SoundStorm:効率的な並列音声生成
SoundStorm Efficient parallel voice generation.
Zalán Borsos氏(リサーチソフトウェアエンジニア)とMarco Tagliasacchi氏(シニアスタッフリサーチサイエンティスト)がGoogle Researchで発表した記事です。
最近の生成AIの進歩により、テキスト、ビジョン、オーディオなど、さまざまな領域で新しいコンテンツを作成する可能性が開かれました。これらのモデルは、生データが最初にトークンのシーケンスとして圧縮されることに依存しています。オーディオの場合、ニューラルオーディオコーデック(例えば、SoundStreamまたはEnCodec)を使用して、波形をコンパクトな表現に効率的に圧縮することができます。これにより、元のオーディオ信号の近似値を再構成できます。この表現は、音の局所的な特性(たとえば、音素)および時間的構造(たとえば、韻律)を捉えた離散的な音声トークンのシーケンスで構成されています。オーディオを離散的なトークンのシーケンスとして表現することで、Transformerベースのシーケンスツーシーケンスモデルを使用してオーディオ生成を実行できるようになりました。これにより、音声継続性(AudioLMを使用した)、テキストから音声への変換(SPEAR-TTSを使用した)、一般的なオーディオや音楽の生成(AudioGenおよびMusicLMを使用した)において急速な進歩が可能になりました。多くの生成オーディオモデル、AudioLMを含む、自己回帰デコーディングに依存しています。この方法は高い音響品質を実現しますが、特に長いシーケンスをデコードする場合、推論(出力の計算)が遅くなることがあります。
