データビジュアライゼーションのためのSQL チャートやグラフ用のデータの準備方法
「データビジュアライゼーションのためにSQLでチャートやグラフ用のデータを準備する方法」

おそらく、目を引くチャートやグラフを作成することは、単に適切な色や形状を選ぶだけではありません。本当の魔法は、それらのビジュアルを養うデータの中で起こります。
しかし、そのデータをどうやって正確に取得するのでしょうか?ここで登場するのがSQLです。SQLは、使用している可視化ツールで輝くようにデータを切り刻み、整える手助けをしてくれます。
では、この記事では何を扱うのでしょうか?まず、SQLを使用してデータの可視化に必要なデータを準備する方法を示します。次に、さまざまなタイプの可視化と、それぞれに必要なデータの準備方法について説明します。それには何らかの完成品も含まれます。すべての情報は、魅力的なビジュアルストーリーを作成するための鍵を提供することを目的としています。だから、コーヒーを用意して、楽しんでください!
データ準備のためのSQLクエリ
可視化のタイプについて詳しく説明する前に、SQLがデータの準備をどのように行うかを見てみましょう。SQLは、視覚的な「映画」の脚本作家のようなものであり、伝えたい物語を微調整します。

フィルター
WHERE句は、不要なデータをフィルタリングします。たとえば、分析に興味があるのは18歳から25歳のユーザーだけだとしたら、SQLを使用してそれらをフィルタリングすることができます。
お客様のフィードバックを分析しているとしましょう。SQLを使用すると、フィードバックの評価が3未満のレコードのみをフィルタリングし、改善の余地を示すことができます。
SELECT * FROM feedbacks WHERE rating < 3;
ソート
ORDER BY句はデータを並べ替えます。データを時系列のグラフに表示する場合、ソートは重要な役割を果たします。
製品の月次売上の折れ線グラフを作成する場合、SQLはデータを月別に並べ替えることができます。
SELECT month, sales FROM products ORDER BY month;
結合
JOINステートメントは、2つ以上のテーブルからデータを結合します。これにより、より豊かなデータセットが可能になり、したがって、より包括的な可視化が可能になります。
1つのテーブルにはユーザーデータがあり、もう1つのテーブルには購入データがあるかもしれません。SQLでは、これらを結合してユーザーごとの総支出額を表示することができます。
SELECT users.id, SUM(purchases.amount) FROM usersJOIN purchases ON users.id = purchases.user_idGROUP BY users.id;
グループ化
GROUP BY句はデータをカテゴリ別に分類します。これは、COUNT()、SUM()、AVG()などの集計関数と一緒に使用され、各グループに対して計算を行うためによく使用されます。
ウェブサイトのさまざまなセクションごとに平均時間を知りたい場合、SQLはセクションごとにデータをグループ化し、平均を計算することができます。
SELECT section, AVG(time_spent) FROM website_dataGROUP BY section;
データの可視化のタイプ
