「Mozilla Common Voiceにおける音声言語認識 — 音声変換」
Speech recognition and voice conversion in Mozilla Common Voice
これは、Mozilla Common Voiceデータセットに基づいた音声認識に関する3番目の記事です。第1部では、データの選択とデータの前処理について、第2部では、いくつかのニューラルネットワーク分類器の性能について分析しました。
最終モデルは92%の正確さと97%のペアワイズ正確さを達成しました。このモデルはやや高い分散を抱えているため、より多くのデータを追加することで正確性を改善することができます。追加のデータを取得するための非常に一般的な方法の1つは、利用可能なデータセットにさまざまな変換を行って合成することです。
この記事では、オーディオデータ拡張のための5つの人気のある変換を考えます。ノイズの追加、速度の変更、ピッチの変更、タイムマスキング、カット&スプライスです。
チュートリアルのノートブックはこちらで入手できます。
- スタビリティAIが日本語のStableLMアルファを発表:日本語言語モデルの飛躍的な進化
- PlayHTチームは、感情の概念を持つAIモデルをGenerative Voice AIに導入しますこれにより、特定の感情で話しの生成を制御し、指示することができるようになります
- 大規模言語モデルは、テキスト評価のタスクで人間を置き換えることができるのか? このAI論文では、テキストの品質を評価するためにLLMを使用し、人間の評価の代替手段として提案しています
説明のために、Mozilla Common Voice(MCV)データセットからサンプルのcommon_voice_en_100040を使用します。これは「燃え盛る火は消えていました」という文です。
import librosa as lrimport IPythonsignal, sr = lr.load('./transformed/common_voice_en_100040.wav', res_type='kaiser_fast') #load signalIPython.display.Audio(signal, rate=sr)MCVの元のサンプルcommon_voice_en_100040。
ノイズの追加
ノイズの追加は、最もシンプルなオーディオ拡張です。ノイズの量は、信号対ノイズ比(SNR)で特徴付けられます。SNRは、最大信号振幅とノイズの標準偏差の比率です。いくつかのノイズレベルを生成し、それらが信号にどのように影響するかを見てみましょう。
SNRs = (5,10,100,1000) #Signal-to-noise ratio: max amplitude over noise stdnoisy_signal = {}for snr in SNRs: noise_std = max(abs(signal))/snr #get noise std noise = noise_std*np.random.randn(len(signal),) #generate noise with given std noisy_signal[snr] = signal+noiseIPython.display.display(IPython.display.Audio(noisy_signal[5], rate=sr))IPython.display.display(IPython.display.Audio(noisy_signal[1000], rate=sr))オリジナルのMCVサンプルcommon_voice_en_100040にSNR=5およびSNR=1000のノイズを重ね合わせて得られる信号(著者による生成)。
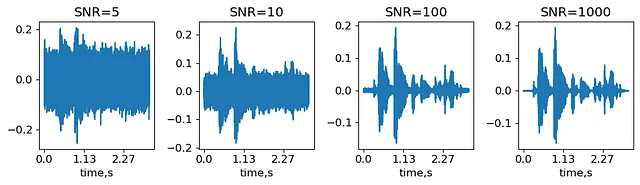
したがって、SNR=1000はほとんど変化のないオーディオのように聞こえ、SNR=5では信号の最も強い部分しか区別できません。実際のところ、SNRレベルはデータセットと選択した分類器に依存するハイパーパラメータです。
速度の変更
速度を変更する最も簡単な方法は、信号に異なるサンプルレートを持つフリをすることです。ただし、これによりピッチ(音声の低い/高い周波数)も変化します。サンプリングレートを増やすと、声が高く聞こえます。これを示すために、例としてサンプリングレートを1.5倍に「増やします」:
IPython.display.Audio(signal, rate=sr*1.5)元のMCVサンプルcommon_voice_en_100040に偽のサンプリングレートを使用した信号(著者による生成)。
ピッチに影響を与えずに速度を変更することはより困難です。フェーズボコーダ(PV)アルゴリズムを使用する必要があります。簡単に言うと、入力信号はまず重なり合うフレームに分割されます。次に、各フレーム内のスペクトルは高速フーリエ変換(FFT)を適用して計算されます。再生速度は、異なる速度でフレームを再合成することで変更されます。各フレームの周波数成分は影響を受けないため、ピッチは変わりません。PVはフレーム間を補完し、滑らかさを実現するために位相情報を使用します。
実験には、このPVの実装から stretch_wo_loop のタイムストレッチ関数を使用します。
stretching_factor = 1.3signal_stretched = stretch_wo_loop(signal, stretching_factor)IPython.display.Audio(signal_stretched, rate=sr)速度を変化させた元のMCVサンプル common_voice_en_100040(著者によって生成された)から得られた信号。