この問題に対処するため、「SoundStorm: Efficient Parallel Audio Generation」という記事で、効率的かつ高品質なオーディオ生成の新しい方法を提案しています。SoundStormは、SoundStreamニューラルコーデックによって生成されるオーディオトークンの特性に適合するアーキテクチャと、MaskGITと呼ばれる最近提案された画像生成の方法に着想を得たデコードスキームの2つの新しい要素に依存して、長いオーディオトークンシーケンスの生成の問題に対処します。これにより、AudioLMの自己回帰デコーディングアプローチと比較して、SoundStormはトークンを並列に生成できるため、長いシーケンスの推論時間を100倍短縮することができ、同じ品質で、声質や音響条件の一貫性が高いオーディオを生成できます。さらに、SPEAR-TTSのテキストから意味論的モデリング段階と組み合わせたSoundStormは、例えば以下の例で示されるように、高品質で自然な対話を合成することができ、話される内容(トランスクリプトを介して)、話者の声(短い音声プロンプトを介して)、話者のターン(トランスクリプト注釈を介して)を制御できます。
| 入力:テキスト(オーディオ生成を駆動するトランスクリプトは太字) | 今朝、私にとてもおかしなことが起こりました。| え、本当に?|普段通りに起きて、朝食を食べに下に降りたんです。|なるほど。| 食べ始めてから10分後に、今夜中だと気づいたんです。| あ、それはおもしろい。| | 昨晩よく眠れなかったんだ。|え、どうしたの?|よくわからないんだ。どうしても寝付けなくて、一晩中寝返りを打ち続けたんだ。|そうなんだ。今晩は早く寝た方がいいかもしれないし、本でも読んでみるのはどうかな。|ああ、ありがとう。そうだといいんだけど。|どういたしまして。よく眠れるといいね。 | ||
| 入力:オーディオプロンプト | ||||
| 出力:オーディオプロンプト+生成されたオーディオ |
SoundStormの設計
