデータフレームのすべての列を選択します。
query_5を実行すると、次の結果が得られます:
例5 – 2つのデータフレームの結合
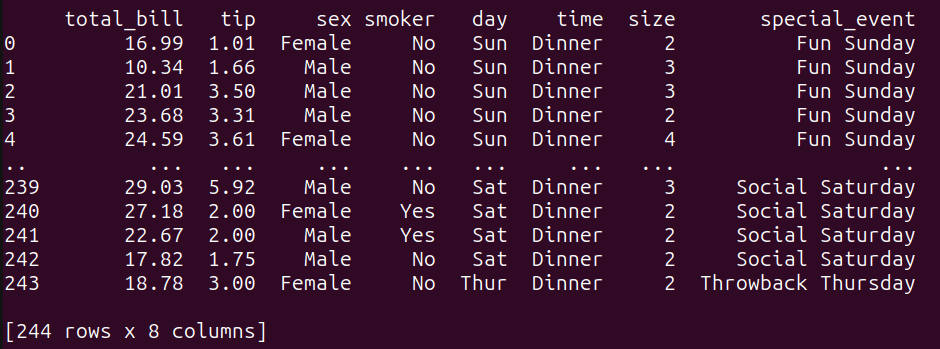
1つのデータフレームしかありません。単純な結合を行うために、次のような別のデータフレームを作成しましょう:
# 結合するための別のDataFrameを作成other_data = pd.DataFrame({ 'day': ['Thur','Fri', 'Sat', 'Sun'], 'special_event': ['Throwback Thursday', 'Feel Good Friday', 'Social Saturday','Fun Sunday', ]})
other_dataデータフレームは、各曜日を特別イベントに関連付けます。
次に、tips_dfとother_dataデータフレームを共通の「day」列でLEFT JOINします:
query_6 = """tips_dfからt.*、other_dataからo.special_eventを選択LEFT JOIN tips_dfのt ON t.day = o.day;"""result_6 = run_query(query_6)print(result_6)
結合操作の結果は次のとおりです:
まとめと次のステップ
このチュートリアルでは、pandasqlを使用してpandasデータフレームでSQLクエリを実行する方法について説明しました。pandasqlを使用すると、データフレームをSQLでクエリすることが非常に簡単になりますが、いくつかの制限があります。
主な制限は、pandasqlがネイティブのpandasよりも数倍遅い場合があることです。ではどうすればいいのでしょうか? pandasでデータ分析を行う必要がある場合は、pandasqlを使用してデータフレームをクエリすることができます。pandasを学びながらデータフレームのクエリを行い、すばやくスキルを向上させることができます。その後、pandasや他のライブラリ(例:Polars)に切り替えることができます。
この方向性への第一歩として、ここまで実行したSQLクエリのpandasによる同等のクエリを書いて実行してみてください。このチュートリアルで使用されたすべてのコード例はGitHubで入手できます。コーディングを続けましょう! Bala Priya Cは、インド出身の開発者兼テクニカルライターです。彼女は数学、プログラミング、データサイエンス、コンテンツ制作の交差点での作業を好みます。彼女の関心と専門知識の領域には、DevOps、データサイエンス、自然言語処理が含まれます。彼女は読書、執筆、コーディング、コーヒーを楽しんでいます!現在、彼女はチュートリアル、ハウツーガイド、意見稿などを執筆して、開発者コミュニティとの知識共有に取り組んでいます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