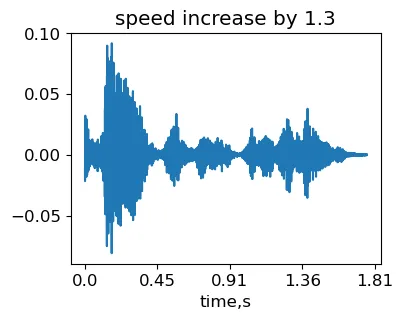
したがって、速度を上げたため、信号の長さが短くなりました。ただし、ピッチは変わっていないことが聞こえます。ストレッチングファクターが大きい場合、フレーム間の位相補間がうまく機能しない可能性があることに注意してください。その結果、変換されたオーディオにエコーアーティファクトが現れる場合があります。
ピッチの変更
速度に影響を与えずにピッチを変更するには、同じPVのタイムストレッチを使用しますが、信号が異なるサンプリングレートを持つように見せかけることで、信号の総時間が同じになるようにします。
IPython.display.Audio(signal_stretched, rate=sr/stretching_factor)元のMCVサンプル common_voice_en_100040(著者によって生成された)のピッチを変化させた信号。
librosa にはすでに time_stretch および pitch_shift 関数があるため、なぜこれらのPVを使用する必要があるのですか?そのような関数は信号を時間領域に戻します。後で埋め込みを計算する必要がある場合、冗長なフーリエ変換に時間を費やすことになります。一方、stretch_wo_loop 関数を逆変換せずにフーリエ出力を生成するように変更するのは簡単です。類似の結果を得るために librosa のコードに取り組むこともできるかもしれません。
タイムマスキングとカット&スプライス
これらの2つの変換は最初に周波数領域で提案されました(Park et al. 2019)。アイデアは、オーディオの拡張のために事前計算されたスペクトルを使用してFFTにかかる時間を節約することでした。簡単のために、これらの変換が時間領域でどのように機能するかを示します。リストされた操作は、時間軸をフレームインデックスに置き換えることで、簡単に周波数領域に転送できます。
タイムマスキング
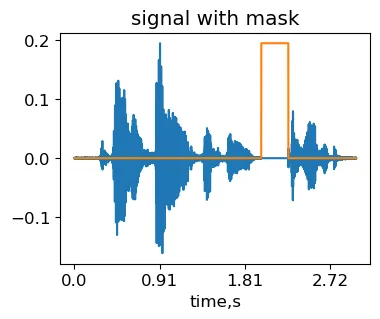
タイムマスキングのアイデアは、信号のランダムな領域を覆い隠すことです。そのため、ニューラルネットワークは一般化できない信号固有の時間的変動を学習する機会が少なくなります。
max_mask_length = 0.3 #マスクの最大長さ、信号長の比率L = len(signal)mask_length = int(L*np.random.rand()*max_mask_length) #ランダムにマスクの長さを選択mask_start = int((L-mask_length)*np.random.rand()) #ランダムにマスクの位置を選択masked_signal = signal.copy()masked_signal[mask_start:mask_start+mask_length] = 0IPython.display.Audio(masked_signal, rate=sr)元のMCVサンプル common_voice_en_100040(著者によって生成された)にタイムマスク変換を適用して得られた信号。
カット&スプライス
アイデアは、信号のランダムに選択された領域を同じラベルを持つ別の信号のランダムなフラグメントで置き換えることです。実装はタイムマスキングとほぼ同じですが、マスクの代わりに別の信号の一部が配置されます。
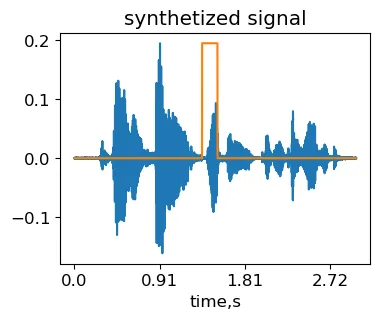
other_signal, sr = lr.load('./common_voice_en_100038.wav', res_type='kaiser_fast') #2番目の信号をロードmax_fragment_length = 0.3 #フラグメントの最大長さ、信号長の比率L = min(len(signal), len(other_signal))mask_length = int(L*np.random.rand()*max_fragment_length) #ランダムにマスクの長さを選択mask_start = int((L-mask_length)*np.random.rand()) #ランダムにマスクの位置を選択synth_signal = signal.copy()synth_signal[mask_start:mask_start+mask_length] = other_signal[mask_start:mask_start+mask_length]IPython.display.Audio(synth_signal, rate=sr)著者によって生成されたオリジナルMCVサンプルcommon_voice_en_100040にcut&splice変換を適用して得られた合成信号。
以下の表は、各変換の典型的なパラメータ値でのバリデーションセット上のAttNNモデルの精度を示しています。

上記の結果から、これらの変換のいずれも、私たちのMCVベースの音声認識セットアップの精度を大きく変えることはありませんでした。ただし、これらの変換は他のデータセットではパフォーマンスを向上させる可能性があります。最後に、最適なハイパーパラメータを探す際には、ランダム/グリッドサーチではなく、これらの変換を一つずつ試すことが意味があります。その後、効果的な変換を組み合わせることができます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