以前のAudioLMの研究で、オーディオ生成を2つのステップに分解できることを示しました。1つ目は、意味的なトークンを生成する意味モデリングであり、前の意味トークンまたは条件信号(SPEAR-TTSのトランスクリプトやMusicLMのようなテキストプロンプトなど)から意味トークンを生成します。2つ目は、意味トークンから音声トークンを生成する音響モデリングです。SoundStormでは、より高速な並列デコードによって、より遅い自己回帰デコーディングを置き換え、音響モデリングに特に対処しています。
SoundStormは、トランスフォーマーと畳み込みを組み合わせたモデルアーキテクチャであるConformerに双方向アテンションを依存しており、トークンのシーケンスのローカルおよびグローバルな構造を捕捉します。具体的には、AudioLMが生成した意味トークンのシーケンスを入力として与えられた場合、SoundStreamによって生成されたオーディオトークンを予測するようにモデルが訓練されます。この際、各時間ステップtにおいて、SoundStreamは、右側に示すように、残差ベクトル量子化(RVQ)として知られる方法を使用して、最大Qトークンまでオーディオを表現します。主要な考え方は、各ステップで生成されるトークンの数が1からQに増えるにつれて、再構築されたオーディオの品質が徐々に向上するということです。
推論時には、入力として意味トークンを与えた場合、SoundStormは、すべてのオーディオトークンをマスクアウトし、RVQレベルq = 1の粗いトークンから始めて、より細かいトークンまでレベル別に進み、レベルq = Qに達するまで、複数の反復にわたってマスクされたトークンを埋めます。
SoundStormの高速な生成を可能にする2つの重要な側面があります。1つは、RVQレベル内の単一の反復中にトークンが並列に予測されることであり、2つ目は、モデルアーキテクチャが設計されており、レベルQの数によって複雑さがわずかにしか影響を受けないことです。この推論方式をサポートするために、トレーニング中には、反復的に使用されるマスキングスキームが慎重に設計されています。
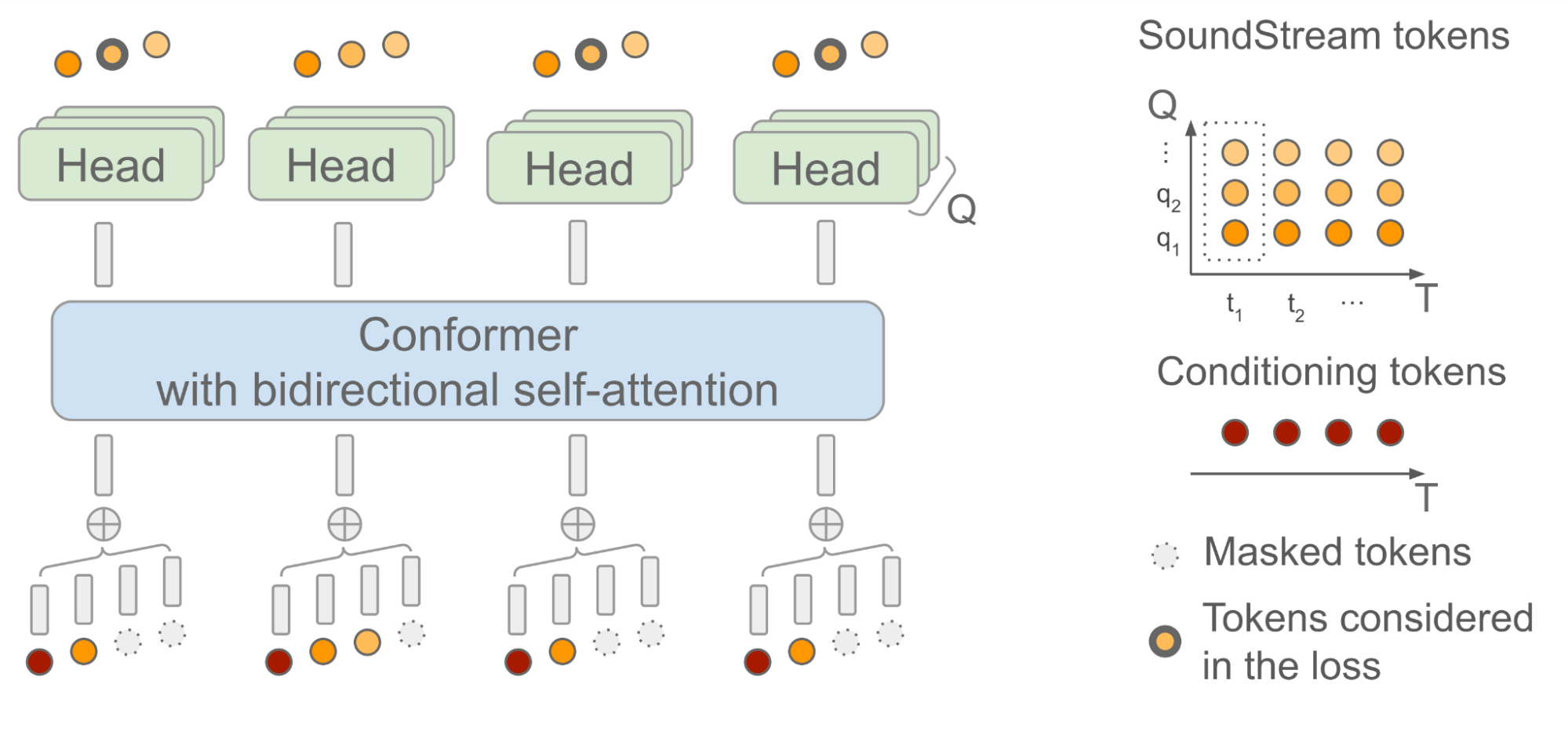 |