さまざまな種類のビジュアルヘルプに入る前に、なぜそれらが重要なのかを理解することが重要です。各チャートやグラフを異なるデータの「レンズ」と考えてください。選択するタイプによって、トレンドを捉えたり、外れ値を特定したり、物語を語ることができます。
チャート
データサイエンスでは、データセットを理解する最初のステップとして、チャートが使用されます。たとえば、モバイルアプリのユーザー年齢の分布を理解するためにヒストグラムを使用するかもしれません。MatplotlibやSeabornなどのツールを使用して、これらのチャートをプロットすることが一般的です。
SQLクエリを実行してカウント、平均値などのメトリックを取得し、それを直接チャート作成ツールにデータ供給することで、棒グラフや円グラフ、ヒストグラムなどの可視化を作成することができます。
以下のSQLクエリは、都市ごとにユーザーの年齢を集計するのに役立ちます。年齢が都市ごとにどのように変化するかを可視化するためには、このデータの準備が不可欠です。
# 各都市のユーザーの平均年齢を求めるためのSQLコードSELECT city, AVG(age)FROM usersGROUP BY city;
Matplotlibを使用して棒グラフを作成しましょう。以下のコードスニペットは、上記のSQLクエリから平均年齢のデータがgrouped_dfに含まれていることを前提とし、都市ごとのユーザーの平均年齢を示す棒グラフを作成します。
import matplotlib.pyplot as plt# grouped_dfに平均年齢のデータが含まれていることを前提とするplt.figure(figsize=(10, 6))plt.bar(grouped_df['city'], grouped_df['age'], color='blue')plt.xlabel('都市')plt.ylabel('平均年齢')plt.title('都市別ユーザーの平均年齢')plt.show()
以下は棒グラフです。

グラフ
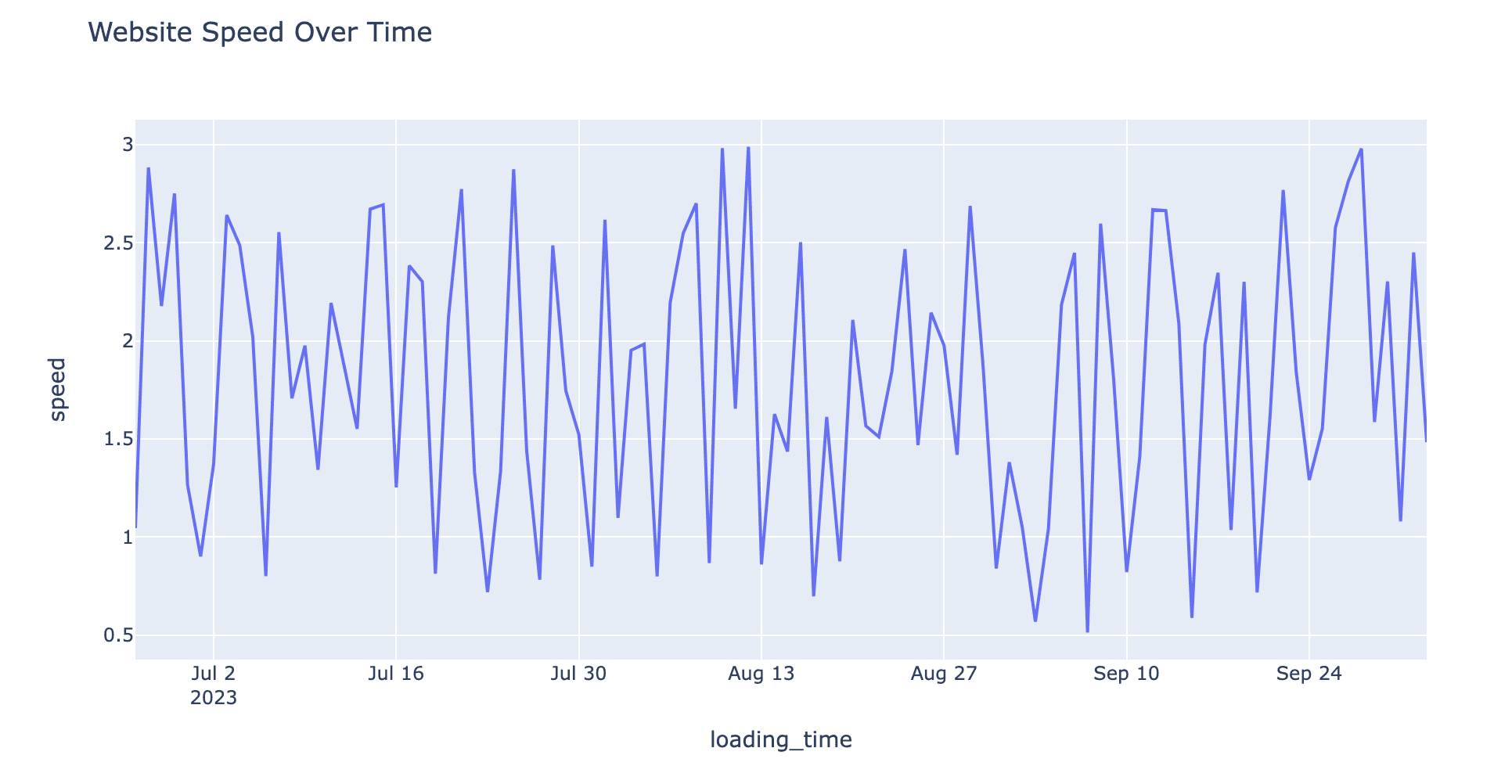
ウェブサイトの速度を時間の経過に追跡しているとします。折れ線グラフを使用すると、データの傾向やピーク、谷を表示し、ウェブサイトのパフォーマンスが最も良いときや最も悪いときを強調することができます。
PlotlyやBokehのようなツールを使用すると、より複雑な視覚化も作成できます。SQLを使用して時系列データを準備し、おそらく日ごとの平均読み込み時間を計算するクエリを実行してから、グラフ化ツールに送信することになります。
以下のSQLクエリは、各日の平均ウェブサイト速度を計算します。このようなクエリを使用すると、時間の経過にわたるパフォーマンスを示す時系列折れ線グラフを簡単にプロットできます。
-- 各日の平均読み込み時間を求めるためのSQLコードSELECT DATE(loading_time), AVG(speed)FROM website_speedGROUP BY DATE(loading_time);
ここでは、時間の経過に応じたウェブサイト速度を表示する折れ線グラフを作成するために、Plotlyを選択したとします。SQLクエリは、時系列データを準備し、時間の経過におけるウェブサイト速度を示しています。
import plotly.express as pxfig = px.line(time_series_df, x='loading_time', y='speed', title='時間の経過におけるウェブサイト速度')fig