| SoundStormモデルアーキテクチャ。Tは時間ステップの数であり、QはSoundStreamが使用するRVQレベルの数です。調整に使用される意味トークンは、SoundStreamフレームと時間に揃えられています。 |
SoundStormの性能の測定
我々は、SoundStormがAudioLMの音響生成器の品質に匹敵し、AudioLMの段階2(粗い音響モデル)および段階3(細かい音響モデル)の両方を置き換えることを示します。さらに、SoundStormは、一致する品質とスピーカーのアイデンティティや音響条件の改善された一貫性に対して、AudioLMの階層的自己回帰音響生成器(下半分)よりも100倍速くオーディオを生成します(上半分)。
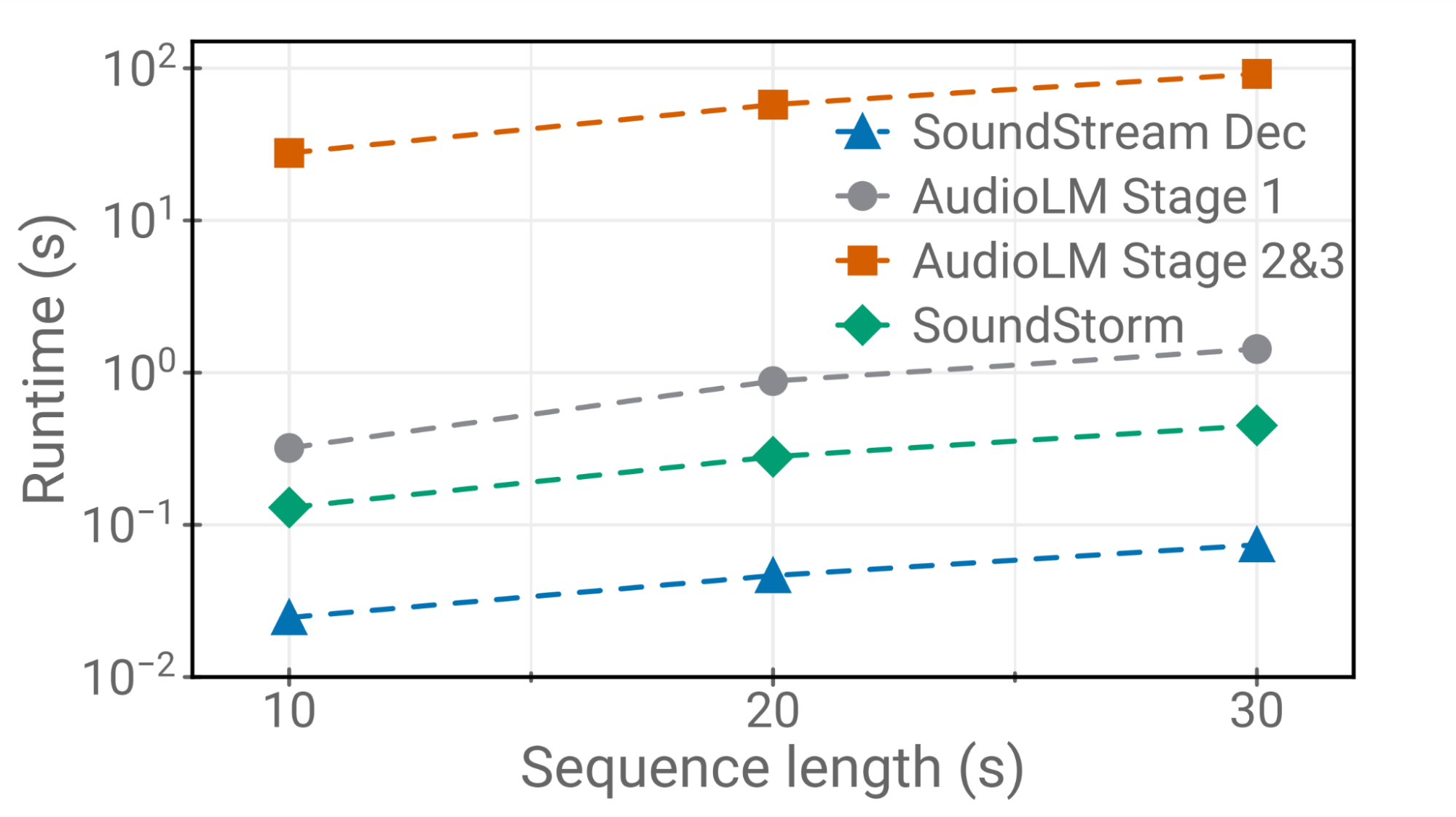 |
| TPU-v4上でのSoundStreamデコード、SoundStormおよびAudioLMの異なる段階のランタイム。 |
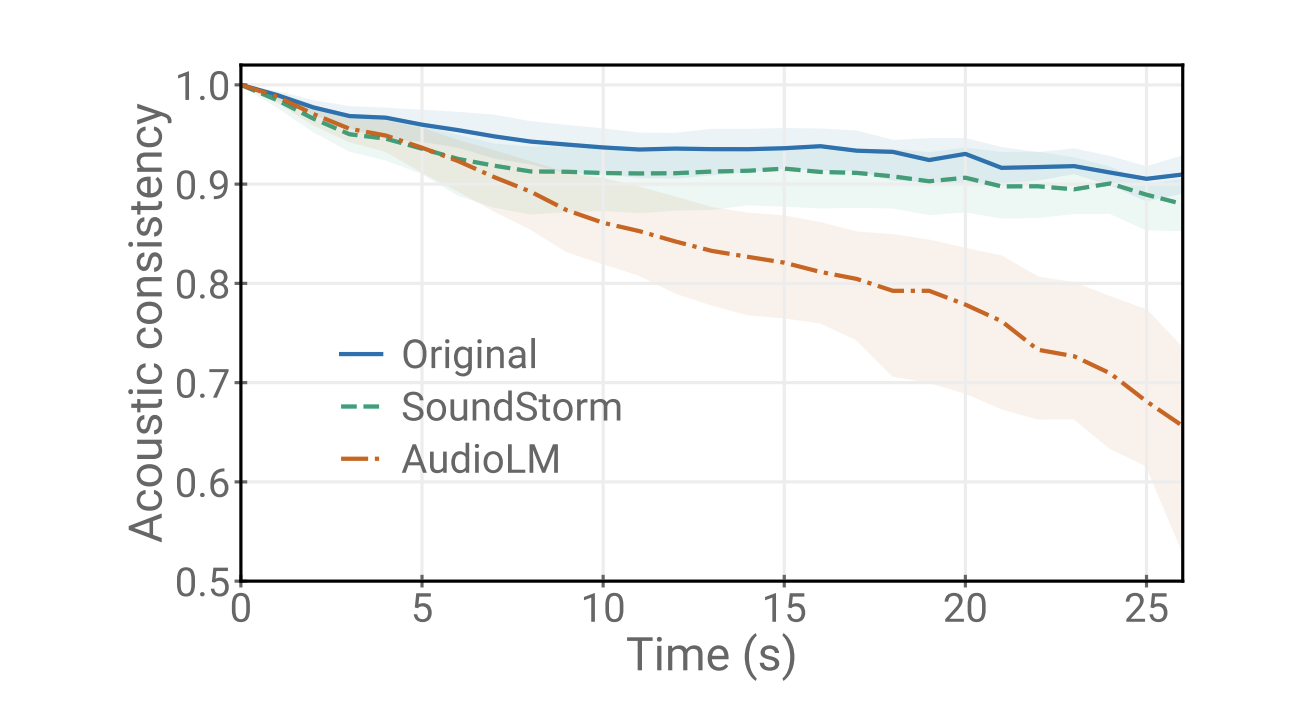 |
| プロンプトと生成されたオーディオの音響的一貫性。影の範囲は四分位範囲を表します。 |
安全性とリスクの軽減
我々は、モデルによって生成されたオーディオサンプルが、例えば表現されたアクセントや声の特徴など、トレーニングデータに存在する不公平なバイアスの影響を受ける可能性があることを認識しています。我々は生成されたサンプルにおいて、不公平なバイアスを回避するために、プロンプトを介してスピーカーの特徴を信頼性の高い方法で制御できることを示しています。トレーニングデータの徹底的な分析とその限界に関する研究は、我々の責任あるAIの原則に沿った将来の研究の一分野です。
一方で、声を模倣できる能力には、生体認証を回避することや、なりすましの目的でモデルを使用することなど、悪意のある多数のアプリケーションがあります。したがって、潜在的な誤用に対する保護策を設けることが重要です。このため、我々は、SoundStormによって生成されたオーディオが、私たちのオリジナルのAudioLM論文で説明した同じ分類器を使用して検出可能であることを検証しました。そのため、より大きなシステムの構成要素として、SoundStormが私たちの先行論文で議論されたリスクに追加のリスクを導入することはないと考えています。同時に、AudioLMのメモリと計算要件を緩和することで、オーディオ生成の分野での研究がより広くのコミュニティでアクセス可能になると考えています。将来的には、音声の透かしを利用して合成音声を検出する他のアプローチを探求し、この技術の潜在的な製品利用が私たちの責任あるAIの原則に厳密に従うようにする予定です。
結論
我々は、離散的なコンディショニングトークンから高品質のオーディオを効率的に合成できるモデルであるSoundStormを紹介しました。 AudioLMの音響ジェネレーターと比較して、SoundStormは2桁高速で、長時間のオーディオサンプルを生成する際により高い時間的一貫性を実現しています。 SPEAR-TTSに似たテキスト-意味トークンモデルをSoundStormと組み合わせることで、より長い文脈でのテキストから音声合成をスケールし、複数のスピーカーターンを備えた自然な対話を生成し、スピーカーの声と生成されたコンテンツの両方を制御できます。 SoundStormは、音声の生成に限定されるものではありません。例えば、MusicLMは、SoundStormを使用して、より長い出力を効率的に合成します(I/Oで確認できます)。
謝辞
この論文の著者は、Zalán Borsos、Matt Sharifi、Damien Vincent、Eugene Kharitonov、Neil Zeghidour、Marco Tagliasacchiです。Googleの同僚から受けたすべての議論とフィードバックに感謝します。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