以下は折れ線グラフです。
ダッシュボード
リアルタイムなモニタリングが必要なプロジェクトでは、ダッシュボードが不可欠です。オンラインプラットフォームのリアルタイムユーザーエンゲージメントメトリクスを追跡するダッシュボードを想像してみてください。
PowerBIやGoogle Data Studio、Tableauなどのツールを使用すると、SQLデータベースからデータを取得してこれらのダッシュボードを作成できます。SQLを使用してデータを集計し、更新することで、ダッシュボード上で常に最新のインサイトを確認できます。
-- 現在のアクティブユーザー数と平均セッション時間を求めるためのSQLコードSELECT COUNT(DISTINCT user_id) as active_users, AVG(session_time)FROM user_sessionsWHERE session_end IS NULL;
PowerBIでは、通常、SQLデータベースをインポートし、ダッシュボードの視覚化のために類似のクエリを実行します。PowerBIの利点は、リアルタイムダッシュボードを作成できることです。平均年齢や他のKPIを表示するために複数のタイルを設定し、リアルタイムで更新されます。
最後の考え
データの視覚化は、単に美しいチャートやグラフを作成するだけでなく、データとともに魅力的なストーリーを語ることでもあります。SQLは、裏側でデータを準備し、フィルタリングし、整理するための重要な役割を果たします。整備された機械の歯車のように、SQLクエリはあなたの視覚化を可能にするだけでなく、洞察力をもたらす見えないメカニズムとなります。
さらに実践的な経験を積みたい場合は、StrataScratchプラットフォームを訪れてください。トップ企業の実際の面接質問からデータプロジェクトまで、さまざまなリソースが用意されており、スキルを磨き、夢の仕事に就くのをサポートします。
****[Nate Rosidi](https://twitter.com/StrataScratch)****は、データサイエンティストであり、製品戦略に従事しています。また、解析を教える非常勤講師でもあり、StrataScratchの創設者です。StrataScratchは、トップ企業からの実際の面接質問を使ってデータサイエンティストが面接に備えるのを支援するプラットフォームです。TwitterでStrataScratchやLinkedInで彼とつながりましょう。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「Google Brainの共同創設者は、テック企業がAIのリスクを大げさに報じている」と主張しています
- チャットGPTを使用して複雑なシステムを構築する
- 「グーグルのAI研究によると、グラフデータのエンコーディングが言語モデルのパフォーマンスを複雑なタスクに向上させることが明らかになりました」
- 「ジュニアデータサイエンティストのための3つのキャリアの重要な決断」
- アップル M2 Max GPU vs Nvidia V100、P100、およびT4
- 「5つのシンプルなステップシリーズ:Python、SQL、Scikit-learn、PyTorch、Google Cloudをマスターする」
- 「データ分析での創発的AIの解放」
